RNN
最简单的RNN是 sequence 输入 squence输出,每次输入都更新hidden state,在需要输出时通过hidden state的变换得到输出
通常绘制unfold RNN
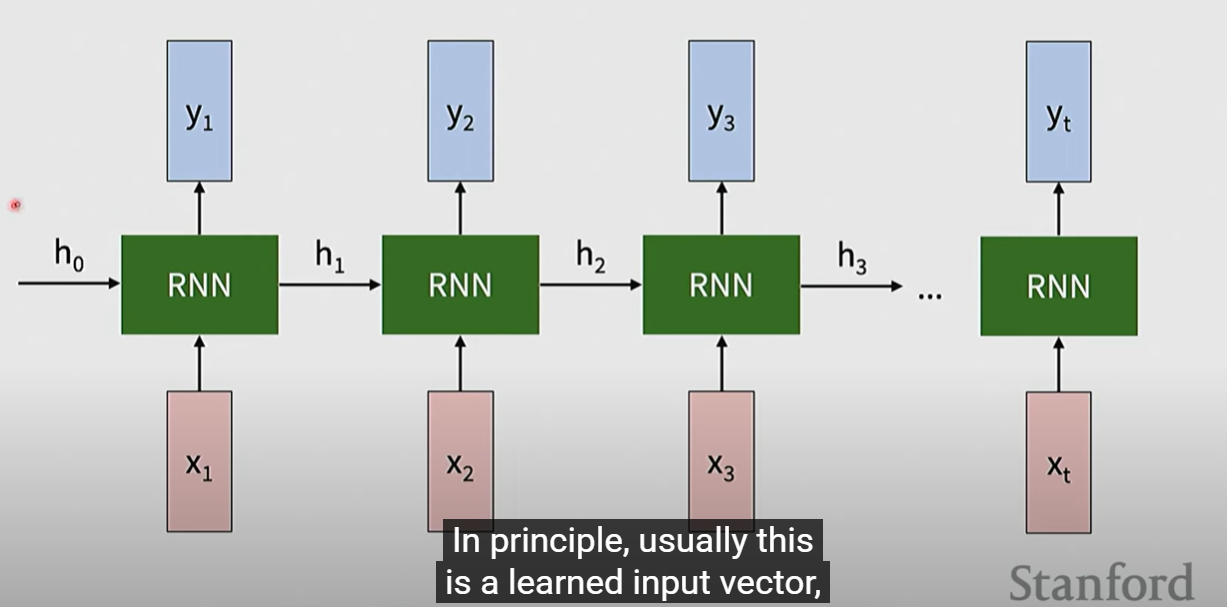
在many-to-many情形
损失的计算会是每个输出一个损失,有时也会有一个总损失
在计算梯度时,可以将每个当成是单独的,计算每一步的梯度之后sum up
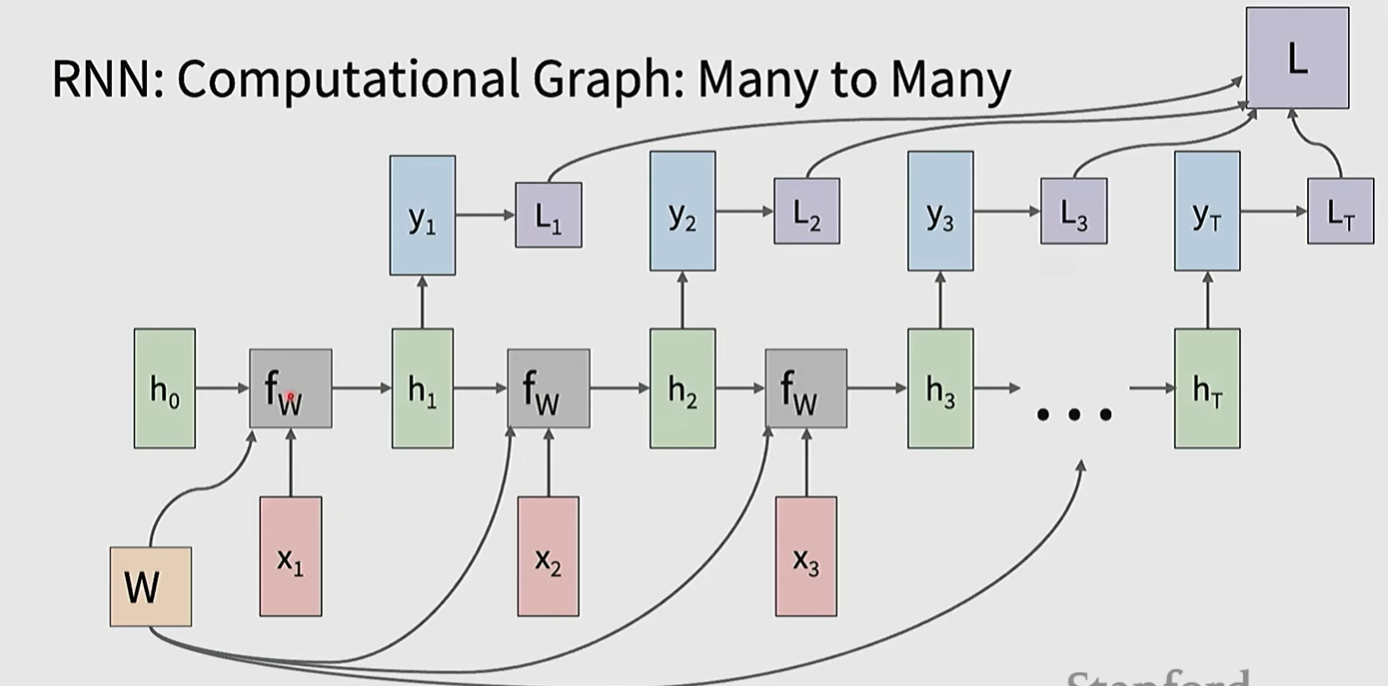
在many to one 情形,只在最后的位置计算损失,有可能会使用到所有的hidden state,也有可能只是最后一个
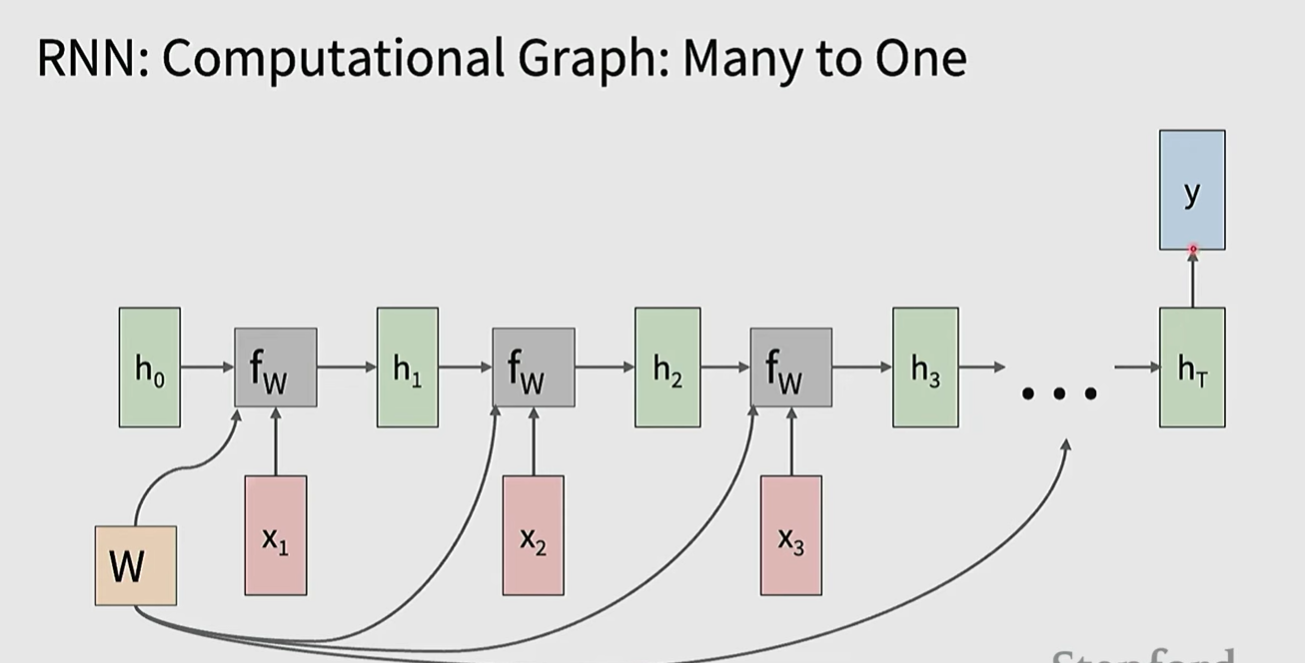
在one to many情形,每个状态仍然需要input x,所以除了第一个输入之外,其余的可能输入0,也可能输入上一个状态的输出
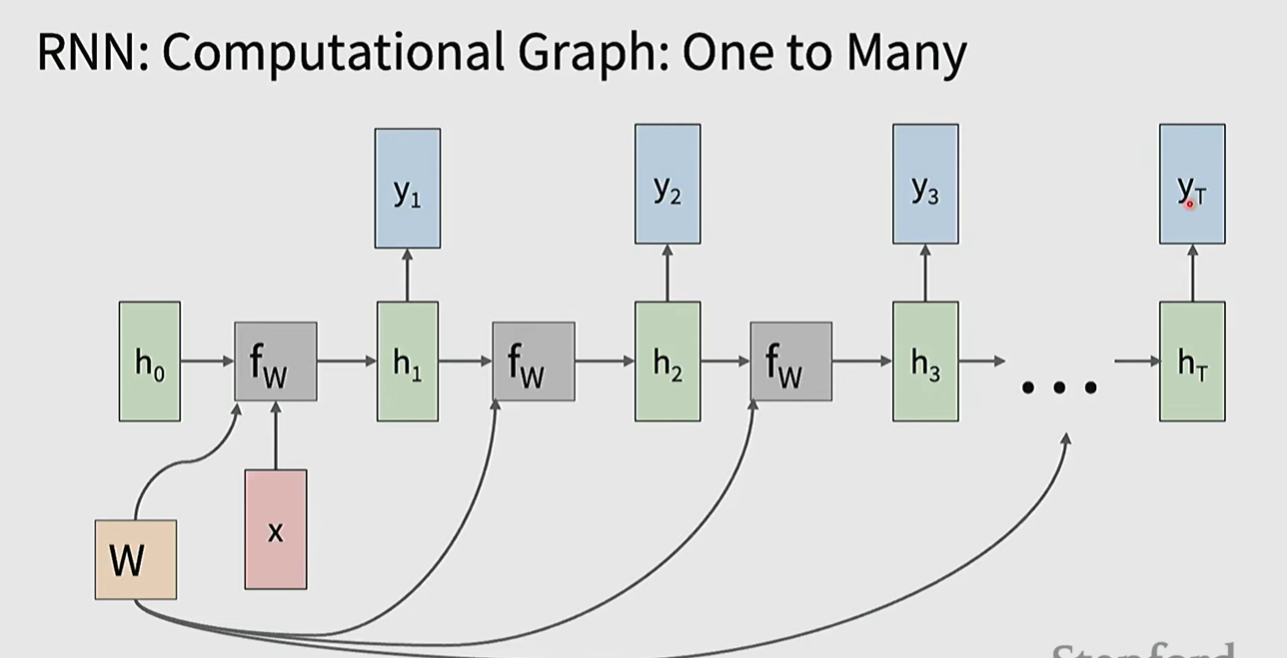
