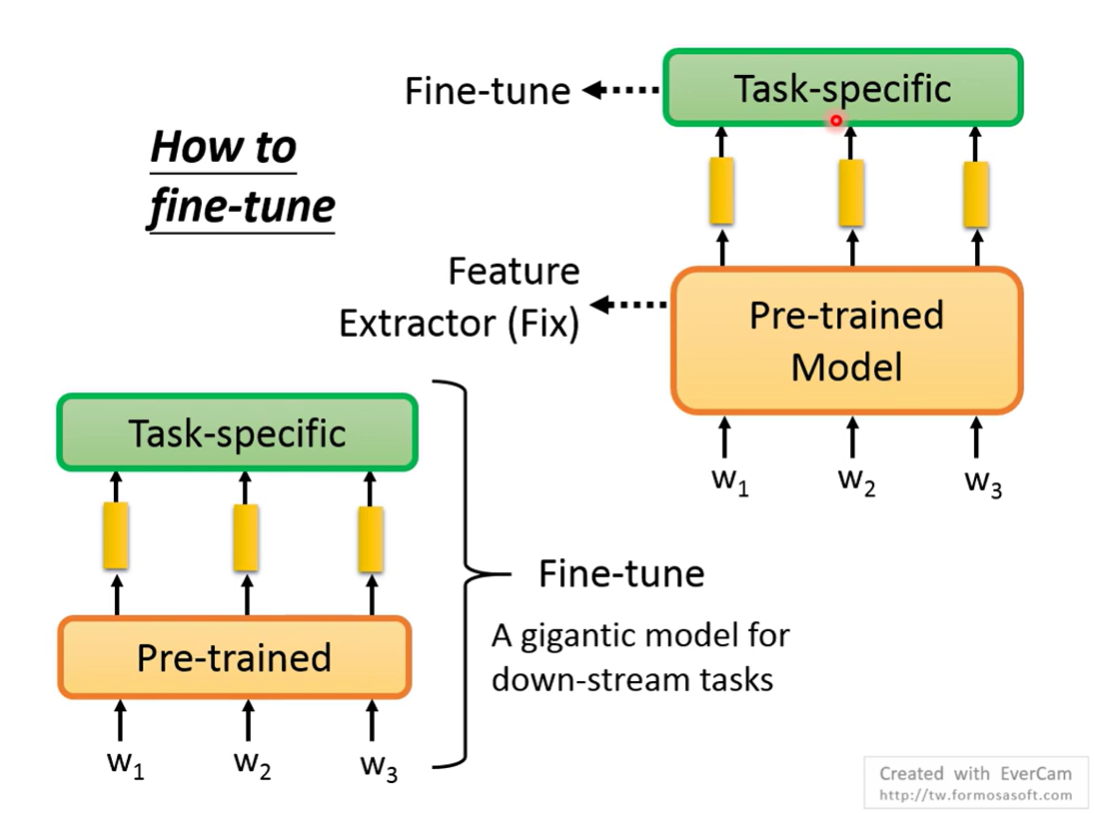
How to fine-tune
远古时期的微调是什么样的
在BERT中有两种方法,一种是只微调线性层/task-specific,固定BERT主体的参数,一种是全部参数微调
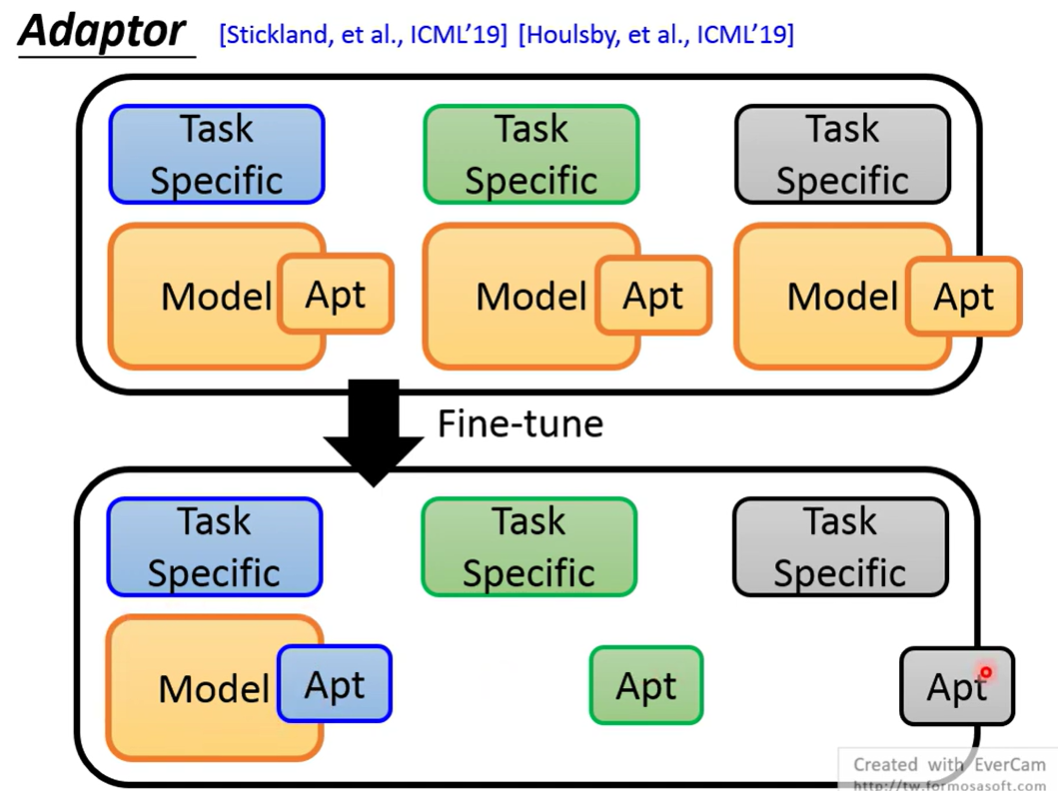
