How to do Classification
用宝可梦的种族值描述宝可梦作为输入
Classification as Regression
用数字表示类别,接近哪个数字代表哪个类别
regression来做的话,隐含有数值大小的信息,输出是一个连续的数值范围,一方面会因为类别的离散化掩盖信息,一方面为了靠近离散的类别,训练结果可能出错
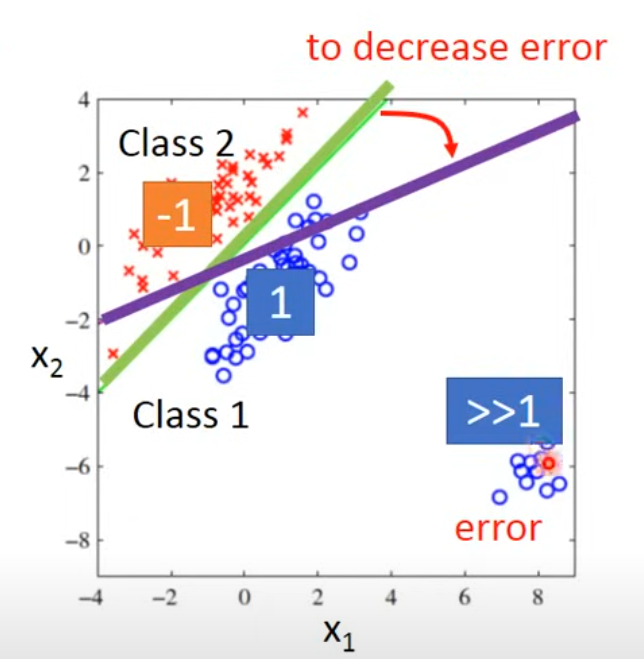
- 原本应是绿色分界线,为了使得右下角的数也趋近于1,得到紫色分界线
而且同时,因为数值的大小信息,表示类别的数字越接近,隐含着类别相接近的信息,往往是不成立的
直接输出类别

- model --- 输入x,直接输出类别
- loss function --- 如果不一致则输出1,一致输出0,这样才能最小化。
- 无法微分,可以用preceptron, SVM
Classification as Probability

- 两个类别,在类别中取值的概率是,取值为的概率是 ,给定,属于某个类别的结果为
- 计算概率,概率最大就可以得到所属类别
