FROM 【生成式AI時代下的機器學習(2025)】第十講:人工智慧的微創手術 — 淺談 Model Editing - YouTube
什么是模型编辑?大概来讲,是一种给模型植入某些特定知识的方法
Evaluation
一般是三个方面,reliability(是否达成了编辑目标), generalization(泛化), locality(编辑是局部的)
其中generalization定义比较宽泛,有的会要求reverse,portability等泛化
Methods
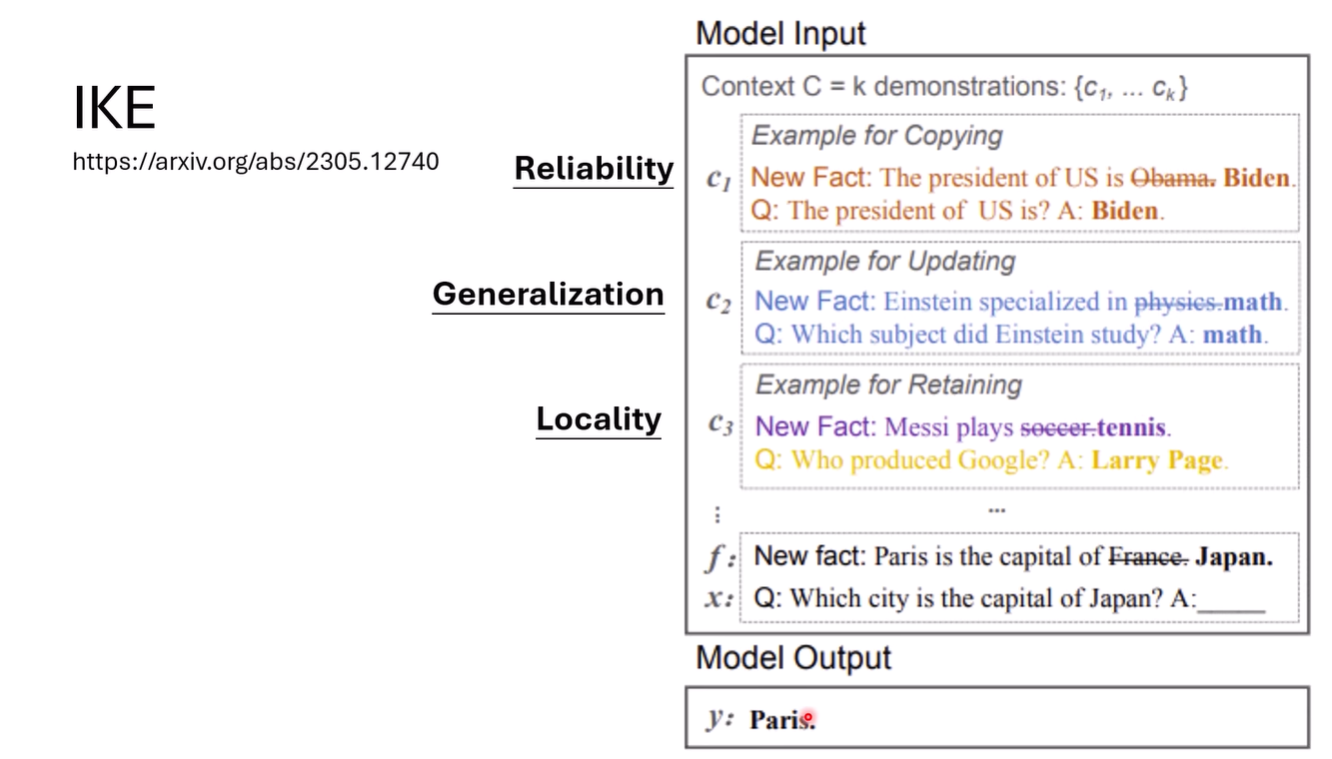
In-context Knowledge Editing(IKE)
不需要改变权重的方法
也就是in-context learning
人类决定进行编辑的参数
Rank-One Model Editing(ROME)
人类找到模型中与需要编辑的知识最相关的部分,然后再去修改这部分参数
如何找出这部分参数呢?可以是控制变量法,掩盖掉关键信息后,通过将正常输入输出的embedding替换到掩盖的流程中,看是那部分的替换产生了正确答案,这部分相关的参数就是需要修改的
