FROM 【生成式AI時代下的機器學習(2025)】第七講:DeepSeek-R1 這類大型語言模型是如何進行「深度思考」(Reasoning)的? - YouTube
可能的方式
推理(Reasoning)是一种test-time compute的做法,通过增加test-time计算量来优化模型推理(inference)结果
Chain-of-Thought
可以把推理模型的推理看成是一种CoT
之前的chain-of-thought可以被称为 short chain-of-thought,推理模型的推理也就称为 long chain-of-thought,但是实际上是比较模型的长短界定。可以直接通过指令的方式让模型模仿推理过程(也是一种zero-shot/few shot的做法)
由于是指令,所以取决于模型的能力
给定思考流程
基本的做法就是 多次回答,以某种方式选择答案
有论文 [2407.21787] Large Language Monkeys: Scaling Inference Compute with Repeated Sampling 直接使用各个模型进行上万次的问答,发现对于基本能力还行的模型,总有一次会得到正确答案

那如何找到这么多答案中的正确答案呢?
可以是 多数投票(majority vote)[2203.11171] Self-Consistency Improves Chain of Thought Reasoning in Language Models,confidence [2402.10200] Chain-of-Thought Reasoning Without Prompting
把答案放在特定token间比较好处理
有这样的一篇文章进行了大量的实验 Scaling test-time compute - a Hugging Face Space by HuggingFaceH4
发现majority vote是一个较强的baseline
选择答案的方式可以引入verification
训练/选择一个verifier
- best-of-N
- 也可以是sequential的方法,通过对前一次的解法进一步解答来优化答案
- 甚至可以parallel和sequential结合 [2408.03314] Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
