Overview
大语言模型的训练流程大体是(llama 3)
逐渐补充
- Pre-Training
- Data
- 数据收集
- 数据清洗
- 去重 — URL去重,document去重(MinHash),line去重(每30M的documents搜索去重)
- 过滤(Heuristic(n-gram 过滤,危险词过滤,KL散度过滤,Model-based分类, 特定数据抽取)
- 数据混合
- 数据配比
- 分类采样
- scaling law(小规模模型实验预测大模型)
- (退火数据)
- 高质量数据的再次训练,优化benchmark表现
- 大规模提升不大
- 数据配比
- Model Architecture
- Dense / MoE
- Layers, Model dimension, GQA(Attention heads, key/value heads), learning rate, Positional Embeddings
- Infra
- GPU
- 存储 — checking point
- 网络 — (网络拓扑,带宽)
- Training Recipe
- Initial pre-training — 短上下文,规模逐渐增加
- long context pre-training — 引入长上下文能力
- 退火
- Data
- Post-Training
- LLama 3 (SFT, Reject Sample, DPO)
- Reward Model
- SFT
- RS
- PPO, DPO
- RLHF
- Inference
- Parallelism
- Quantization
Intro
训练的主要阶段
-
预训练阶段(Pre-Training)
- 大量数据,简单算法,让模型预测next token
-
后训练阶段(Post-Training)
- 小规模数据,复杂算法,特定任务
- 任务:instruction following(指令遵循), align with human preferences(对齐人类偏好), code, math
- 算法:RLHF, DPO, SFT
-
基本的benchmark
Pre-Train
Data
Web Data Curation
数据主要是爬到的各种网络数据
去重和过滤尤为关键
1. PII and safety filtering
PII: personally identifiable information 个人信息(身份信息,隐私信息等)
难以确定是否是PII信息,大概过滤不全
成人内容:大概过滤不全
llama 好像有被用于成人内容的灰色产业
2. Text extraction and cleaning