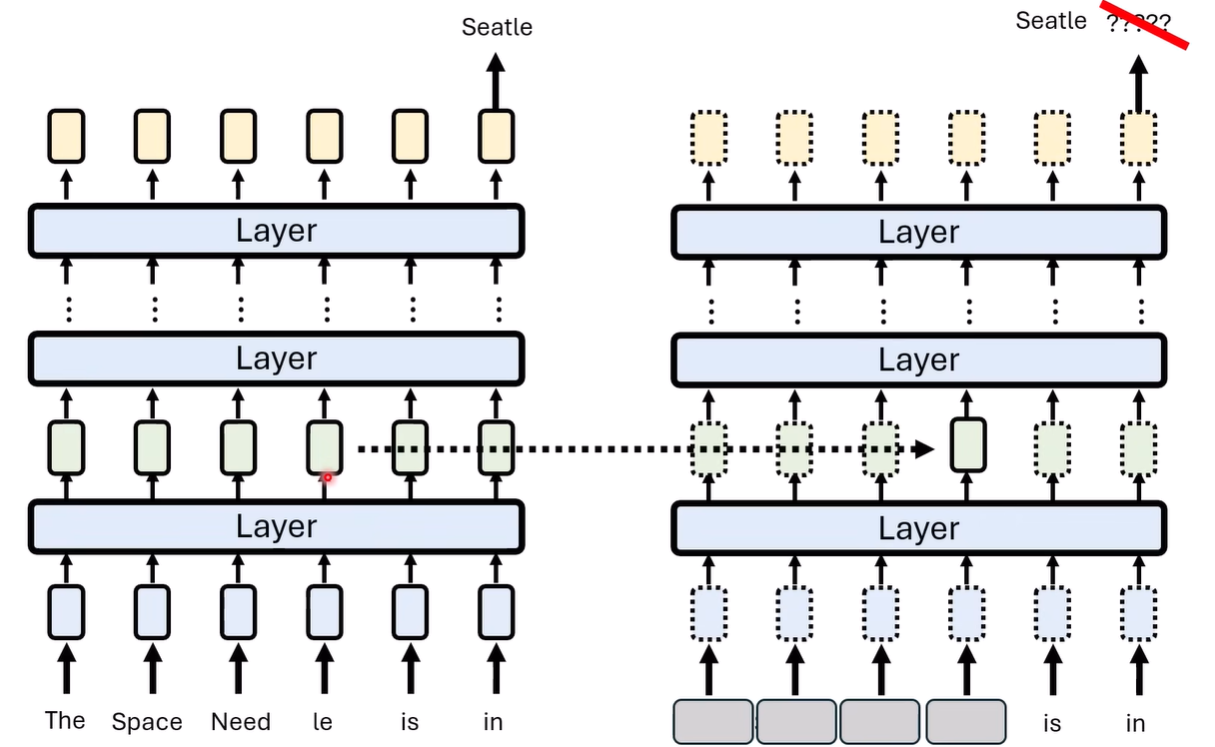
来自论文 [2202.05262] Locating and Editing Factual Associations in GPT
找到之后,我们需要找到一个 加入到residual stream中,找到的方法参考之前的课程
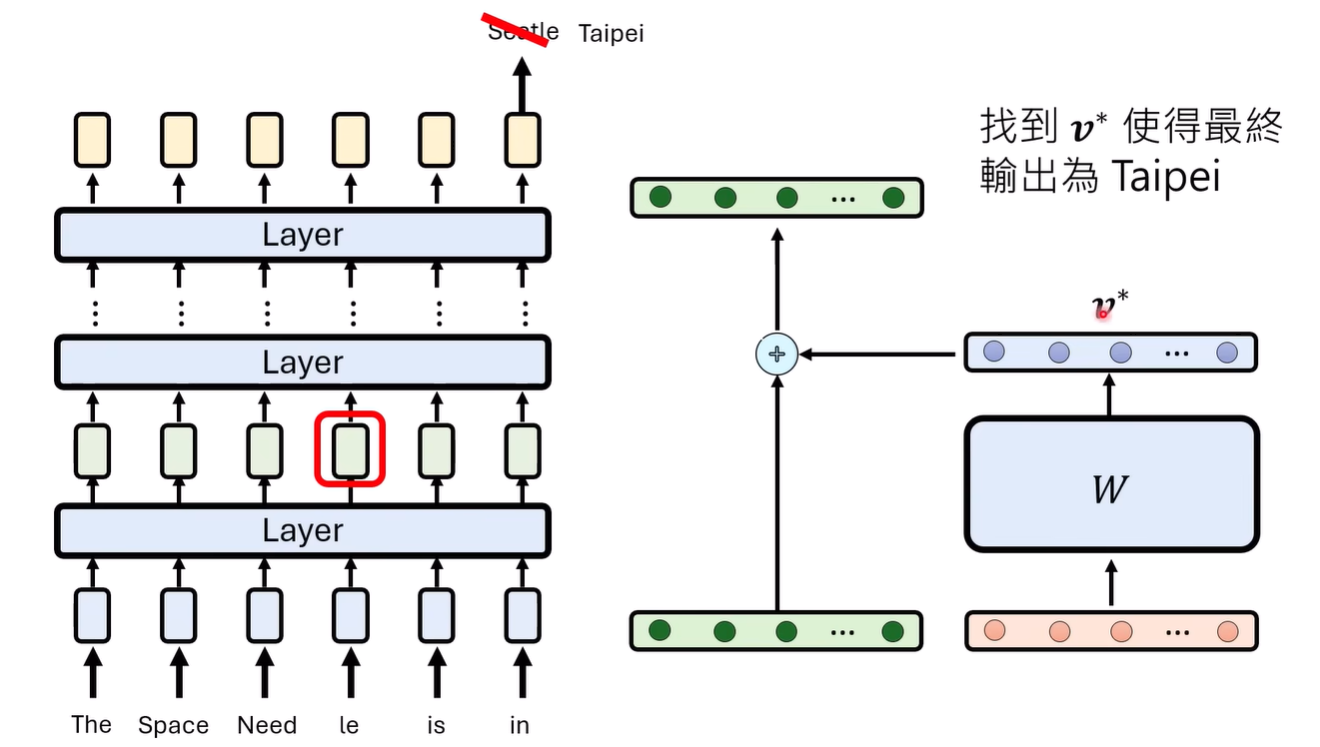
再之后需要进行generalization,locality的优化