Adapter
只调整一部分参数(加入一些layer,作为Adapter)
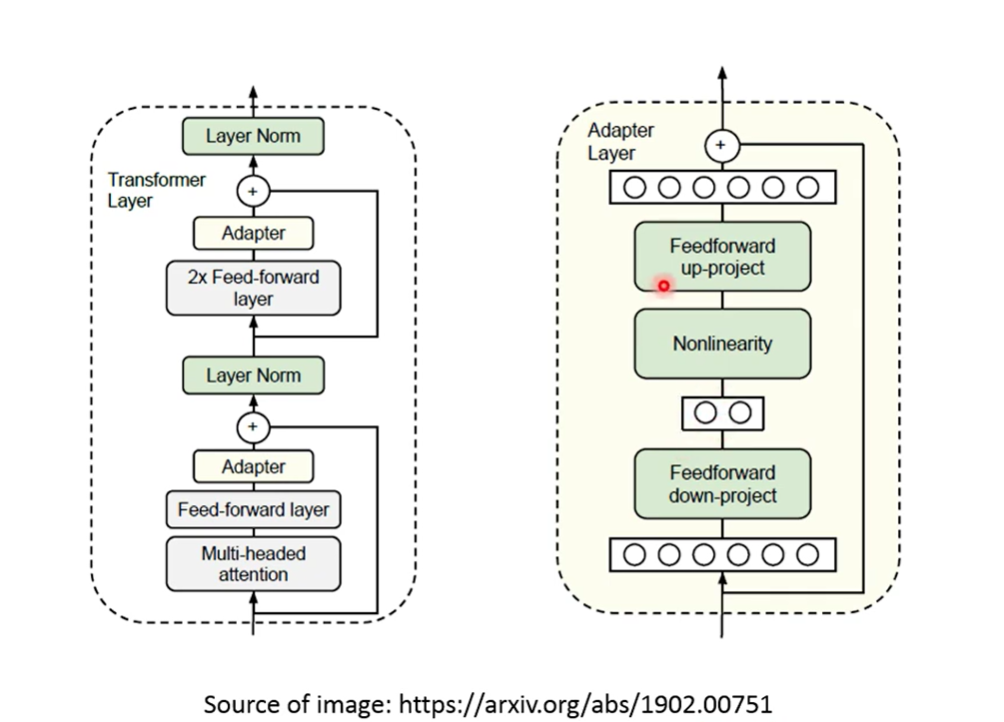
一种可能的adpter方法
将Adapter作为Feed forward放在feedforward的输出处
Weighted features