文本提取和清洗,主要是指网络数据大多是爬下来的HTML,会有很多边栏,广告之类的信息,将有用的文本提取出来
llama构建了一个parser来解析文档
同时llama 发现,markdown数据对模型训练有害,将markdown从数据中去除。
但是大多数模型/包括llama3,输出都使用markdown格式,对markdown格式的输入也比较友好,不知道llama3的具体做法
3. De-duplication
去重
llama3使用三个级别去重
- URL
- 保留URL最新的页面
- document
- 使用global MinHash 去重
- line level
- 每30M的documents进行搜索,去除超过6次的文本行
MinHash 是一个常用的方法
4. Heuristic filtering
启发式过滤
- n-gram 如果n比较长,重复较多,去除
- 危险词 — dirty word
- KL divergence(KL 散度) 过滤与其它文档相差过大的(奇怪)文档
5. Model-based quality filtering
基于模型进行分类(例如fasttext, llama2)训练的Roberta-based classifiers
可以区分高低质量,也可以打tag便于选择配比
6. Code and reasoning data and Multilingual data
一些特定数据的抽取
Data Mix
数据混合
大模型时代,训练更接近于炼丹(李沐)
llama3提到的混合方法主要是
- Knowledge classification
- 知识分类,按照常识进行配比 (娱乐内容减少,知识类增加之类的)
- Scaling law
- Llama 将scaling law做了一个拆解,原本scaling law用于预测模型规模与next token loss的关系,但是我们更关心benchmark上的表现
- 我的理解是,分成两部分进行预测,一部分是正常的scaling law预测next token,一个是使用这个loss建立与下游任务的映射(这样能用上之前的实验)
- scaling law 的实验依赖于模型架构,下游任务大概与模型架构无关,不同benchmark不同曲线
Scaling Law 👈并不是很懂
退火数据
在少量高质量数据种进行学习率的退火,能够增强模型再bench mark上的表现
先提高学习率,使用高质量数据继续训练,同时学习率慢慢降低
Llama 3在预训练的最后40Mtoken采取了将LR(learning rate)线性退火到0的方法,同时配合数据配比的调整
对小规模模型效果很好,但是对405B的模型没有什么效果,可能大规模参数的模型不需要这样的方法来提升性能