generalization的优化需要有同个知识的不同输入,locality则是需要选出需要保留的知识(可能就是随机)对应的n个问答,保证这n个问答由修改的权重与向量相乘带来的变化是尽可能小的
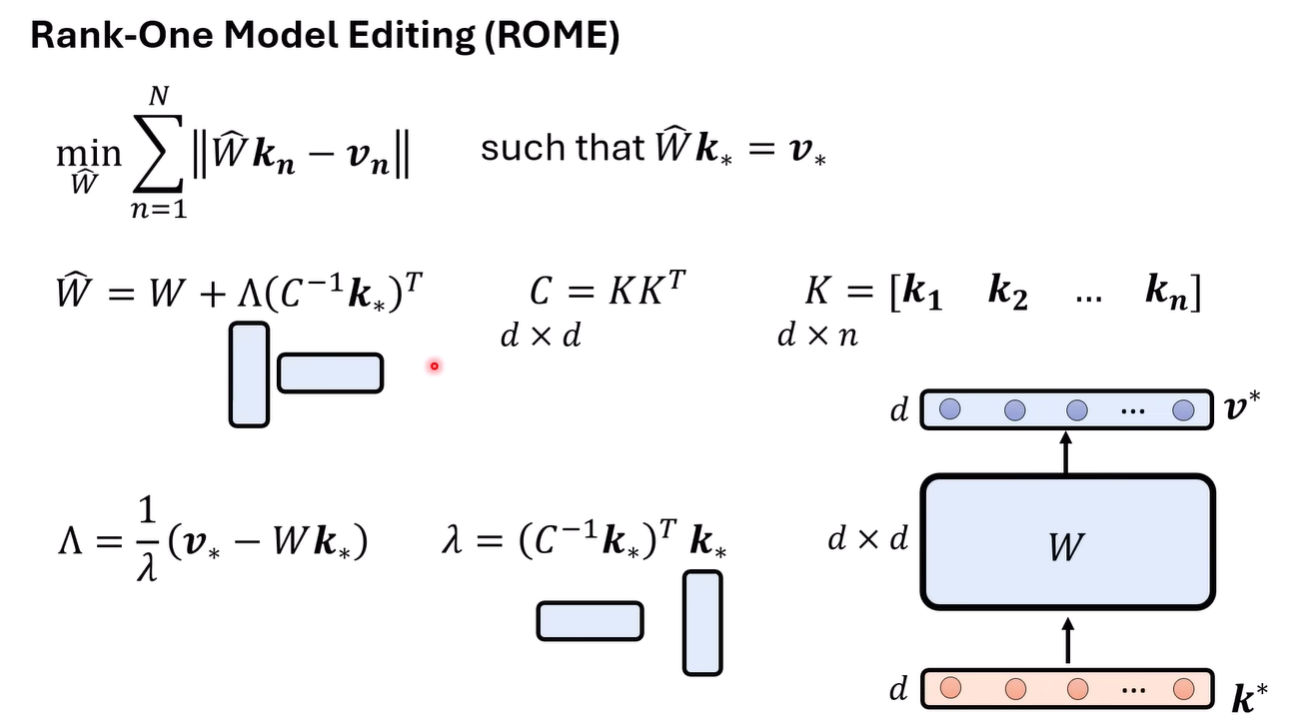
略复杂,但是ROME由close form的解,已经很优雅
模型决定编辑的参数
编辑模型负责生成进行修改的向量(被编辑模型参数量大小),然后期待这个向量加入之后待编辑模型能够被正确的修改
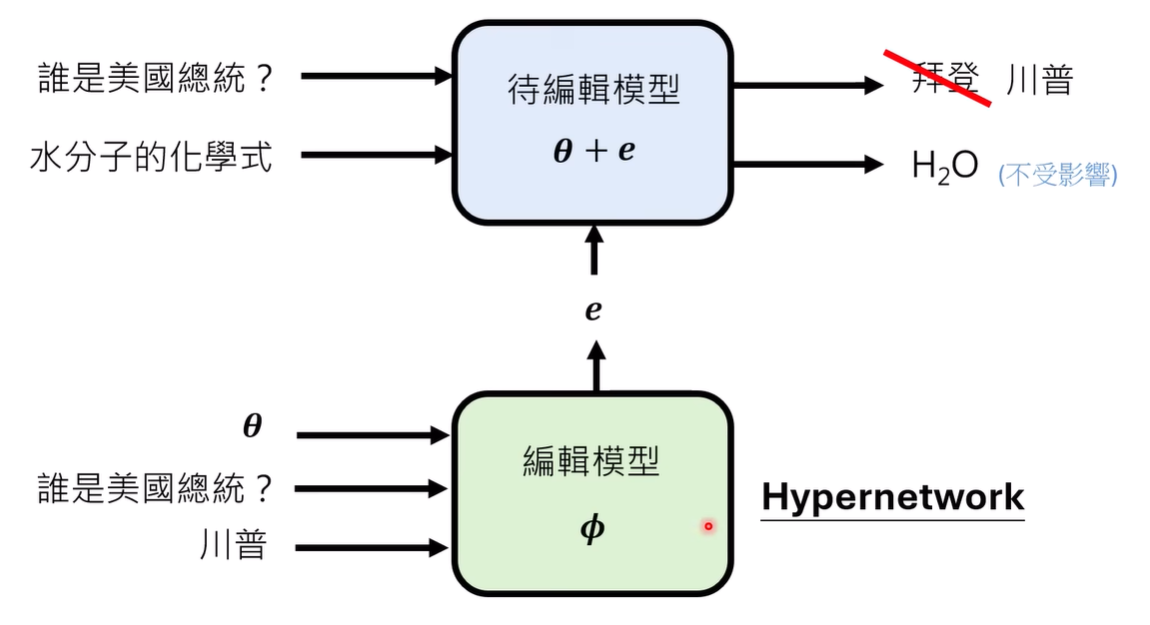