将各个层的输出做一个加权和作为最终输出
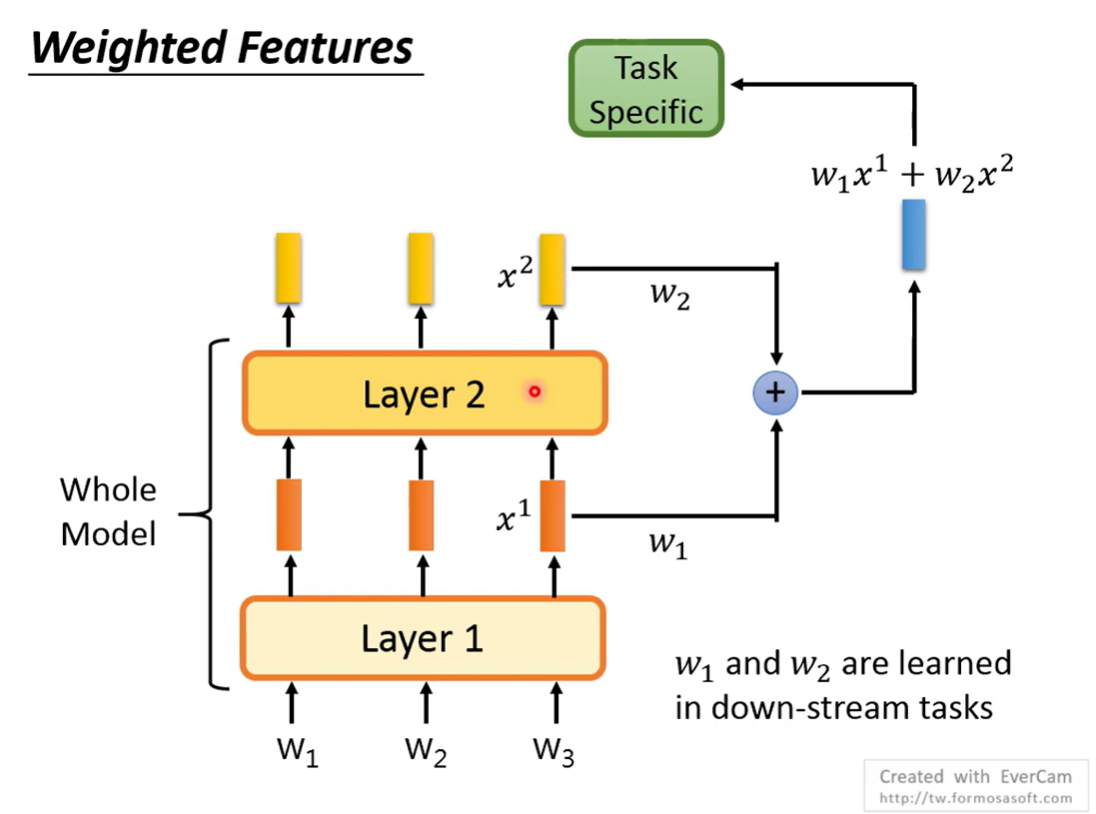
不同任务可以学出不同的weight,也可以当成是一种adapter
How to Pre-train
Predict next token
最早用LSTM(ELMO)