退火还可以用来评估domain-specific 数据的质量,效率高于scaling law
Model Architecture
参考的整理从 基本过程开始到KVcache再到llama3新使用的GQA
同时补充一些位置编码的内容
基本推理过程
从输入到输出,大体流程是:
- 使用tokenizer进行encoding
- tokenizer 将输入的序列按某一划分标准(word-based, character-based, subword, sentence)进行划分,然后根据词表(vocabulary)将token转化为token id(integer),整个流程称为encoding。
- 这里不同厂商使用的tokenizer不同,切分的效果不同
- 一种观点是,tokenizer切分token的方式决定了模型接受的输入,有的切分方式可能并不一定产生有意义的token,可能会影响模型表现 (例如对数字的切分)
- embedding
- 将每个token转换为一个embedding vector
- 得到一个embedding matrix
- 这时会加入positional embedding
- 进入模型的各个transformer block
- 注意力层加FFN层
- 每一层的最终输出都与embedding矩阵形状相同
- 经过一个language model head
- 将每个embedding映射成与词表大小一致的向量,
- linear transform + softmax
- 得到next token的概率分布
- 最后根据采样策略(greedy, top-k, top-p)采样
- 得到的结果加入到输入序列,进行下一步生成,称自回归
如果是Instruct模型,一般会加入一些special token,产生一个对话模板 system, user, assistant
来自Ollama的llama3 template
{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>
KV Cache
在推理过程,计算next token时,L个Transformer block的中间结果需要被重复利用
将Key, Value缓存起来加速推理
如果没有KV Cache,每一次注意力的计算都需要计算到目前为止所有token的QKV矩阵,进行矩阵运算
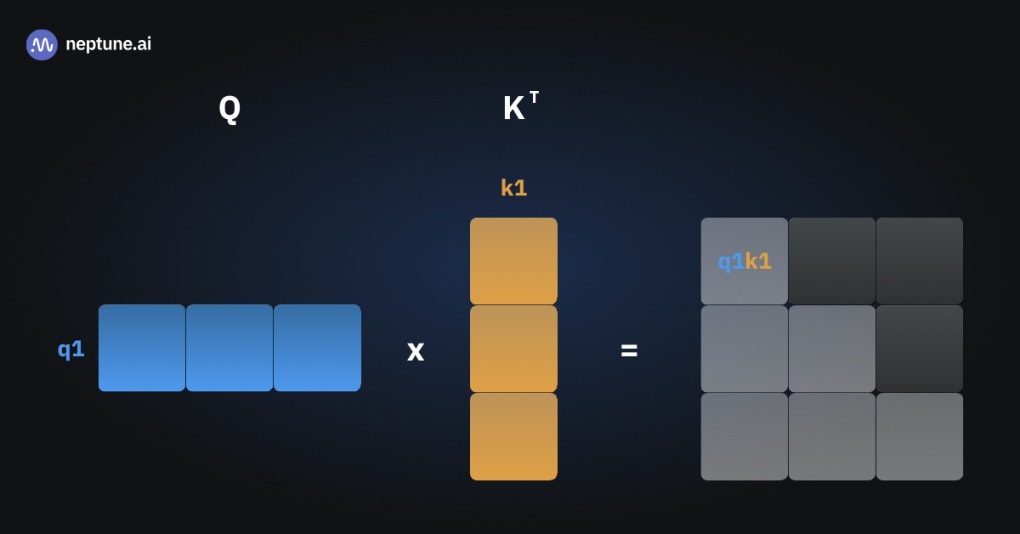
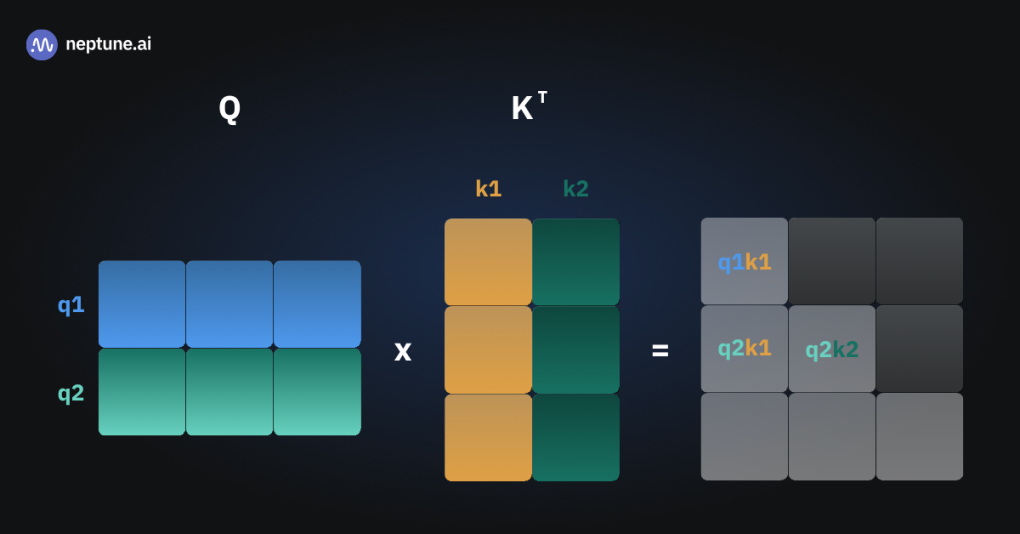
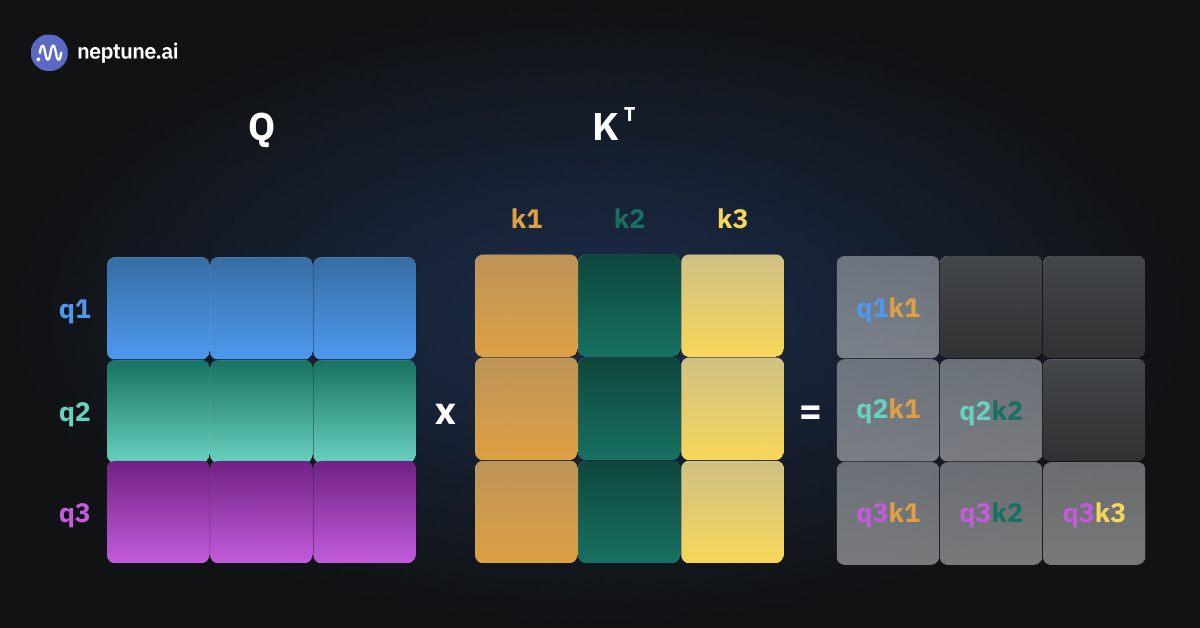
三张图片表示三次推理,可以看到有多次的重复运算