那如何训练hypernetwork?正常来想,需要输入和正确答案(向量)这样的答案对,但是没有这样的数据。一个可行的做法就是利用待编辑模型来获得正确与否的反馈
可以冻结待编辑模型的参数,训练编辑模型,然后二者连接一起训练。训练数据同样考虑generalization和locality,然后分阶段或者混合进行训练
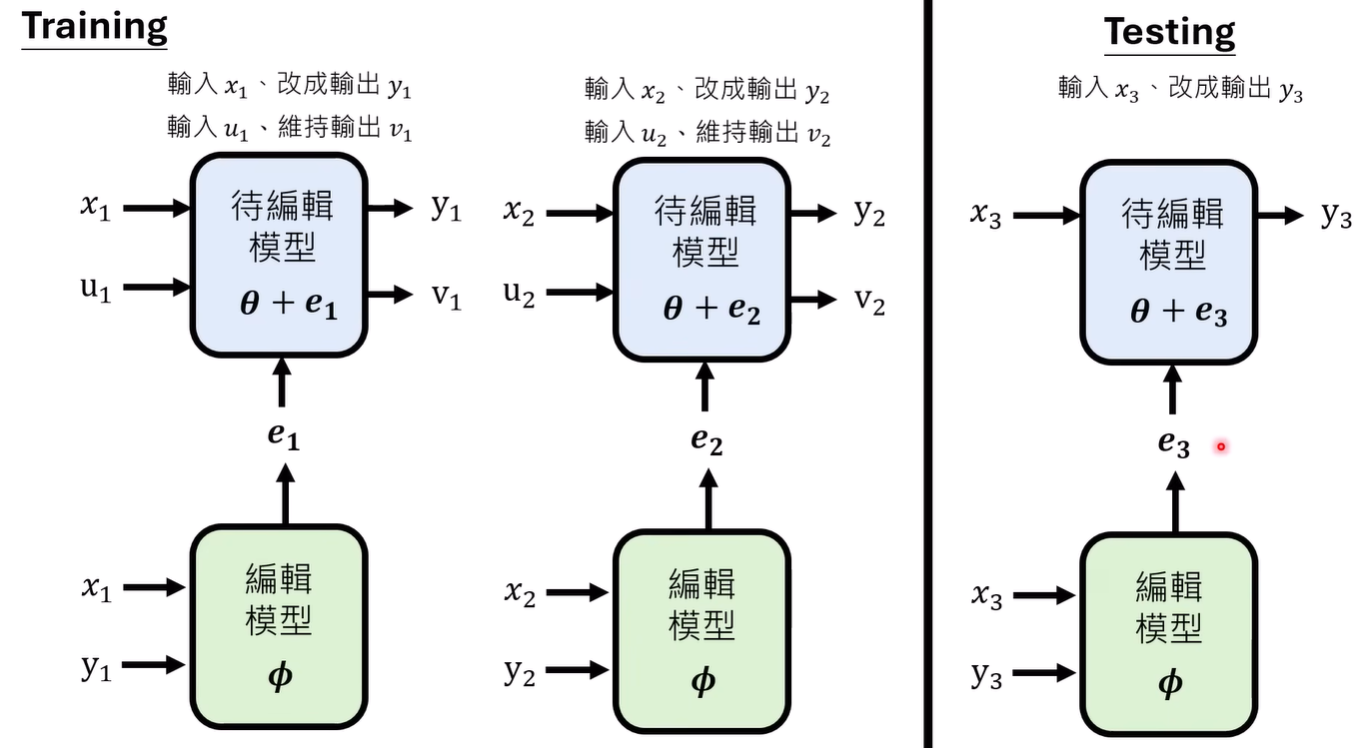
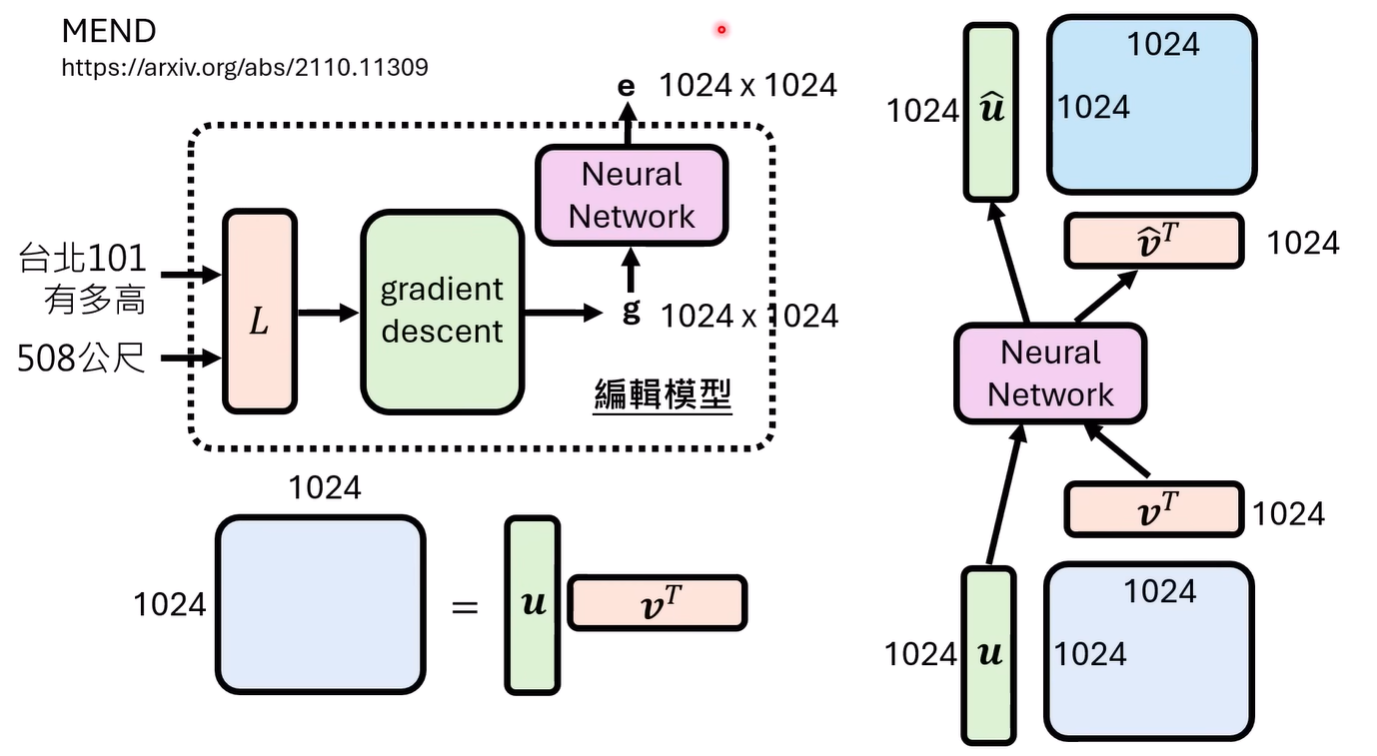