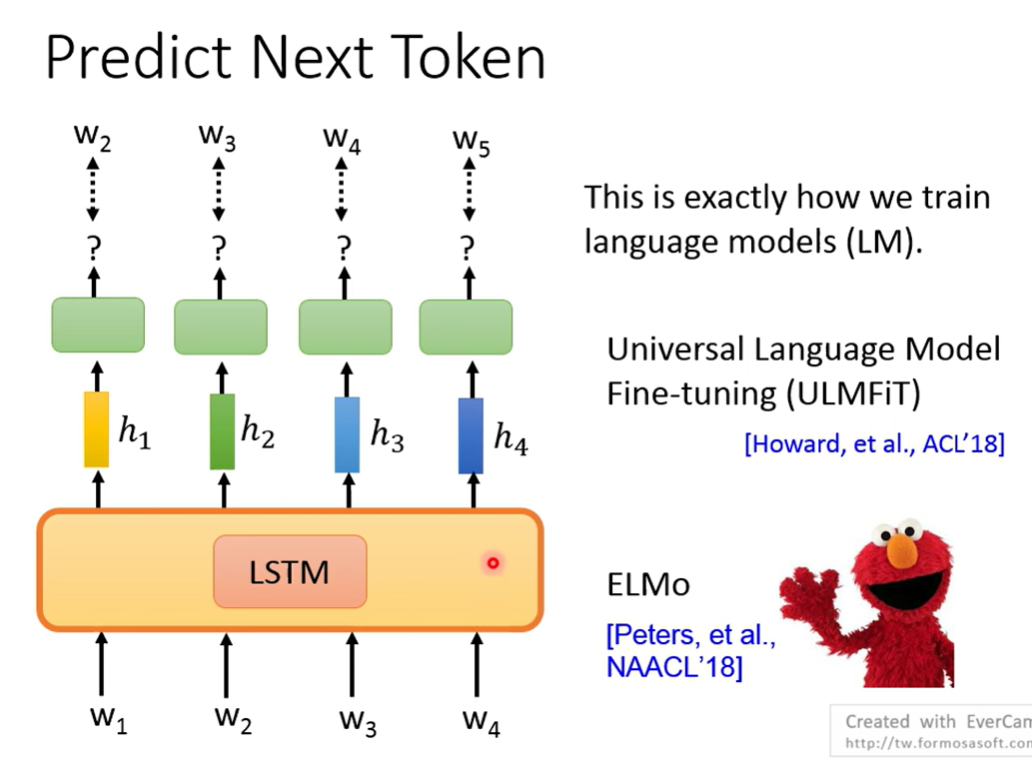
用self-attention
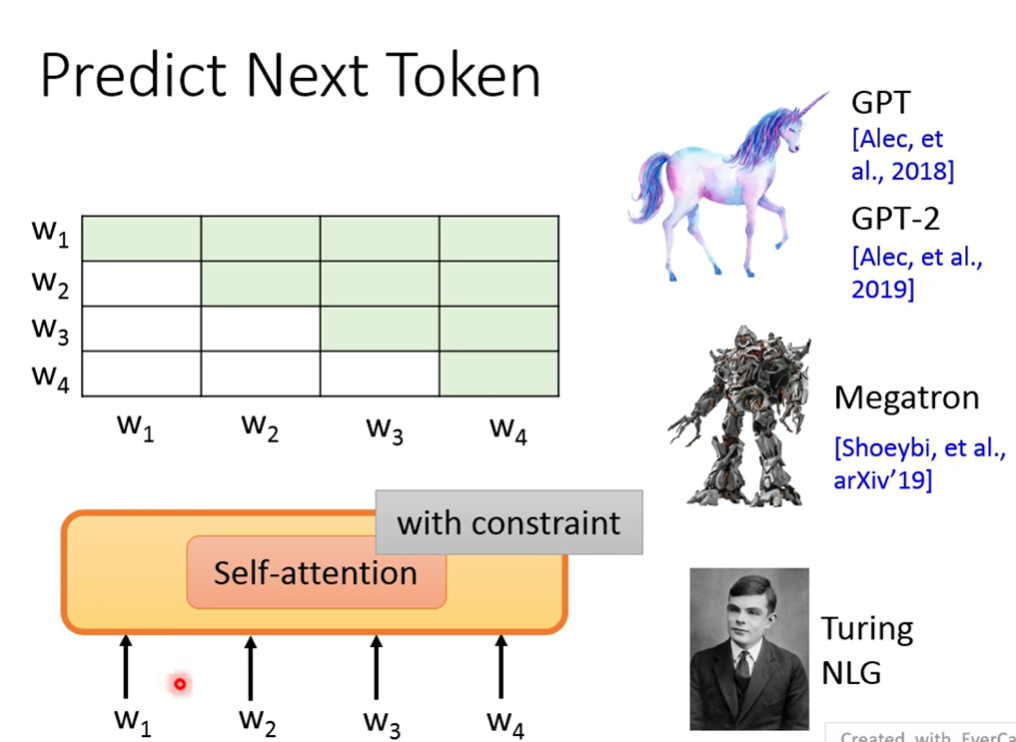
Mask
ELMO是一个双向的LSTM
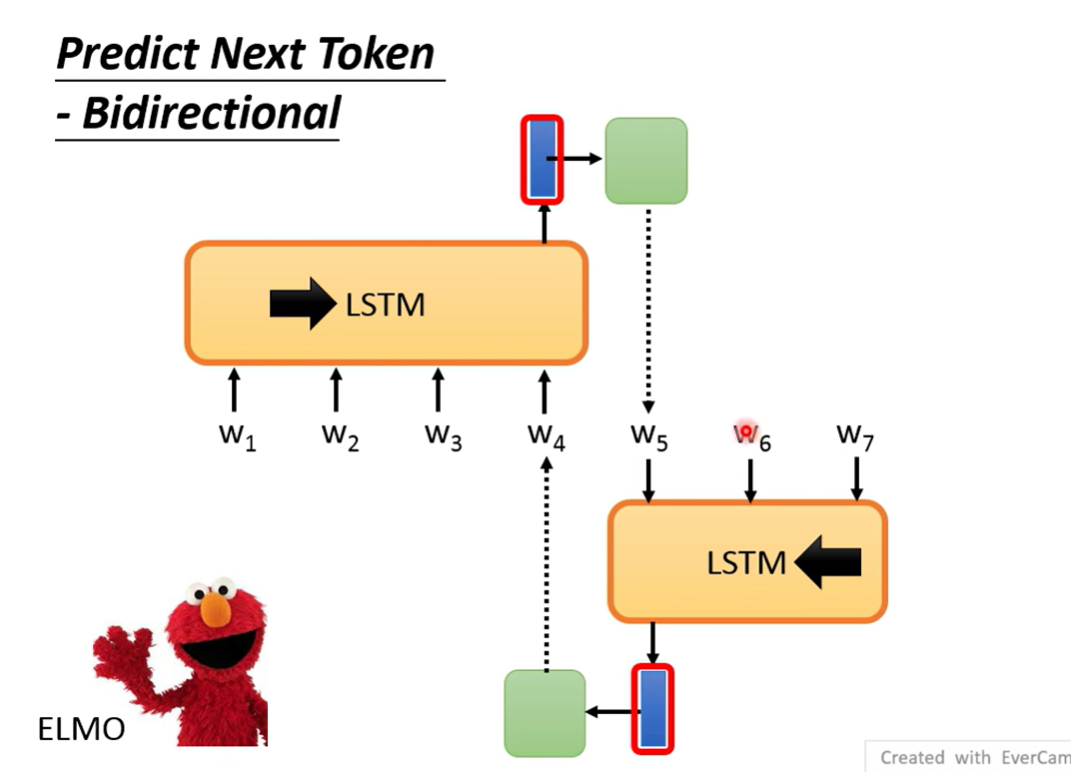