但是这样的做法是对结果来进行verification,一般是 process verification更好
如何让模型分步骤生成呢?可以是让模型生成的时候带上<step></step> token,然后每次生成到</step>就停止,对多次生成的step进行verification,然后选择某些step进行下一步生成 [2305.20050] Let’s Verify Step by Step
如何训练这样一个PRM(Process Reward Model)呢?我们需要判断每个步骤的优劣,一种做法是从每一步开始往后多次生成,通过正确答案次数概率来得到步数优劣
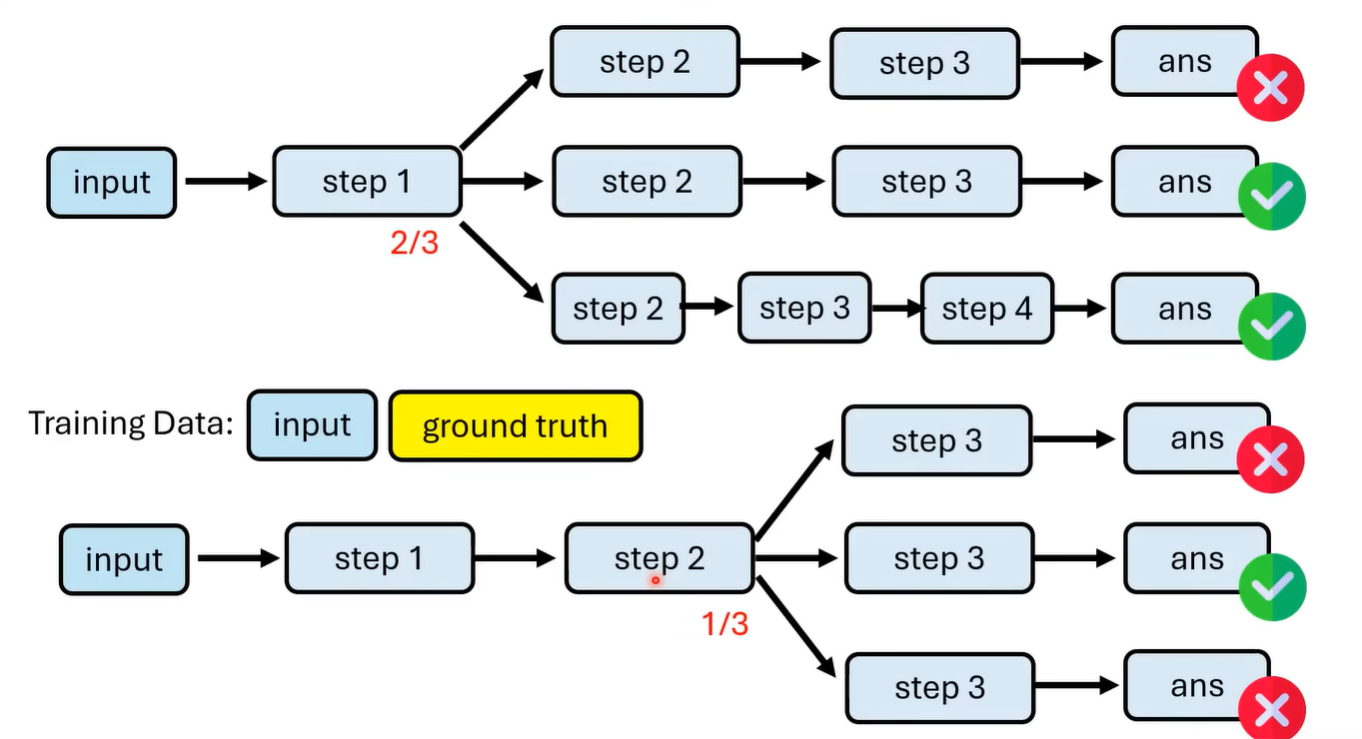
process verifier提供了一个score,那阈值threshold的设置就涉及到了解码方式,例如beam search,MCTS
注意,process verifier一般是吃这一步之前的路径作为输入
Imitation Learning
通过训练教导模型自己学习做推理
训练资料可以通过上面的方式得到,即通过CoT得到reasoning process,然后经过各种verifier来筛选训练数据
这里的筛选方法实际上有许多,可以是通过树状的decode方式,同时对每一个步骤进行verification,最后得到数据进行SFT
也可以是通过RL的方法来进行训练
不过推理过程不一定要是完全正确的,教导模型进行自我改正更加合理
但是如何教导得到自我改正的能力呢? 论文 [2404.03683] Stream of Search (SoS): Learning to Search in Language 提出的方法是 先得到整个树状结构,通过dfs来得到包含错误步骤的解答路径,然后在错误步骤的修改(跳跃)中间插入verifier的反馈让错误路径向正确路径的跳跃更合理,以此来得到最终的训练数据
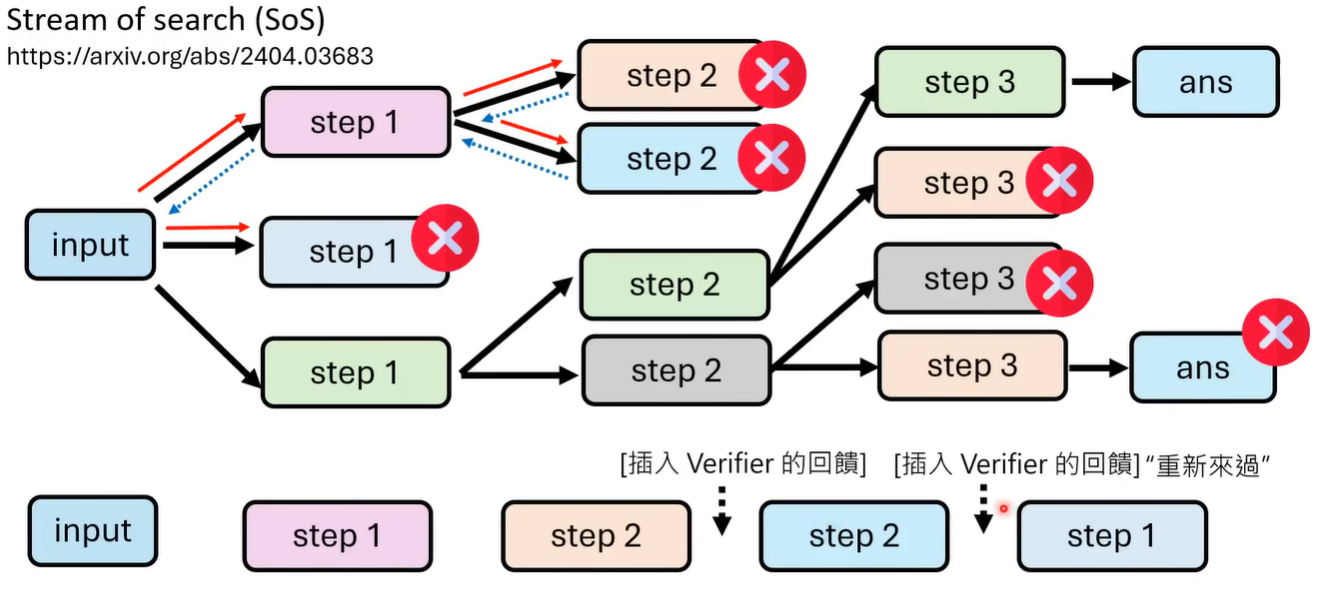
也可以再通过语言模型改写这个路径,让路径更加可读
当然也可以直接用现成的推理模型进行distillation
Reinforcement Learning
结果为导向
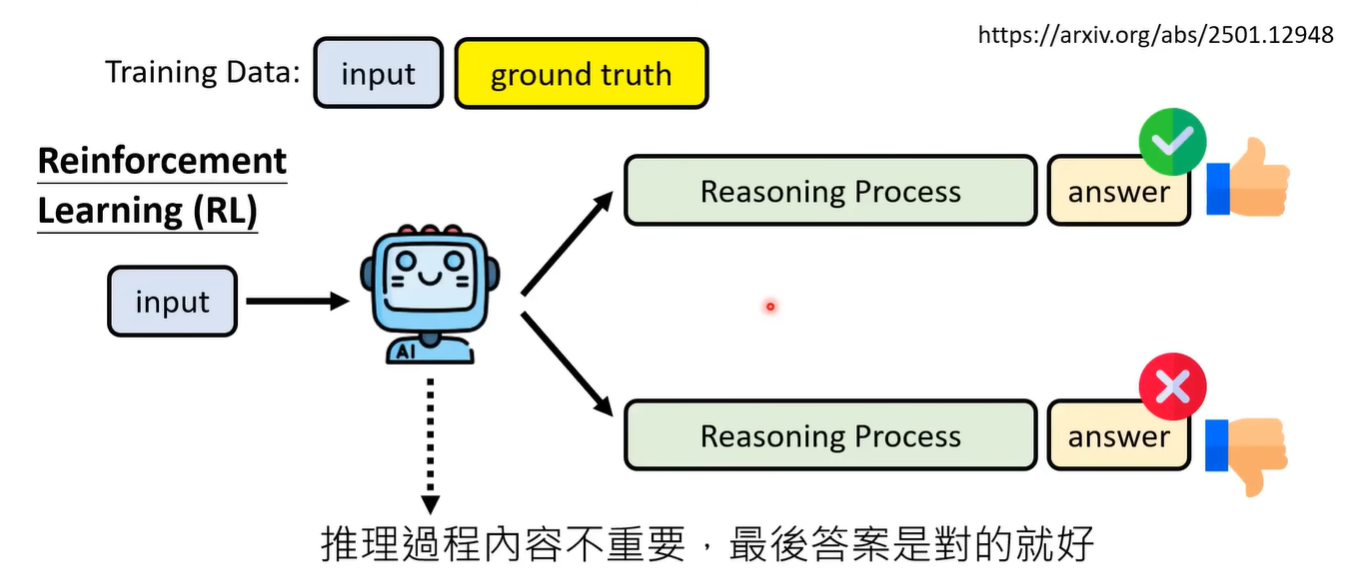