- 此时, 需要从训练数据中计算出来
这样的想法称Generative Model
通过计算产生的概率,就能够产生
实际上在分类之前,产生的概率就能被计算出来
- 如何从训练数据中计算和
- 直接由占比计算,必须能够代表在整个数据集中的概率
- 假设是一个高斯分布,需要从训练集中找到它的 和 (Covariance matrix)
- Maximum Likelihood
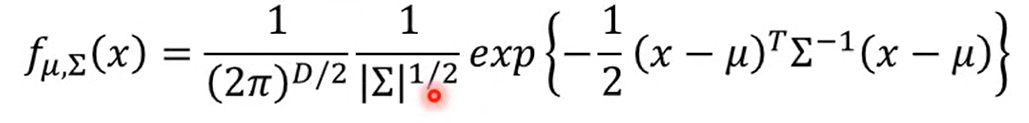
Maximum Likelihood
训练集中的数据,有可能从任何Gaussian Distribution中sample出来,但是得到这些数据的概率是不一样的
找概率最大的Gaussian distribution ---Maximum Likelihood
每个类别
微分得解
代入得到得, 就可以得到对应的高斯分布,就做出来了。
每个类别都找到Maximum likelihood的Gasussian ditribution,得到参数就可以计算概率
在宝可梦属性分类任务表现糟糕
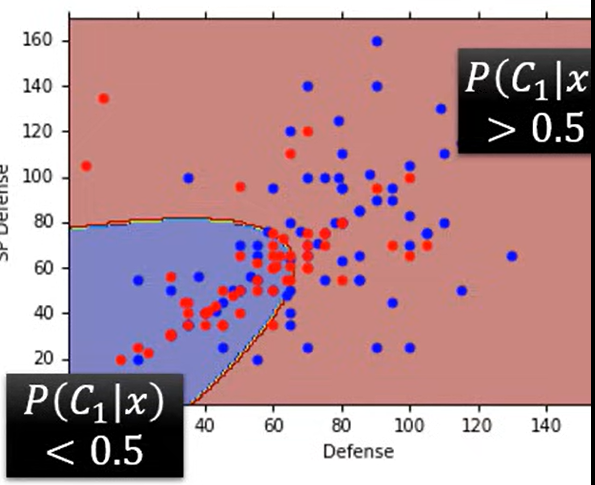