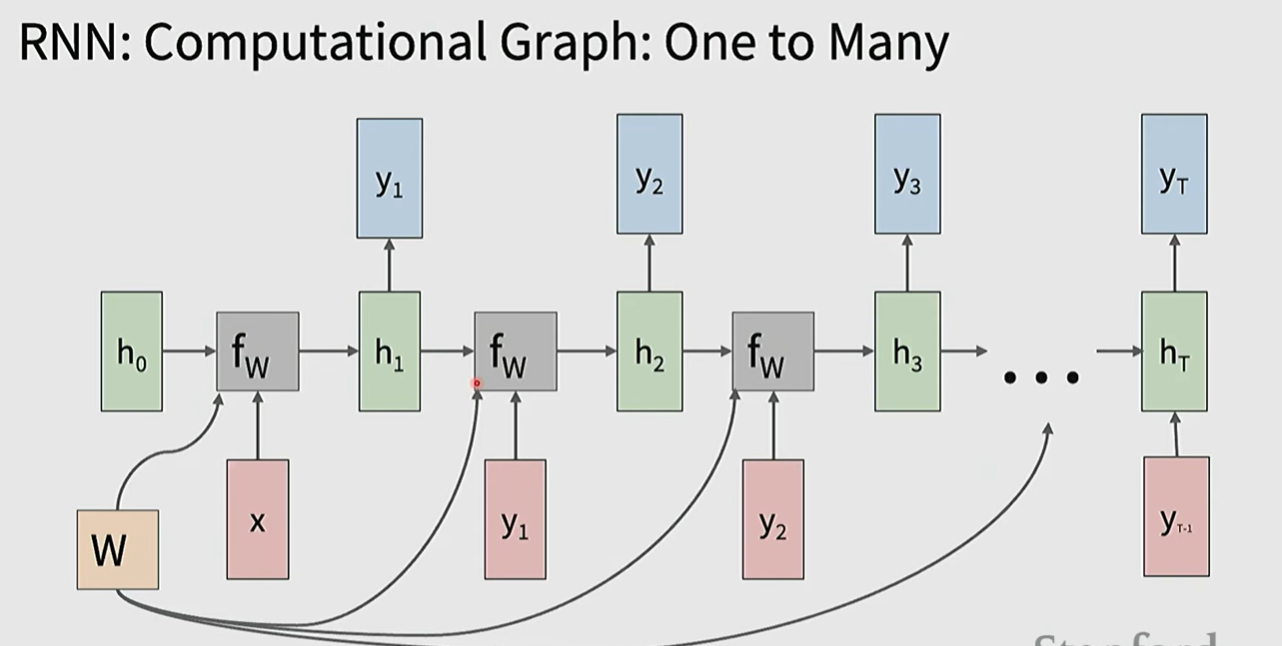
当sequence变得很长的时候,计算梯度需要记录大量的activation value等等,会导致OOM,这样的梯度计算称为backpropagation through time
一种解决方法是滑动窗口,称 Truncated Backpropagation through time
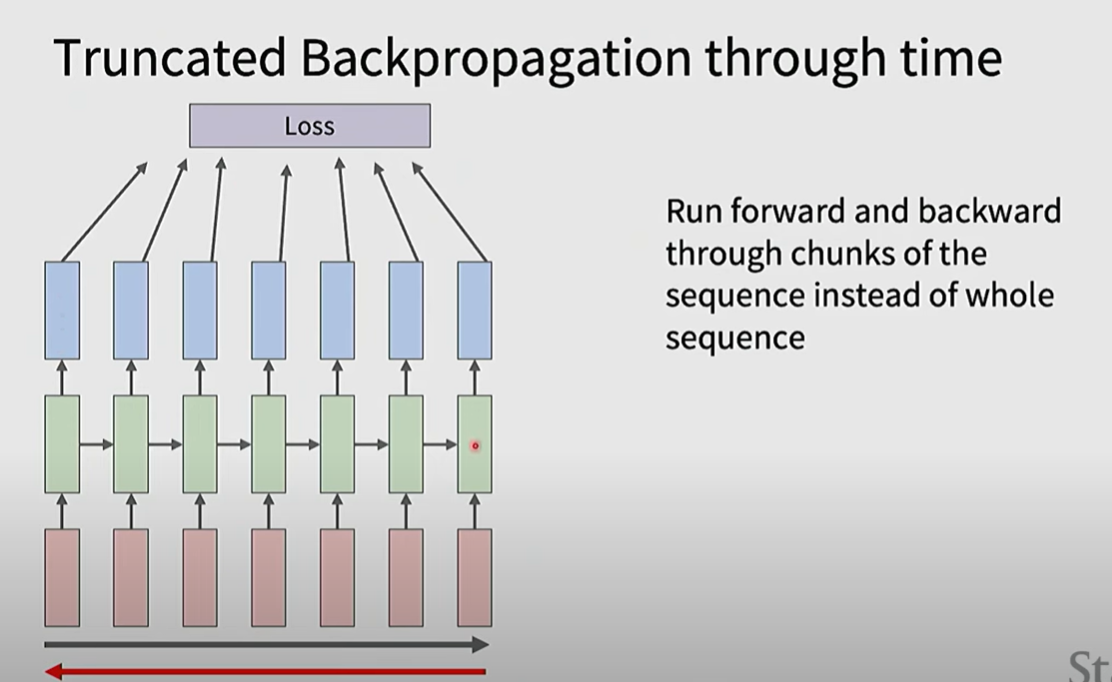
这里感觉讲得比较乱也比较浅,不是很明白,可能后面涉及到得再深入补
RNN的优点在于没有sequence的输入长度限制,模型的大小不随着sequence长度变化
缺点在于 recurrent computation比较耗时,实际上hidden state没办法存储太久远的信息
另外的,vallina RNN存在梯度爆炸和消失的问题,梯度爆炸存在如gradient clip等方法进行优化,梯度消失是主要的问题
LSTM开了一条支路在不同位置传递信息而不使用tanh,避免了tanh导数带来的梯度消失问题(缓解),同时通过如forget gate之类的设置改善了信息的存储