不在意中间过程,只考虑最终的结果是否正确来进行奖励
这样训练出来的模型推理过程会十分混乱,以DeepSeek-R1为例,R1-zero就是这样得到的模型。为了可读性和优化,DeepSeek的做法是让R1-Zero生成一些数据,然后人工筛选和另外的模型进行CoT得到其它数据最终得到几千个样例,进行imitation learning得到另一个模型,这个模型再次进行RL得到另一个模型,这个RL的过程限制了推理过程的语言需要一致。这个模型再次用于生成数据,生成大概600k example+self-output得到第三个模型,最后进行safety和helpfulness的RL得到DeepSeek-R1
distillation更适合强化较差的base model
一些问题
过度思考
推理的长度并不一定与正确率负相关,因为可能推理长度与问题难度相关,只有足够长才能解一些困难问题,只能说有一定的相关性
有很多论文发现并不真的需要特别长的推理过程
那如何避免模型过度思考呢?
一种方法是修改CoT的指令,如Chain-of-Draft,适用于上述方式的前两种
对于imitation learning,可以是筛选训练数据时筛选最短的,可以是渐进式学习[2405.14838] From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
对于RL,需要限制推理长度,比较流行的方式会是根据问题的难度进行限制,先通过模型的多次回答得到平均长度,如果短于平均就是好的
有一些模型能够控制推理长度,在训练时,额外输入推理长度,将目标长度和实际长度的差异作为奖励的一部分
通过RL控制长度,意外的不太影响效果
Evaluation
如何进行对推理能力好的评估呢?
单纯的通过答案正确性评估,可能有的模型只是记忆了答案而不是真的拥有推理能力
现在可能需要一种benchmark的优化
一个例子是ARC-AGI(2021)(被o3打爆),ARC-AGI是一种图形化的智力评估,可能不太容易进行背诵,但是也可以通过特化训练来打爆
另一个例子是 Chatbot Arena,让全球人来进行评估和筛选,但是人的评估标准也可以hack
Chatbot Arena通过Elo Score来考虑无关因素 https:/blog.lmarena.ai/blog/2024/style-control/