Basically the same as Paged Attention and vLLM | Continuum Labs 👈强推
Preliminaries
PagedAttention is proposed to deal with the KV cache problem in high-throughput scenarios
Some background knowledge is needed.
Serving LLMs is computationally expensive, due to the large number of hardware accelerators and infra that needed. To reduce the cost per request, we have to increase the throughput of LLM serving systems
We achieved that by batching multiple requests together
For any request, we use KV cache to store the keys and values associated with the tokens generated so far in a sequence
The KV cache memory grows and shrinks dynamically and we don’t know its lifetime and length util the sequence complete.
Existing LLM serving system allocate contiguous memory for the KV cache based on the maximum sequence length
And these two could cause some issues
Memory fragmentation
- Internal fragmentation 内部碎片
- The actual sequence length is shorter than the allocated length, resulting in wasted memory
- External fragmentation 外部碎片
- The requests have different maximum length, memory that allocated by chunks could lead to wasted memory
- Lack of memory sharing
- KV cache for each sequence is stored in separate contiguous memory spaces. It could not share memory across sequences, which could be wasted if they belong to the same request or have overlapping context.
Batching technique issues
- Queueing delays
- Requests may arrive at different time. If eariler request wait for later ones to form a batch, or later one could not engage computation until earlier ones finish. It increased latency
- Inefficient padding
- Request may have different input and output lengths.
- naive batching techniques pad the inputs and outputs to equalise their lengths, wasting GPU computation and memory
For batching issues, fine-gained batching mechanisms like cellular batching and iteration-level scheduling have been proposed.
They operate at the iteration level: after each iteration, completed requests are removed from the batch, and new ones are added. It allows new requests just wait for a single iteration rather than a entire batch.
PagedAttention
PagedAttention divides the KV cache into fixed-size blocks, which can be allocated on-demand and need not be stored in contiguous memory
- reduce internal fragmentation
- eliminates external fragmentation 不要求连续就消除了外部碎片
- enables memory sharing at the block level, both within and across requests
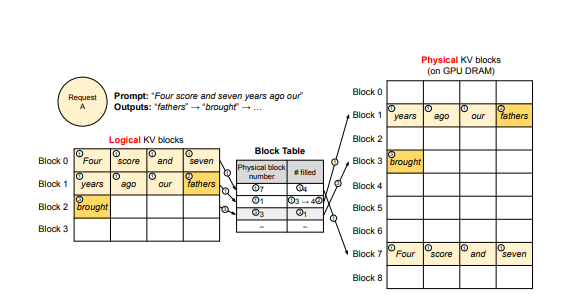
vLLM maintains block tables that map logical KV blocks to physical KV blocks for each request, KV blocks are non-contiguous physical blocks but logically contiguous
Each block contains the key and value vectors for a fixed number of tokens, denoted as the KV block size ()
Each block table entry records the corresponding physical blocks of a logical block and the number of filled positions
Specifically,
PagedAttention divide K V matrix into fixed-size block. and represent the -th block of key and values.
for example, contains key vectors from token index to , ( is the size of block in token units)
PagedAttention compute the attention output in block-wise:
- For each token, the kernel multiplies its query vector with key vectors in a block to compute the attention scores
- Then, the kernel multiplies the attention scores with the value vectors in a block to derive the final attention output
About vLLM
vLLM is an end-to-end LLM serving system.
The system use PagedAttention algorithm as its core, consisting of a FastAPI frontend and a GPU-based inference engine.
The frontend extends the OpenAI API interface.
vLLM is implemented in Python and C++/CUDA
- control-related components developed in Python
- custom CUDA kernels for key operations like PagedAttention
To support PagedAttention, vLLM develops several custom GPU kernels. I am lack of CUDA knowledge now and write them down could not help me if I don’t understand any of them. If I wana learn more one day, see Paged Attention and vLLM | Continuum Labs
vLLM implements various decoding algorithms using three key methods
- fork, create a new sequence from an existing one
- append, appends a new token to the sequence
- free, delete the sequence
These methods are used in decoding algo like parallel sampling, beam search and prefix sharing
Since the abstraction of logical blocks, the execution kernel can work with multiple decoding methods without realize the underlying implementation. Requests that have mixed decoding methods are allowed to batching together.