A bit about Transformer
ViT
by the way
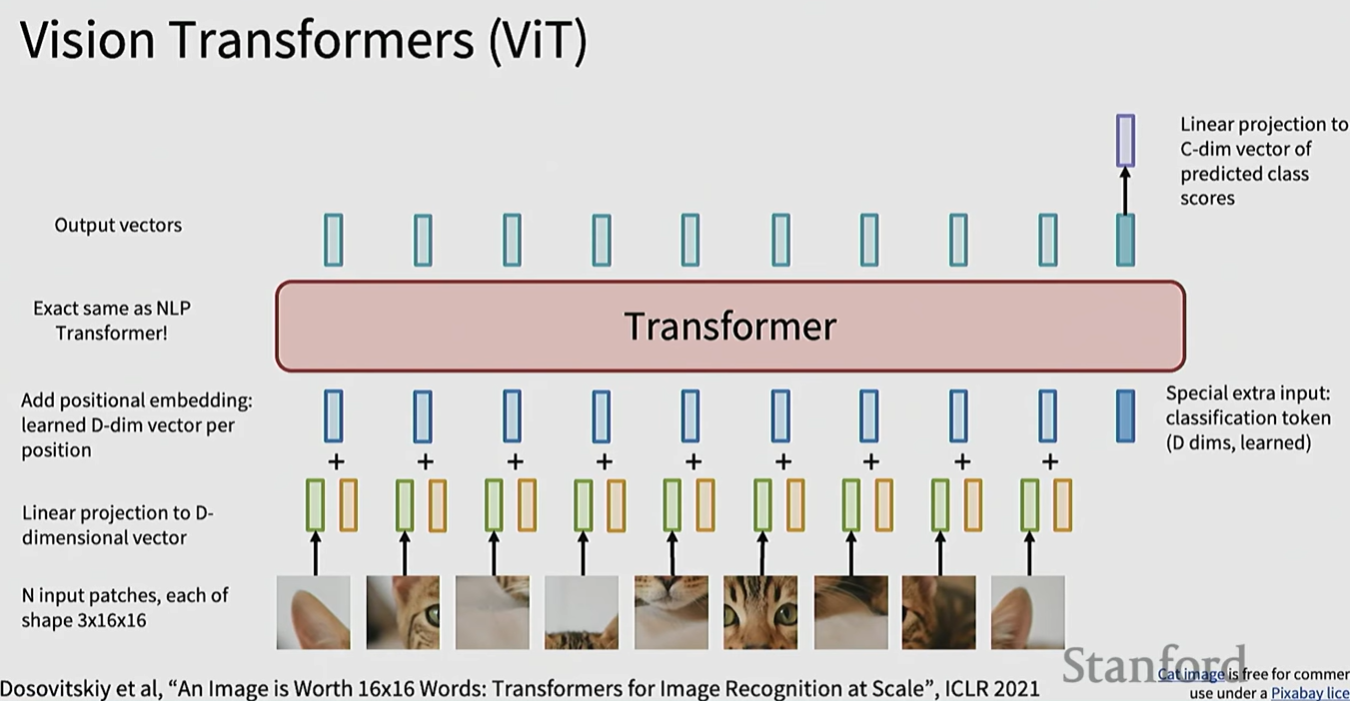
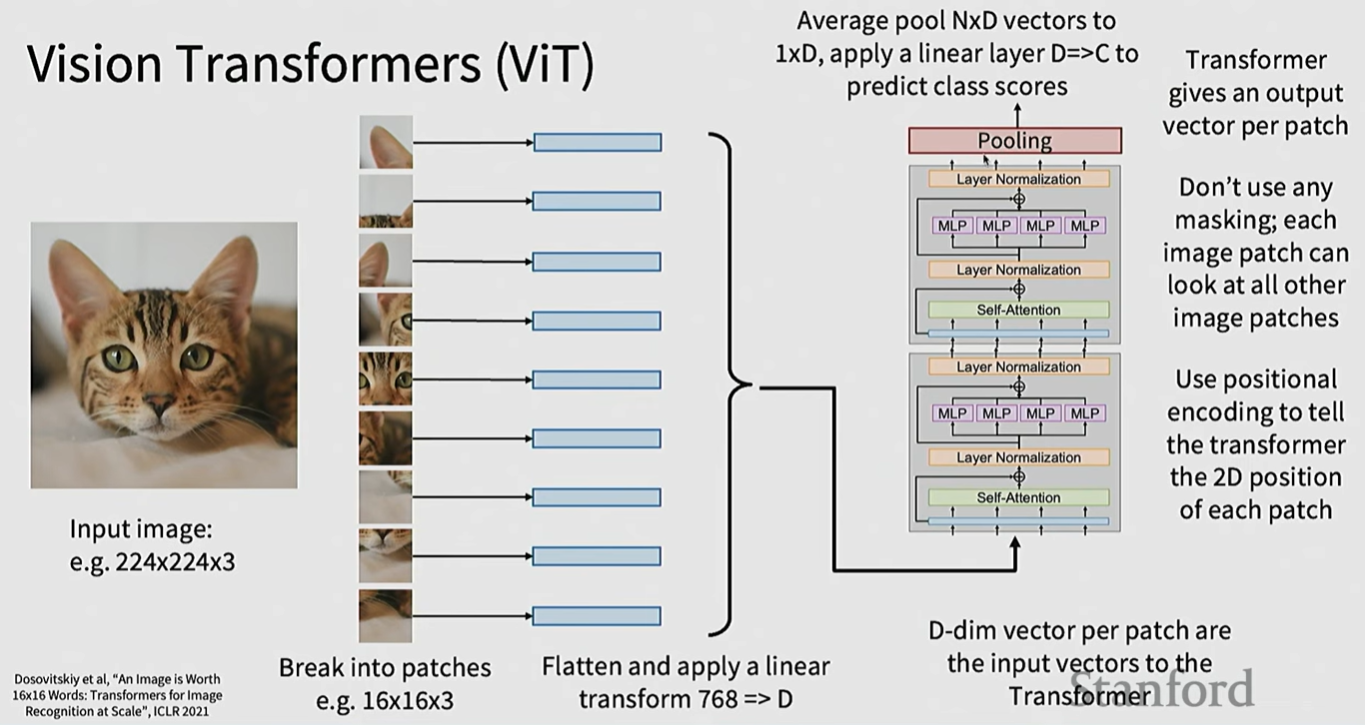
ViT将图片划分成patch,每个patch转化为token,加上position embedding(可以是简单的序号序列,也可以是xy坐标等),然后作为transformer的输入。
如果用于图像分类,一种方法是在最后加入一个class token(learnable),将最后位置的输出经过transform,转换为C-dim的类别概率
另一种方法是直接对输出进行pooling
Optimization
Pre-Norm & Post-Norm
原本的Transformer块是post-Norm的
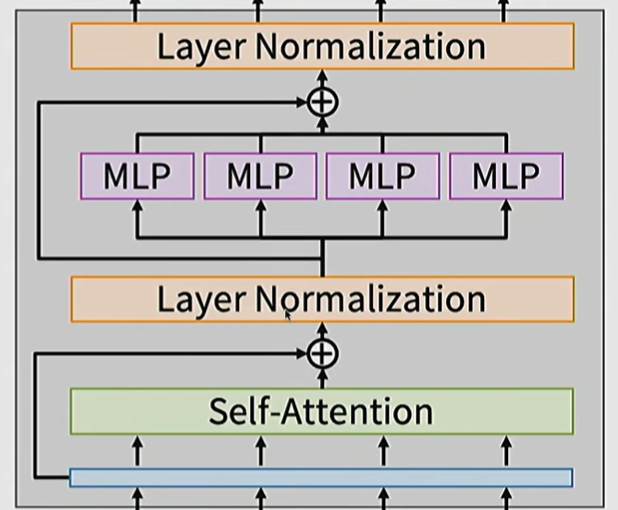
这样无论如何都会经过normalization,无法实现ResNet中提到的identity function
