Overview
Supervised fine-tuning (SFT) is a technique used to adapt a pre-trained (base) Large Language Model (LLM) to a specific downstream task using labeled data KLU-Supervised fine-tuning (SFT)
虽然预训练模型拥有了相当的语言能力,但是预训练模型是不具备完成下游任务能力(如问答)的。一般需要通过后训练对需要的下游能力进行优化。而Supervised Fine-tuning(SFT)是其中最简单的一种方法。
SFT就是使用小规模(相比于预训练)的下游任务标记数据,使用任务对应的损失(task-specific loss)(一般还是next token prediction作为objective),对预训练模型进行再训练。
经常进行的SFT是指令微调(fine-tuned for chat or instruction-based interactions)
通过SFT将预训练模型训练为指令遵循模型一般需要数万个样例

在LLM训练过程中,SFT常与RLHF一起进行
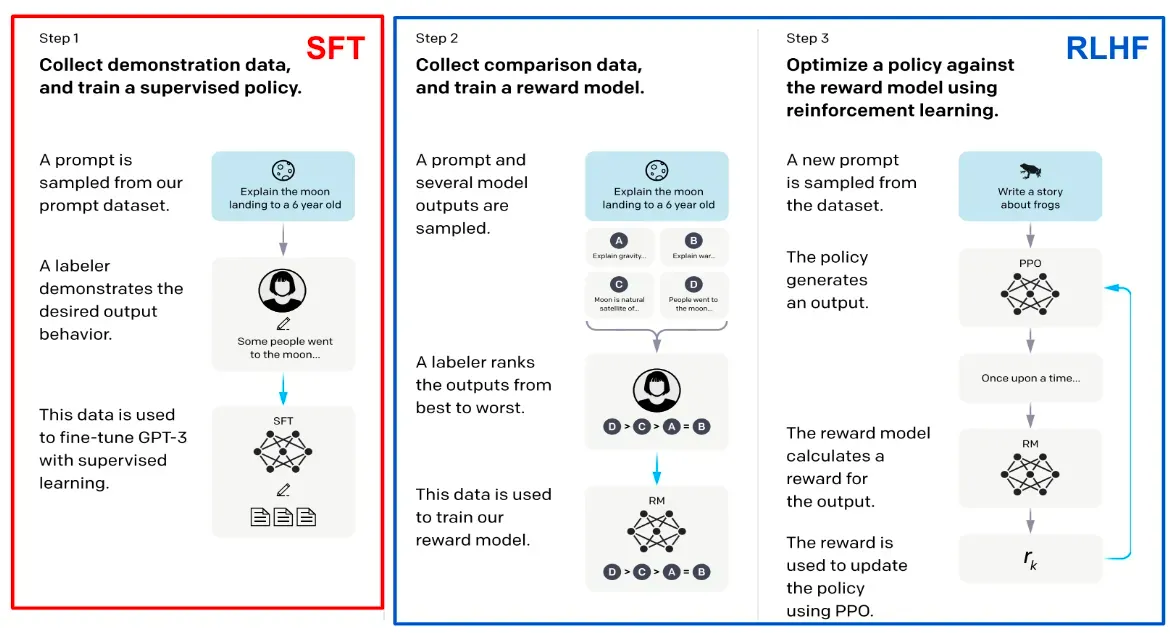
通过人类/模型得到高质量数据进行训练为SFT,人类参与训练Reward Model,通过强化学习方法训练为RLHF(Reinforce learning from human feedback)
about alignment
对齐是指,将模型的表现对齐到人类偏好上。
偏好可能包含多个指标(criteria)
常见的对齐指标(alignment criteria)有:improving instruction following capabilities, discouraging harmful output, making the LLM more helpful…
进一步的,对于对齐后的模型,SFT可以用于强化模型针对特定下游任务的能力(通常会损失其它一些通用能力)。此时常用的方法有LoRA(Low-Rank Adaptation), QLoRA(Quantized LoRA)等PEFT(parameter Efficient Fine-Tuning)技术
Pros and Cons of SFT
Pros:
- Simple: 和pre-training的训练差别不大
- Effective
- computationally cheap: 与预训练相比
Cons
It’s hard to creating a perfect dataset:
SFT的效果取决于数据集,无论是通过人工获得还是通过模型自动生成,得到一个全面且高质量的数据集都不容易。
人工获得数据集,虽然可以保证数据集质量,但是数据集规模受限(not scalable),成本变高
通过自动化框架(利用模型),成本较低,规模大,但质量较难保证(实际上随着LLM发展应该会改善)
RLHF is beneficial:
对于后训练来说,单独使用SFT是不够的。
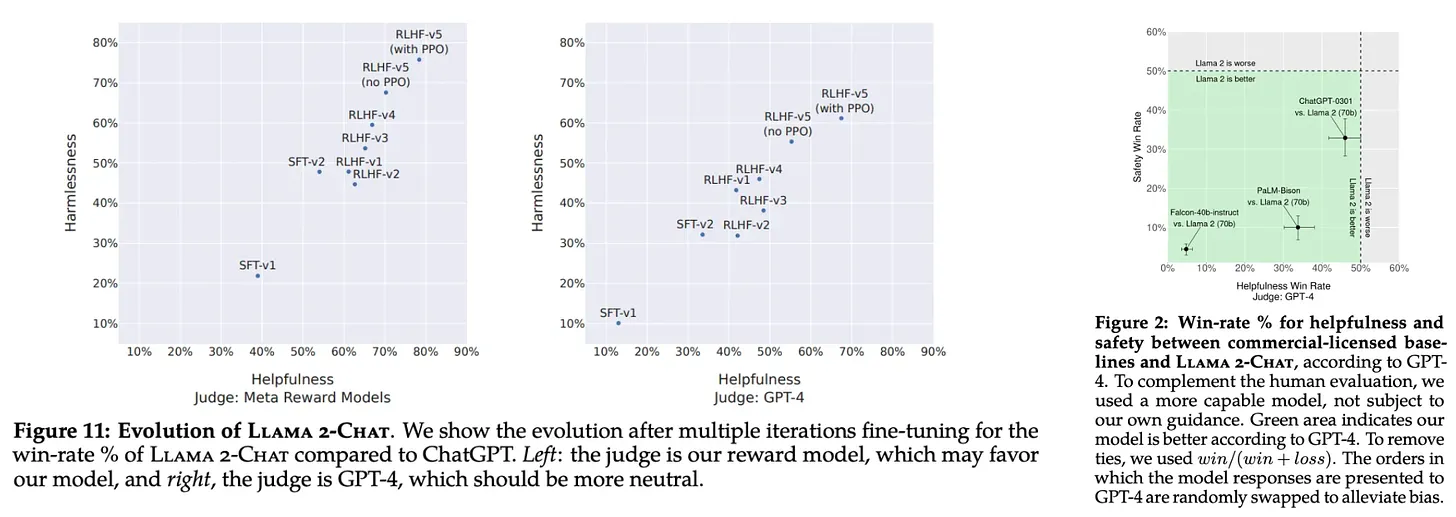
Llama2的报告指出,i) RLHF能带来很大的好处,ii) SFT的数据集和训练到达一定程度的时候,模型的输出已经能与高质量数据集相比,即更多的投入收益甚微,应该将精力放在RLHF上
并不是所有的模型都使用SFT+RLHF进行后训练
In Practice
使用transformers库中的Trainer
- model, load with
AutoModelWithLMHead.from_pretrained - Training args
- train dataset and an evaluation dataset
- Data collator
- data collator 对数据集进行一些transformations
- 包括但不限于 padding, formatting(规范格式), masking(特定任务加掩码), Efficient batching