但是这样的训练还是太难了,期待模型直接输出一个巨大维度的向量而且能正确修改有些科幻,所以实际上在这样的思路上会有简化
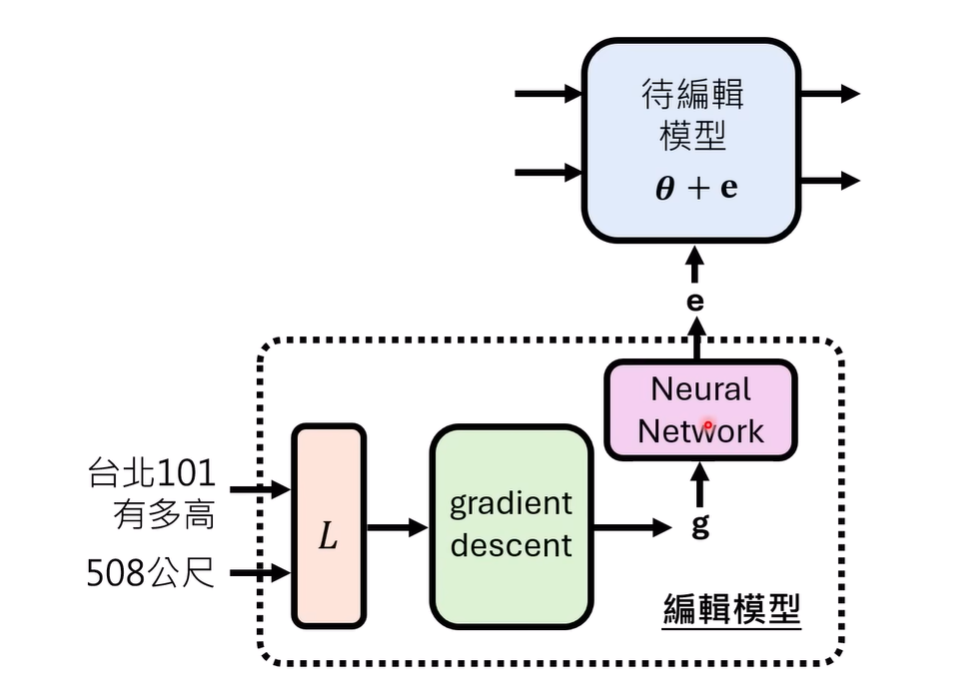
大概的做法(2021年左右)是计算损失,经过梯度传播得到梯度,然后再输入给真正新的,用于训练的模型来预测修改向量e
不是很理解这里的做法
然后这样并没有就变得很简单,假设g是1024x1024,输出是1024x1024,中间只是一个一层的FC,那就需要有1024四次方的参数,根本没办法训练哪怕正常大小的模型。所以有另一个古早的做法利用了梯度矩阵的分解减少了输入输出的维度