Modifying Model
Generative model 中,更常见的是share the same
跟input size平方成正比,如果每个都有独立的 的话,参数过多容易overfitting
共享的话
两个类别的话
解得
共享的情况下,分类的boundary会变成直线,称linear model
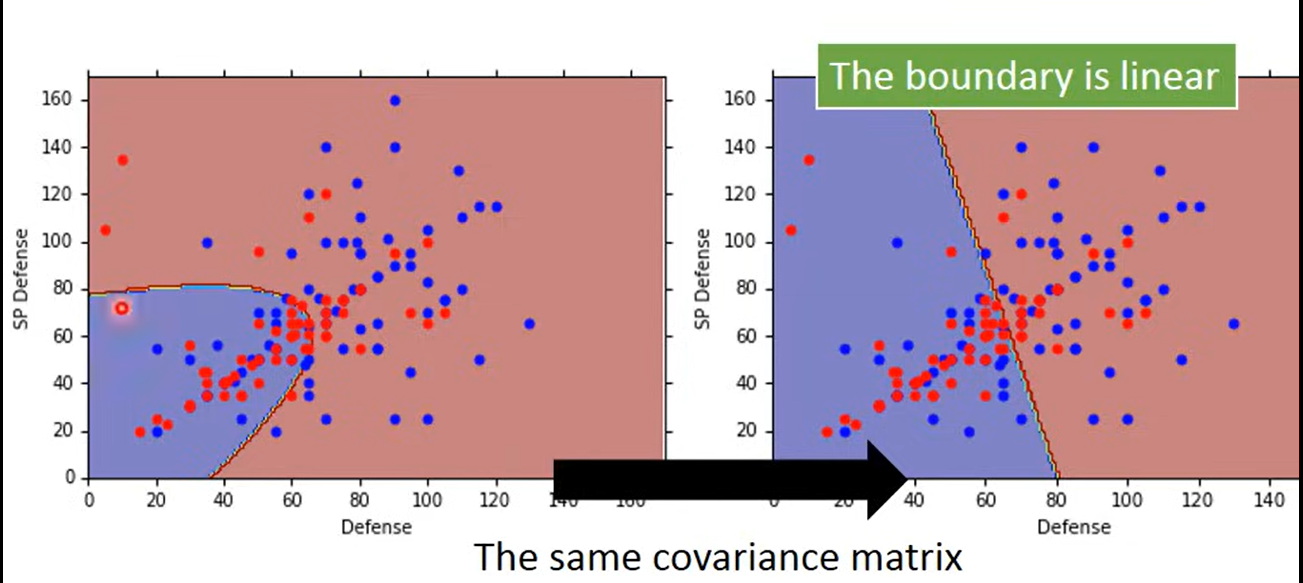
正确率提高
Summary
- function set
- Loss function
- maximum likelihood
- trainning(find the best function) --- 直接可以算

Why Gaussian
自己定的,其他也可以,决定模型的复杂度
如果是binary features(输入要么是0要么是1),可以认为是Bernoulli distributions
如果认为输入的每个维度是独立的,使用的是Naive Bayes Classifier(朴素贝叶斯分类器)

Posterior Probability