from transformers import Trainer, TrainingArguments, AutoModelWithLMHead, TextDataset, DataCollatorForLanguageModeling
model = AutoModelWithLMHead.from_pretrained("model")
training_args = TrainingArguments(
output_dir="./outputs", #The output directory
overwrite_output_dir=True, #overwrite the content of the output directory
num_train_epochs=3, #number of training epochs
per_device_train_batch_size=32, #batch size for training
per_device_eval_batch_size=64, #batch size for evaluation
eval_steps 400, #Number of update steps between two evaluations.
save_steps=800, #after steps model is saved
warmup_steps=500, #number of warmup steps for learning rate scheduler
)
tokenizer = AutoTokenizer.from_pretrained("<YOUR_MODEL>")
train_path ="<TRAINING_DATASET_PATH>"
test_path ="<TEST_DATASET_PATH>"
def load_dataset(train_path,test_path,tokenizer):
train_dataset TextDataset(
tokenizer=tokenizer,
file_path=train_path,
block_size=128)
test_dataset TextDataset(
tokenizer=tokenizer,
file_path=test_path,
block_size=128)
data_collator DataCollatorForLanguageModeling(
tokenizerstokenizer,mlm=False,
)
return train_dataset,test_dataset,data_collator
train_dataset,test_dataset,data_collator = load_dataset(train_path,test_path,tokenizer)
trainer = Tratner(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)使用trl库
from transformers import AutoModelForCausalLM
from datasets import load_dataset # could be dataset loader implemented by yourself
from trl import SFTTrainer
model = AutoModelForCausalLM.from_pretrained("your model")
trainer = SFTTrainer(
model,
train_dataset=train_dataset,
evaluation_dataset=evaluation_dataset,
data_collator=collator
)
trainer.train()SFTTrainer 继承了Trainer,进行了一些SFT的封装,如 i)支持peft, ii) 支持packing