尽管是双向的,但是每个LSTM在单向encode的时候也是没有考虑到另一个方向的信息
所以这样实际上信息也是缺失的
BERT
是进行Mask,做填空
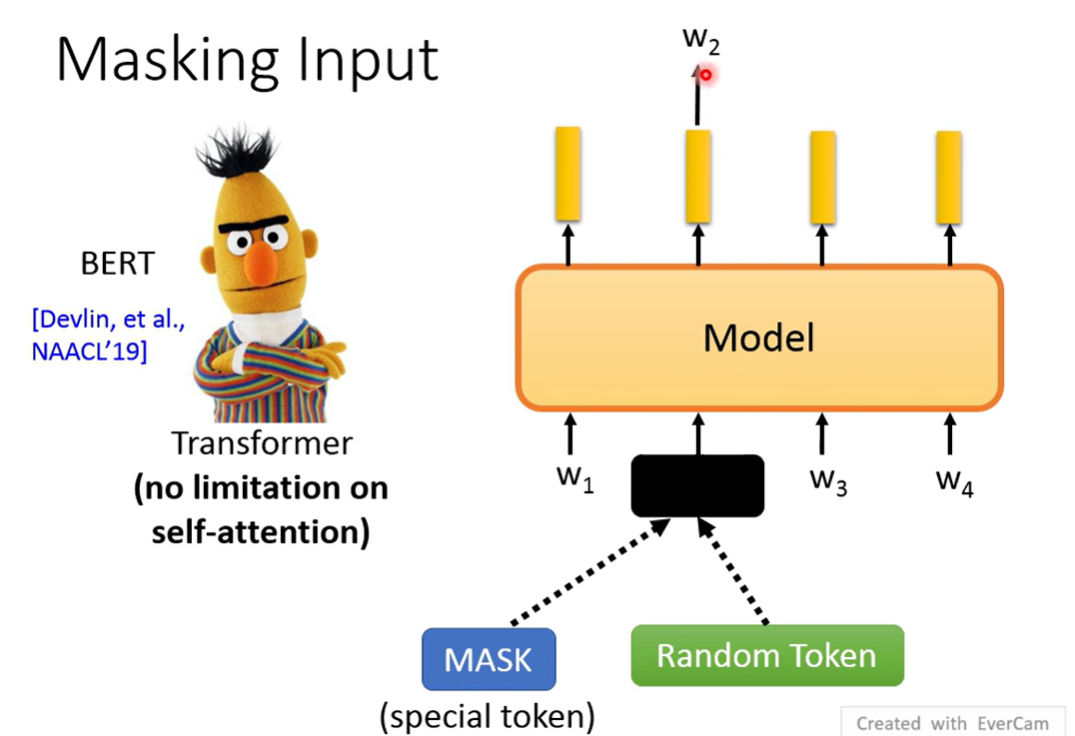
随机Mask可能有些mask不需要全文信息就能猜出
