Scaling Laws Overview
The loss of next-token prediction is predictable and smooth.
We only need to know two variables to estimate their accuracy: the total number of parameters(N) and the size of text tokens used to train the model(D)
As we train larger models on more data, we continue to see improvements in accuracy
The scaling law also help understading the relation between model quality and model size, training data and computational resources, which has been utilized in LLM pre-training
Additionally, the risk of overfitting is closely related to the ratio of model size to the data size. In OpenAI’s paper, they recommend the equation to avoid overfitting
Empirical Experiments
Given compute budget(measured in FLOPs), what would be the optimal combination of model size and training data size?
核心问题是:给定compute budget,模型大小和数据大小的结合应该是什么样的
Two significant findings
OpenAI scaling laws paper use PF-days(PetaFLOPs-days)
Peta denote a factor of 1e15
24 hours
3600 seconds

In OpenAI’s paper, several experiments have been conducted.
The basic setting is
- Model size(N): 768-1.5 billion non-embedding parameters
- Dataset Size(D): 22 million to 23 billion tokens
- Model shape: depth, width, attention head, feed-forward dimension
- Context Length: 1024
- Test Cross-Entropy Loss(L): measures performance
- Compute(C): Computational resoureces used for training
The experiments are 5 year old, and many changes happened these years. The size of model and dataset are much larger and the Context length is longer(8K in training for llama3). But with the laws revealed by the paper, these experiments provides an insightful perspective over LLM pre-training
Two conclusion were drawn:
- the impact of scale if more significant than model architecture(transformer details)