如果能够将中间过程的状态缓存起来,那每一次就只需要计算新token的Key 和 Value,与缓存的K,V连接,就能计算所需的注意力矩阵
RoPE
Positional Embedding
现有的位置编码技术有很多,主流的还是RoPE,不过可能会有各种变形
Training Recipe
Llama3 的预训练在刚开始写这份梳理的时候应当还是开源领域的前沿,但是现在看来有一定的孱弱(相比于Deepseek v3),但是其简单性可能也更易于学习
Llama 3 的预训练策略主要由三步构成,分别为
- Initial pre-trianing
- Long-context pre-training
- annealing(退火)
Llama 进行了packing,将多条短的sequence拼成一条,省去了一些padding token。但是这样可能会产生不必要的注意力(不同文档之间),需要进行额外的attention mask
pre: Tokenizer
Initial Pre-Training
Llama 3(405B)使用AdamW作为optimizer,peak learning rate为8e-5,linear warm up 8000步,cos下降到8e-7(1200000步)
Llama 3 在初期使用了较小的batch size,并逐渐加倍训练。Initial batch size 为 4M,序列长度为4096,训练252M token后将这些值加倍,8M batch size 和 8192 序列长度,训练2.87Ttoken后,batch size 加倍,序列长度仍为8192
报告说这样的训练十分稳定,Llama 3观察到的损失峰值(loss spikes)很少,并且不需要进行干预来纠正模型训练的偏差。
Llama3(405B)的上下文长度为 128k,但在预训练的时候只有 8k,后续的上下文能力是在初步预训练之后再加入的
Long Context Pre-Training
在预训练的最后阶段,对long sequences 进行训练,以支持128k上下文的目标
初步增加context length进行训练,直到模型成功适应了128k的context length
判断是否适应:模型在short-context evaluation的表现是否完全恢复;模型是否能完美完成对应长度的 needle in a haystack(大海捞针)任务
这个阶段大概使用了 0.8T tokens
Annealing
退火,见上文
并不是所有模型都有这一步,405B模型也表明这一步意义不大。为了在benchmark 上表现得更好,有点过拟合的嫌疑
Post-Training
后训练