进一步的Mask: Whole Word Masking(WWM), Phrase-level & Entity-level

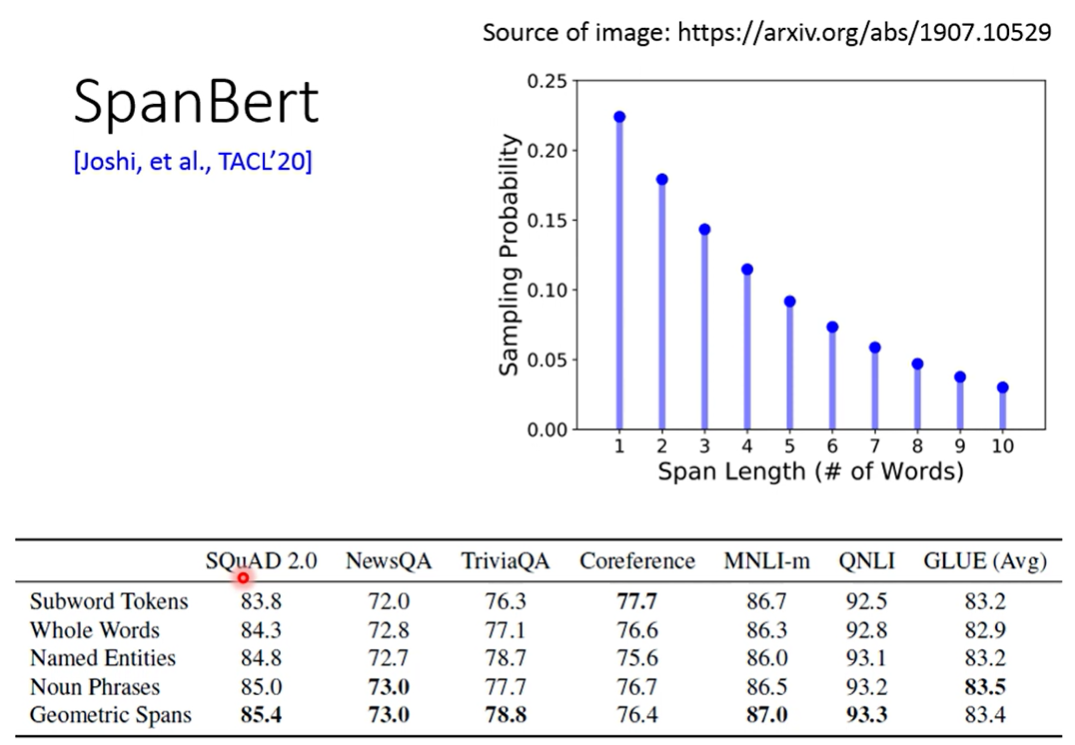
SpanBert
直接按长度盖住(tokens)
还提出了一个训练方法 SBO,拿左右两边的两个token预测中间Masked的某一个token