可以改成pre-norm,将normalization layer放在attention和MLP之前
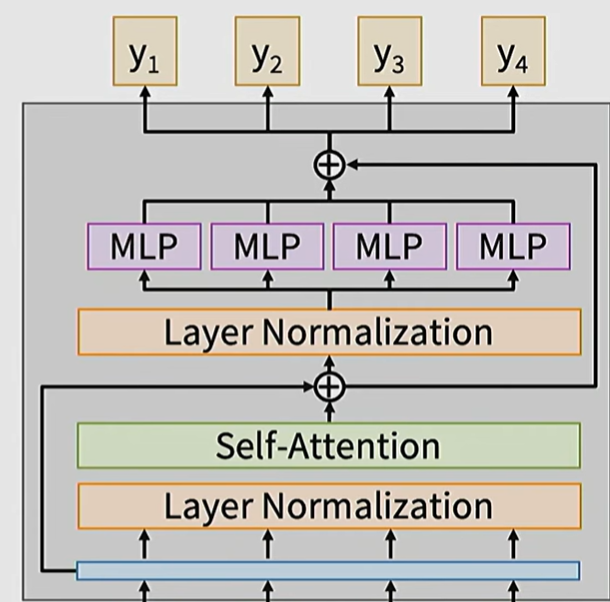
Normalization
将layer Normalization 改成 RMSNorm
Activation function
将MLP的activation function ReLU/GeLU改成 SwiGLU MLP
Mixture of Experts
多个expert取代单一的MLP
CV Tasks

Semantic Segmentation
语义分割希望给每个像素都赋予一个标签,形成一个张像素粒度的分割图
如果直接对每个像素都进行一次分类的话,首先单个像素分类需要考虑context,其次十分耗费时间
语义分割的解决办法是训练一个模型,直接输出一个整个pixel map,每个pixel对应有其标签
为了输出与输入图片相同大小的pixel map,整个CNN不能有任何的down sampling 操作,但是这样显存占用很大,通常是 downsampling 之后 upsampling