后训练不同模型差别应该会比较大,策略包括RLHF, SFT, DPO, RS等
Llama 3 的post-training
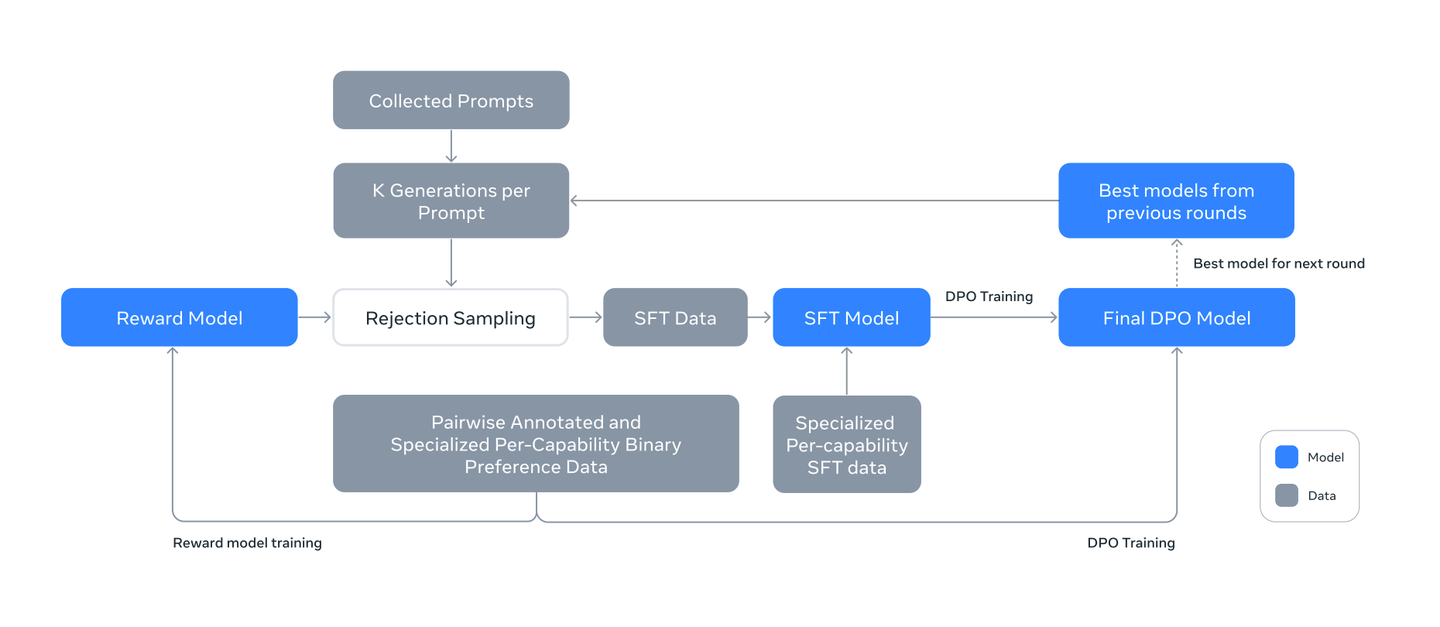
Llama3 采用较简单的后训练方法,主要包括 SFT, RS,DPO
Llama3 的后训练策略是:使用人类标注的偏好数据,在Pre-trained checkpoint上训练一个Reward Model(RM),然后对pre-trained checkpoint 做 SFT,再用 DPO 对齐,作为本轮的最佳模型,进入下轮迭代,参与到 Rejection Sampling(RS) 中。
backbone是RM和LM
Llama进行了6轮循环,每一次迭代收集新的偏好数据和SFT数据,并从最新的模型中采样合成数据
Reward Model
Reward Model 是根据 Preference DAta 进行训练得到的评估模型,能够给样本一个偏好性分数。分数表示一种人类喜好
其中两个样本之间不仅有A好于B,可能是远好于,稍好于。
Preference Data
构造Preference Data 大概分为以下几个step
- 使用不同的数据配比和训练策略训练出多个for annotation的模型,针对一个具体的user prompt采样出两个不同模型的response
- 标注同学按照好多少的标准进行打分,四个等级:significantly better, better, slightly better, or marginally better
- 标注后,鼓励标注同学edit chosen response,既可以直接修改chosen response,也可以修改prompt来refine数据
最后有一些数据是有三个 ranked response,edited > chosen > rejected
而在使用数据时,需要通过实验优化细节(preference pari的构造)。
训练
Llama2 的loss
- 为正样本, 为负样本
- 为评分函数
- 为margin loss,控制正样本得分高于负样本一定距离
Llama3中发现数据规模增大,margin loss作用不大,所以损失函数中简化掉了
Rejection Sampling
固定模型和prompt,从LM采样出K个不同答案,假设RM的评分拟合了正确分布,通过RM的评分选择最优的答案作为SFT数据。
LM是上一轮训练中表现最好的checkpoint
K一般为10-30
为了提高拒绝采样的效率,Llama3 采用了 PagedAttention
加餐? Flash Attention
SFT
SFT(Supervised Fine-Tuning) 监督微调