Parallel Sampling
In some applications, we need to sample multiple response for a single input prompt
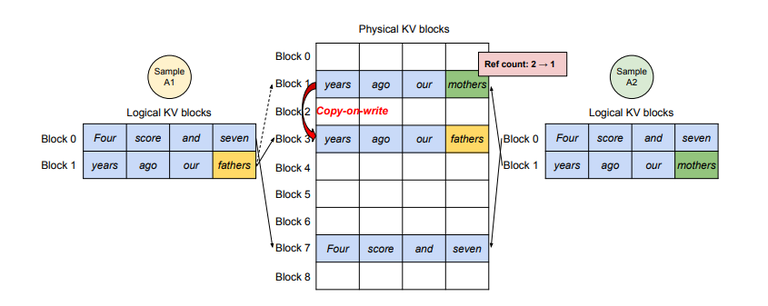
vLLM system use shared physical block for the same input to save memory.
When the block need to be modified with different tokens(during generation), vLLM would copy the data from the original block, update the mapping and append various token’s KV. --- copy-on-write mechanism
This ensures that each sequence has its own copy of the modified block, while still sharing the unchanged blocks
Beam Search
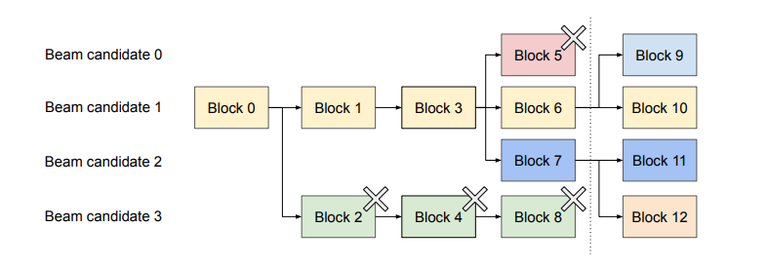
Beam search maintains top-k most probable partial sequences at each step.
vLLM enbles memory sharing for both initial prompt and other blocks across different candidates. As the beam search progresses, the candidates share common blocks and diverge only when necessary.
vLLM uses reference counting mechanism to manage shared block. It count the number of candidates sharing each physical block, and free the block if the number become zero.
About Beam Search
Beam Search 是一种解码策略,每步选择概率最高的k个路径,k称为beam width 束宽
Beam Search 追求概率,比贪心更全面,但计算量大,多样性不足。
大概流程如下:
- 从起始token开始,生成k个最可能的token
- 对每个路径,计算 次概率
- 对所有路径的累积概率,选择前k个最高得分路径
- 直到路径结束或到达最大长度
Shared Prefix
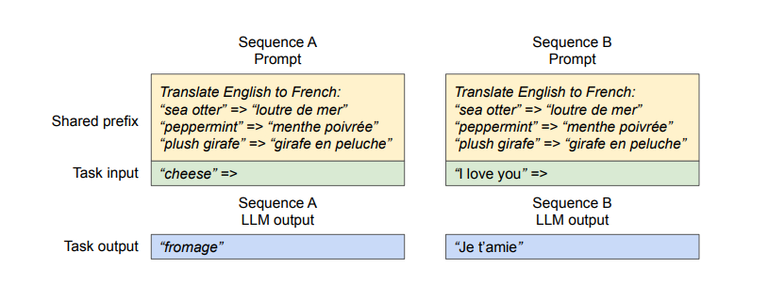
In some applications, like machine translation, multiple input prompts may share a common prefix.
vLLM allows the LLM service provider to store the KV cache of the shared prefix in advance.
When a user input prompt contains a shared prefix, vLLM maps the logical blocks of the prompt to the pre-computed physical blocks, reducing redundant computation.
Supplement
What if the memory run out accidentally with no request finish?
Since we allocate memory dynamically, the awkward scenario could actually happened one day.
vLLM adopt some principle to tackle that situation
- FCFS (Firt-Come-First-Serve)
- preemption 抢占
FCFS means we serve the requests that came first if we have no enough memory to serve them all
And preemption means the requests that came first have higher priority which allow them to occupy the memory that given to other requests.
Specifically, vLLM would pause the last requests to arrive, release their KV cache(all block actually) and let the earlier requests to finish their generations
For those victims, vLLM need restore them later.
vLLM design two strategy to restore the requests:
- Swapping
- In this strategy, the release blocks are swapped into cpu, and will be swapped back when gpu has enough memory
- Recomputation
- Recomputation just release blocks and put the victims back to waiting queue.