那此时面临两个问题,一个是如何upsampling,一个是损失如何定义
对于upsampling
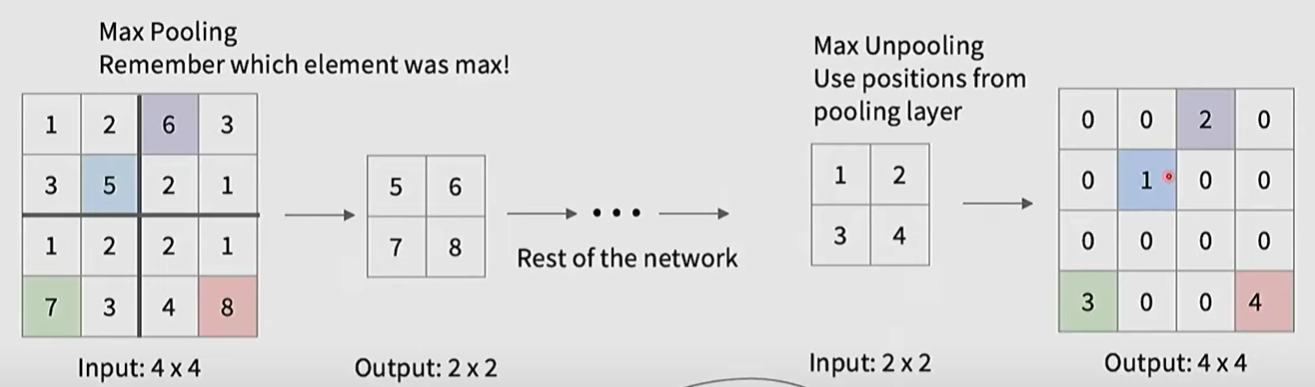
一种方法是定义unpooling
max unpooling,如果downsampling使用 max pooling,unpooling的时候可以使用max pooling选中的位置
也可以是learnable的,定义一个learnable的filter,然后对于input的每个pixel,与该filter相乘,得到输出的一部分pixel,对于filter移动后重叠的部分,两个数值进行相加
称作 transpose Convolution
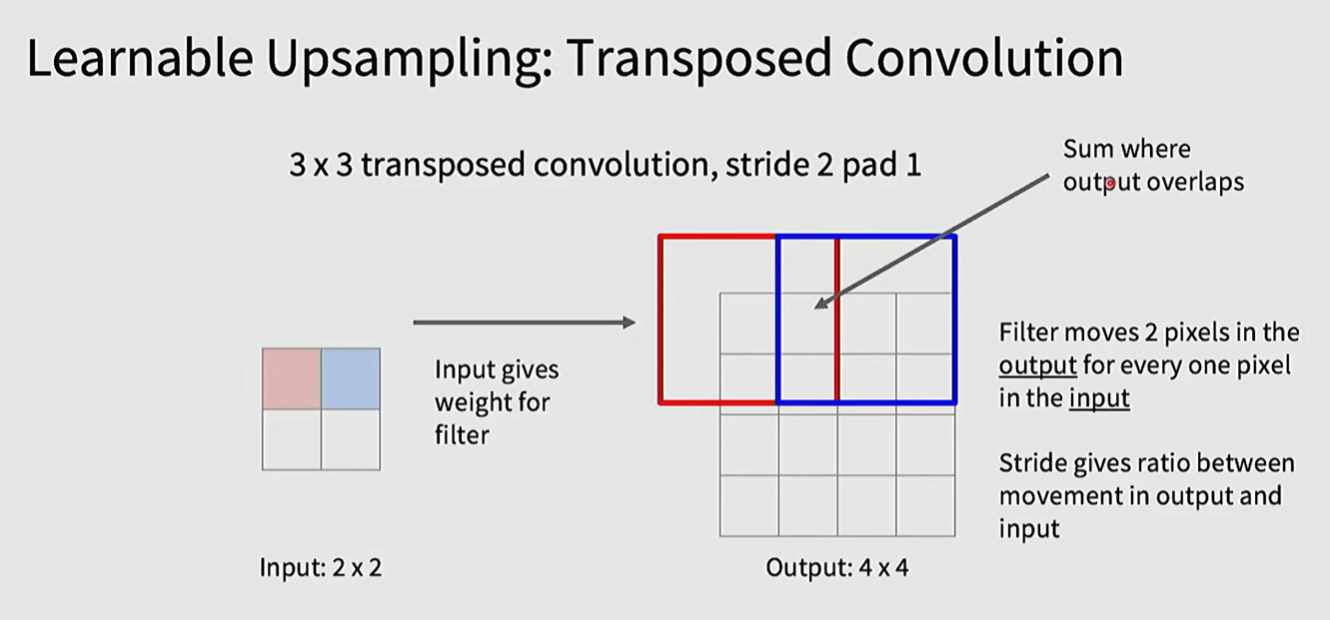
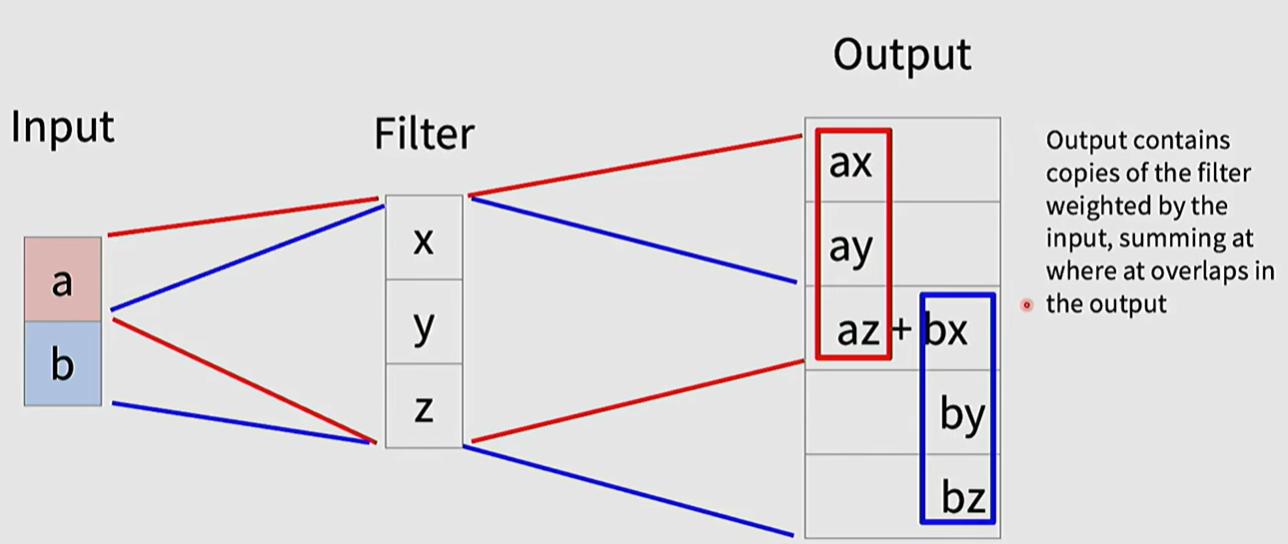
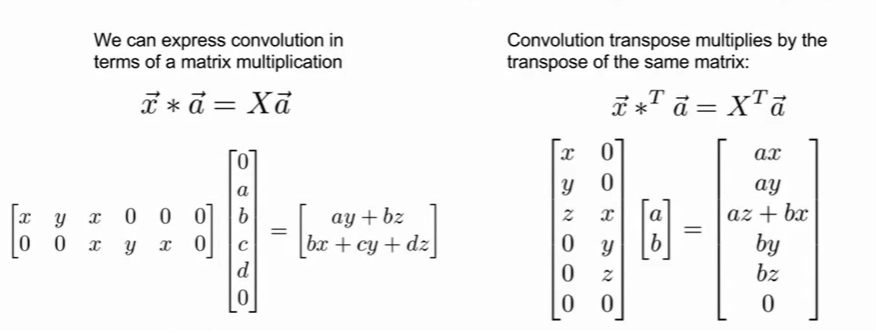