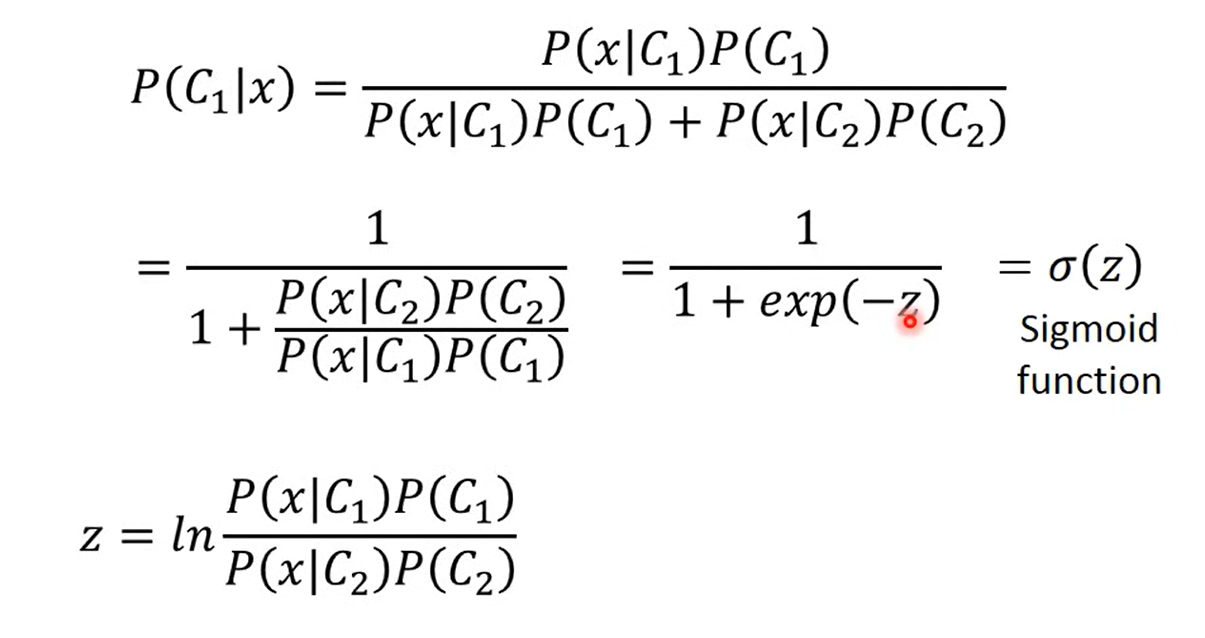
- 上下同除,取自然对数,得到一个sigmoid
关于z

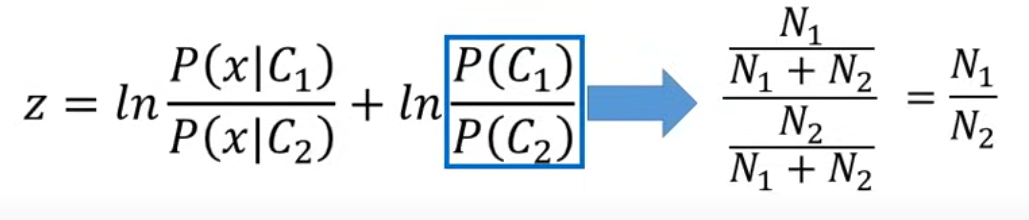
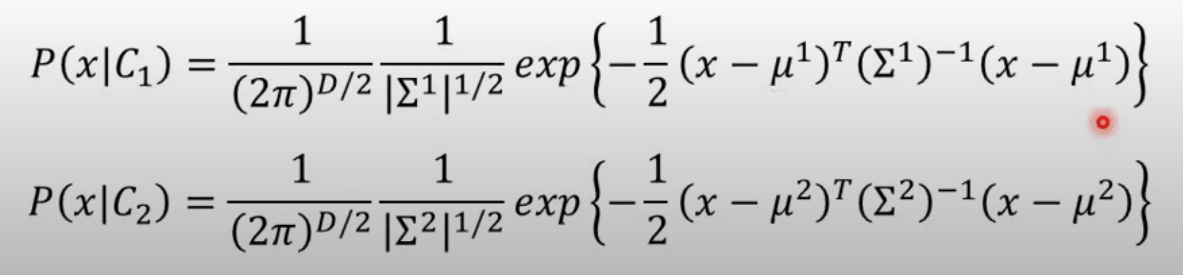
相除相消
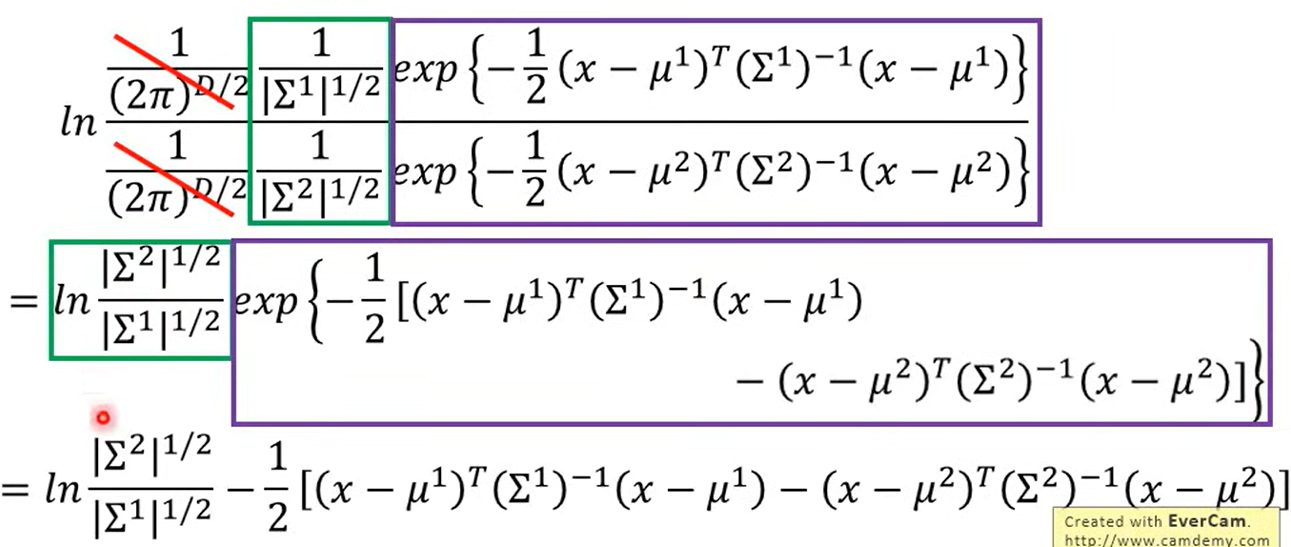
展开一通算
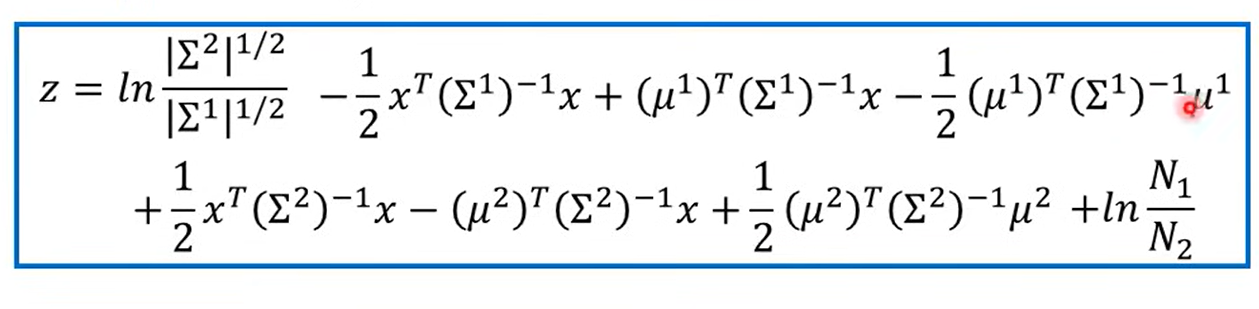
是共用的
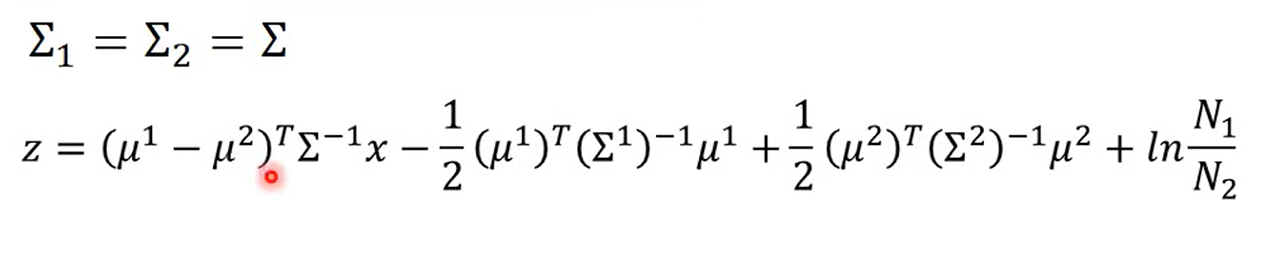
前一部分向量乘矩阵得到一个向量,后一部分是一个常数
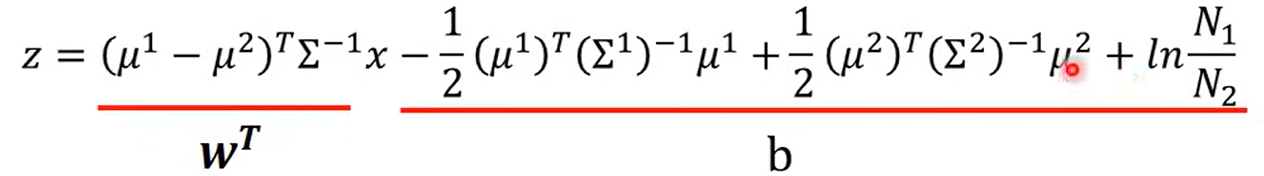
所以实际上
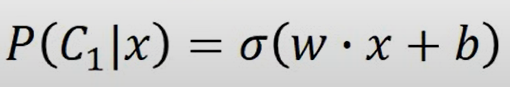
- 证明了当共用时,Boundary是直线
在Generative model 中,估计了 来得到模型,那能不能直接找呢?
见Logistic Regression