- the scale refers to parameters(N), dataset(D), Computational resources(C)
- There is power-law relationship between the performance of the model and each of the scaling factors(when they are not constrained by one another)
The power law trend is illustrrated by the first 4 equation
When we scaling up one of these factors, we can expect a corresponding and predictable improvement in the model’s performance, following a power-law trend
Sample-Efficient LLMs
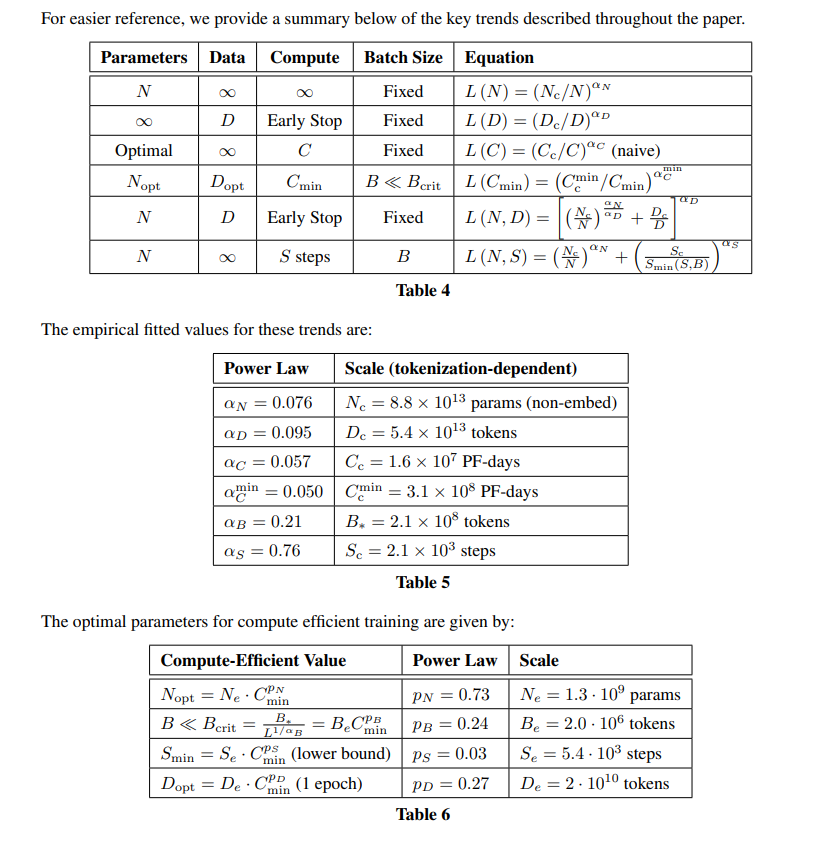
Experiments found that, given tokens processed, larger models achieve lower loss than small models(Larger model is more sample-efficient) 大模型对样本的学习能力更强
 1
1
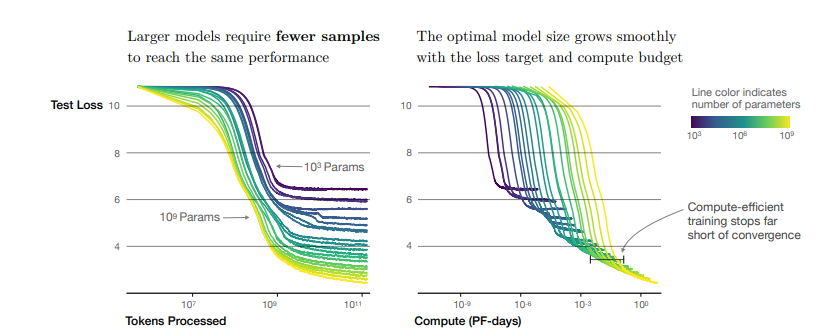
But in Google’s paper, the model size should be scale too(we can achieve the same performance using less parameter)
 2
2
 2
2
谷歌实验的模型规模远大于OpenAI,可能OpenAI的规模不够大导致结论不同
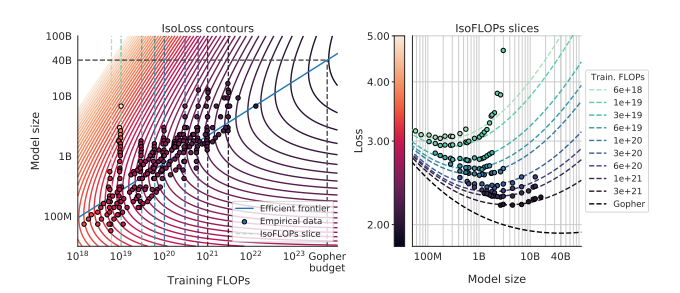
Google’s paper offers a new way of interpretation of LLMs scaling law.
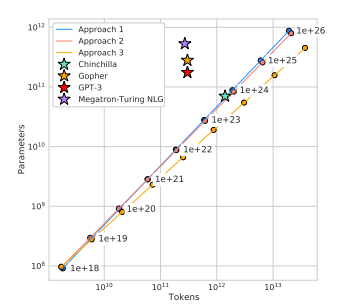
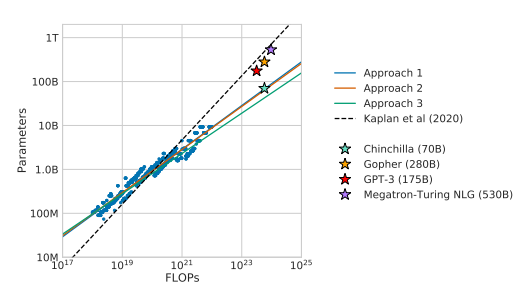
Ploting out IsoLoss contours, we can find the fewest FLOPs in each curve. These points give us the efficient frontier(blue line)
It means that given a compute budget, we can find the optimal model size and predict the loss the model would be
For optimal compute-efficient training, DeepMind suggests to have more than 20 training tokens for every 1 model parameter
Scaling law equation
OpenAI’s scaling law:
DeepMind’s scaling law
Deeper
- Demystify Transformers: A Guide to Scaling Laws | by Yu-Cheng Tsai | Sage Ai | Medium
- [2410.11840] A Hitchhiker’s Guide to Scaling Law Estimation
- 大模型(一): Scaling Laws - OpenAI 提出的科学法则
- 大模型(二): DeepMind 的 Scaling Laws 有什么不同?
很模糊,具体怎么计算和预测不是很清楚,知识量不足,得再回来看看