Supervised fine-tuning (SFT) is a technique used to adapt a pre-trained (base) Large Language Model (LLM) to a specific downstream task using labeled data KLU-Supervised fine-tuning (SFT)
虽然预训练模型拥有了相当的语言能力,但是预训练模型是不具备完成下游任务能力(如问答)的。一般需要通过后训练对需要的下游能力进行优化。而Supervised Fine-tuning(SFT)是其中最简单的一种方法。
SFT就是使用小规模(相比于预训练)的下游任务标记数据,使用任务对应的损失(task-specific loss)(一般还是next token prediction作为objective),对预训练模型进行再训练。
经常进行的SFT是指令微调(fine-tuned for chat or instruction-based interactions)
通过SFT将预训练模型训练为指令遵循模型一般需要数万个样例

在LLM训练过程中,SFT常与RLHF一起进行
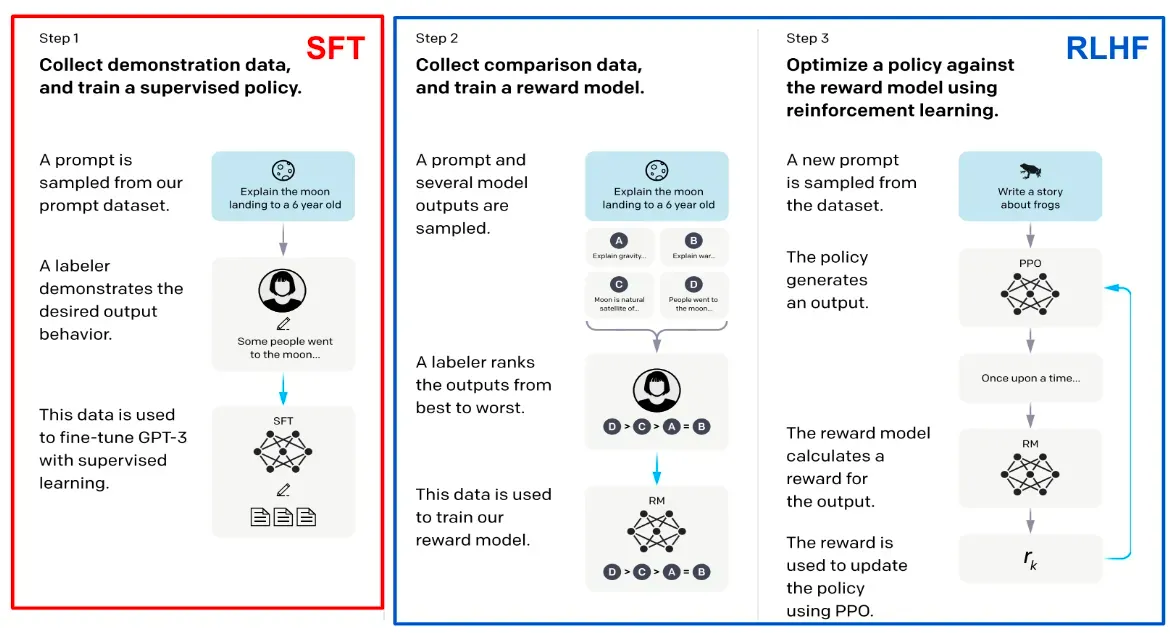
通过人类/模型得到高质量数据进行训练为SFT,人类参与训练Reward Model,通过强化学习方法训练为RLHF(Reinforce learning from human feedback)
about alignment
对齐是指,将模型的表现对齐到人类偏好上。
偏好可能包含多个指标(criteria)
常见的对齐指标(alignment criteria)有:improving instruction following capabilities, discouraging harmful output, making the LLM more helpful…
进一步的,对于对齐后的模型,SFT可以用于强化模型针对特定下游任务的能力(通常会损失其它一些通用能力)。此时常用的方法有LoRA(Low-Rank Adaptation), QLoRA(Quantized LoRA)等PEFT(parameter Efficient Fine-Tuning)技术
SFT 数据来自 RS数据,针对特定能力的合成数据,少量的人工标注数据。
Direct Preference Optimization(DPO)
pre:Reinforcement Learning,Procimal Policy Optimization(PPO)
详细: Direct Preference Optimization(DPO)
加餐: GRPO