transpose convolution名字的由来是 每一个卷积操作都可以写成矩阵相乘
当它进行transpose之后得到的就是此处的upsampling
语义分割不会对图像中相同类别的像素进行区分,区分每个像素归属于哪个实例的任务称实例分割

Oject Detection
目标检测实际上是 classification + localization
除了对图像进行分类之后(softmax loss)之外,同时进行坐标的损失(L2 loss for example),结合多任务损失(可能是相加)得到最终的loss
但是如果对于多个物体检测,整张图片进行处理显然不行,我们需要考虑更细粒度的做法
常用的做法是搜索region proposals
RCNN:使用region proposals,每块图像经过一个CNN再进行分类
这样的做法非常慢,因为每个boxes都分别经过了CNN
Fast R-CNN则是,先使用CNN得到带region proposal的feature map,再将每个proposal经过一个小的CNN进行分类,得到linear+softmax loss + box offset(box是否应该进行偏移)
这两个都需要至少两次处理图像,计算成本比较高
YOLO:将整个图像划分成SxS的网格,然后每个方块得到 包含对象的概率,B个refined bounding boxes,类别概率三个输出, 进行thresholding
DETR:DETR是使用transformer的一个成功尝试
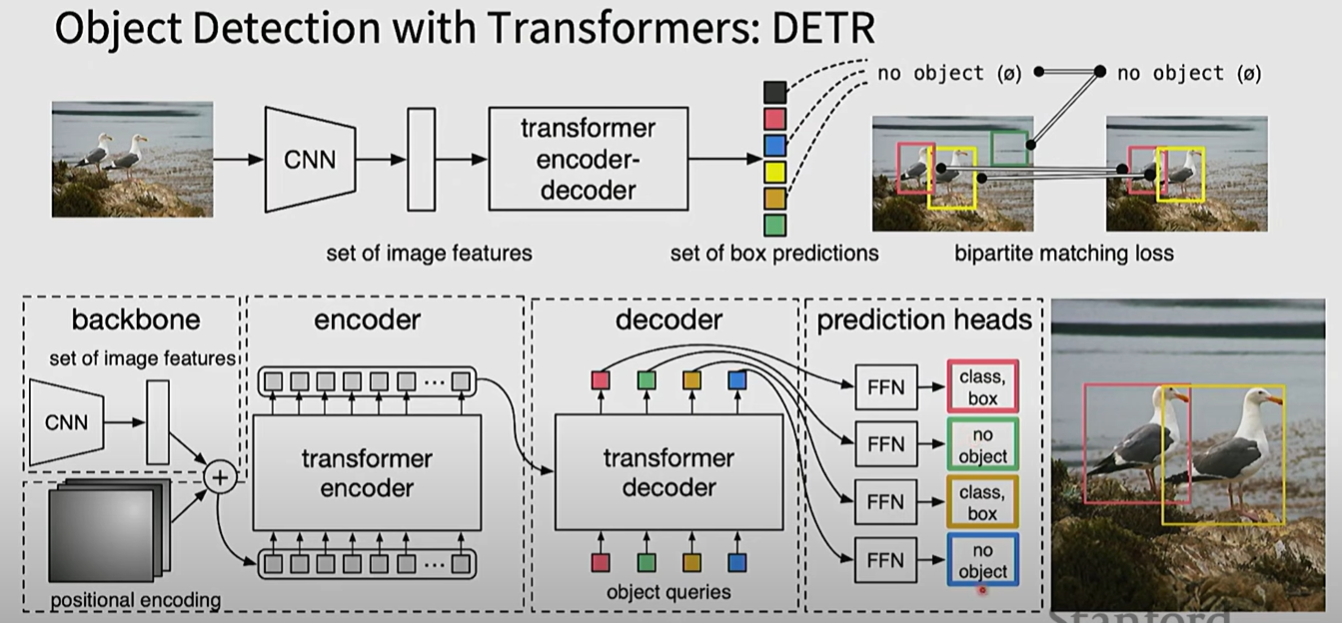
问题在于如何得到multitask的输出,DETR的做法是,同样的进行一个patching,position embedding,输入到encoder,将得到的输出与decoder做cross attention,但同时给decoder输入对应不同任务的learnable的queries,每个位置对应的输出经过各自的FFN得到四个不同任务的结果
Instance segmentation
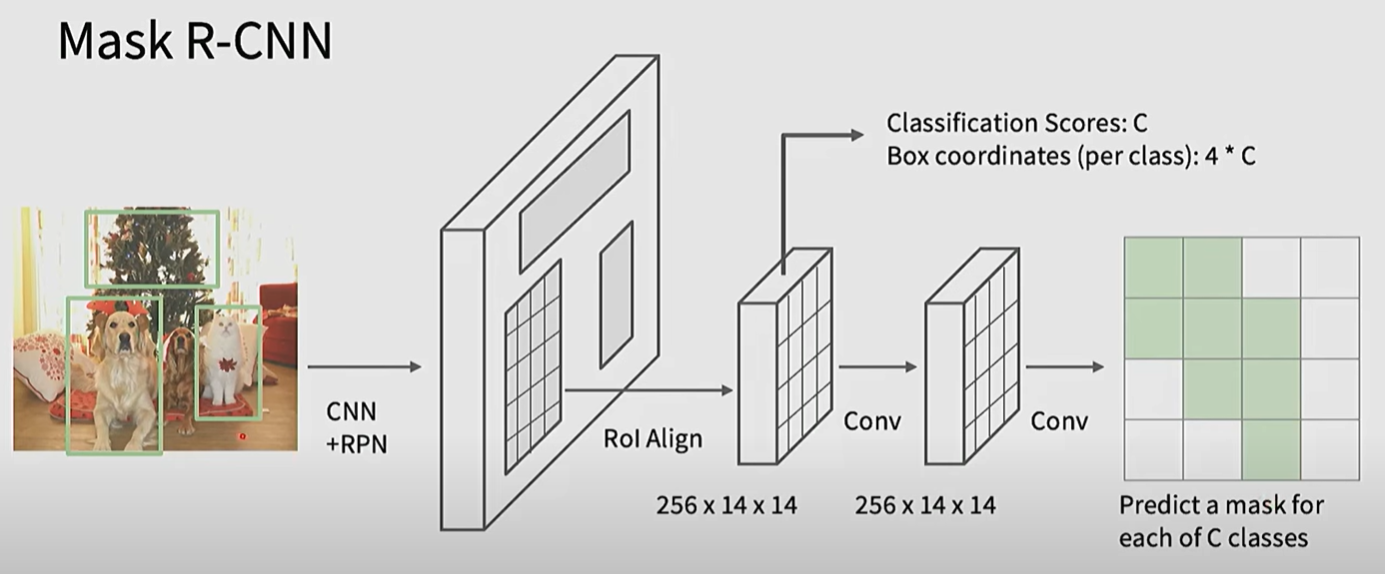
得到的Instance segmentation的方法是,除了输出bounding boxes,class probabilities之外,再输出一个Mask
Mask R-CNN的做法是,在最后再经过一层convolution得到Mask
Visualization
visualization是指模型可解释中的可视化,能帮助理解模型如何学习特征
- 一种可视化是可视化filter
- 能够简单进行可视化的是3channel的filter,通常是对简单pattern的学习

- 另一种可视化是 saliency maps
- 通过分类结果的score,对像素(而不是weight)的梯度(偏导),偏导越大,score对其便更敏感,这样就可以得到哪些像素对分类结果来说是重要的(改变这些像素结果就会改变)

- 对于CNN来说,最常用的是CAM(class activation mapping)和Grad-CAM
- CAM只能用于最后的一层convolution layer,Grad-CAM是其改进

- 对于transformer架构
- 使用注意力来进行可视化