希望这两个token包含了中间的信息
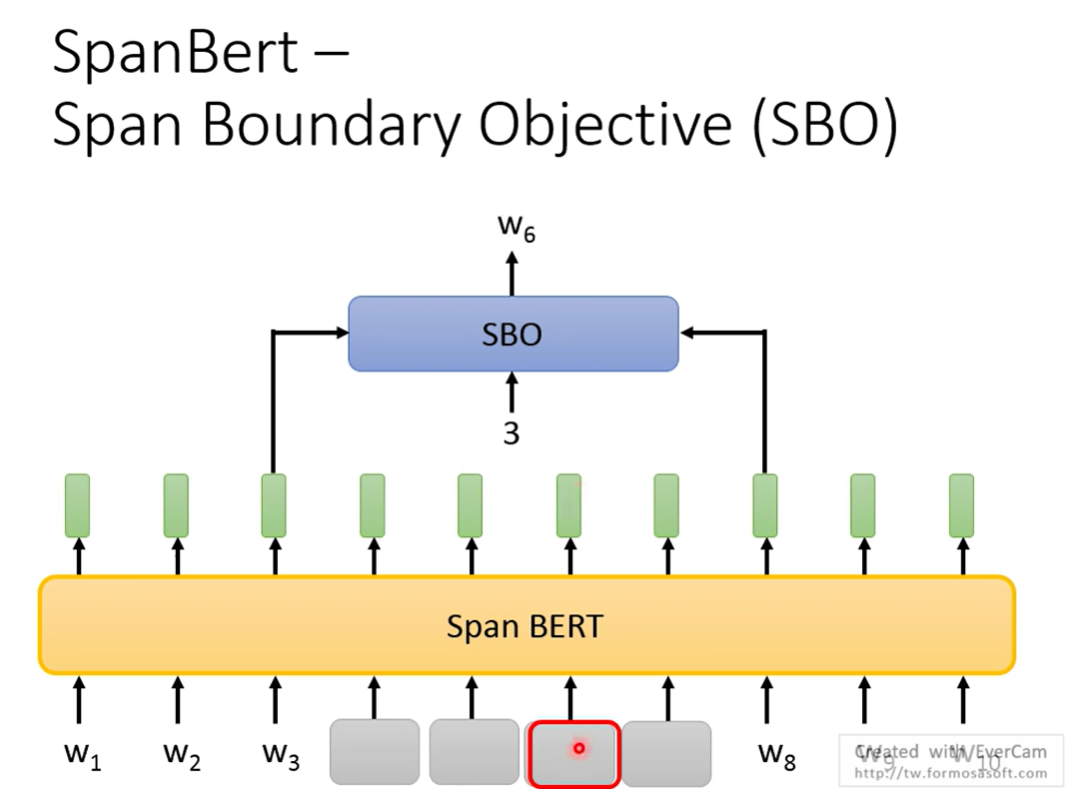
useful in coreference
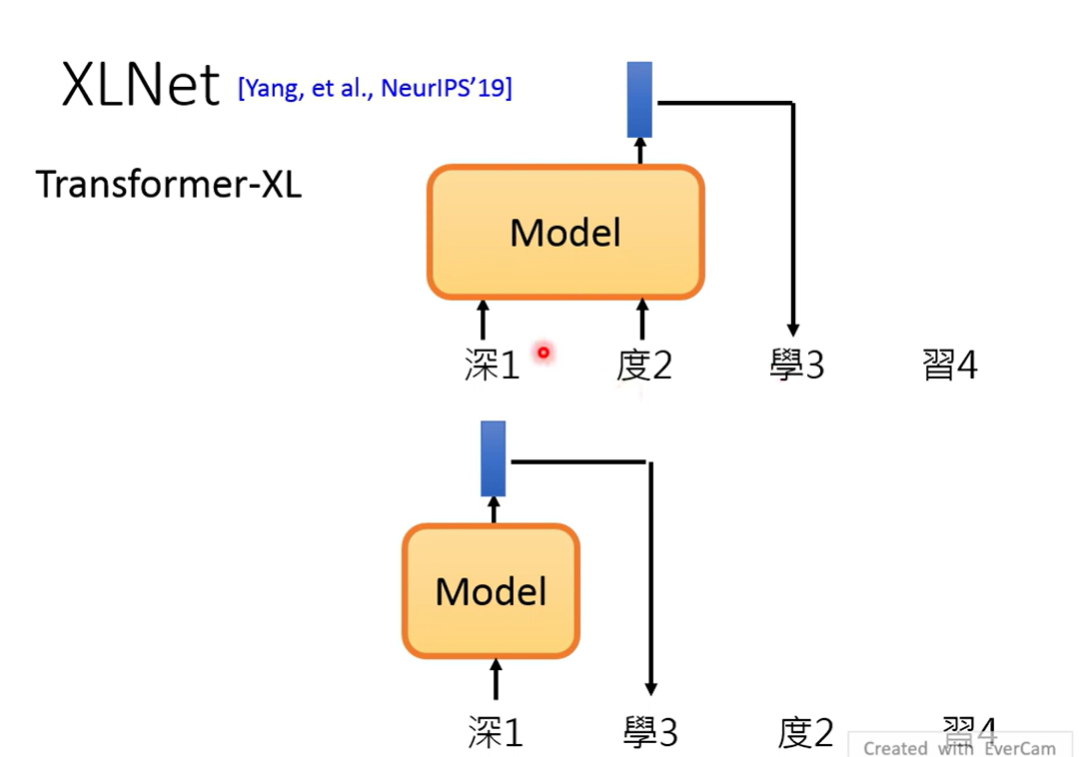
XLNet
使用Transformer-XL
从predict next token来看,XLNet除了原本预测下一个token之外,还随机打乱token,用不同的previous token去预测同一个token
认为这样会更进一步学会token间的关系
从Mask的角度来看,XLNet不是用所有上下文预测一个mask token,而是用随机决定的部分token去决定mask
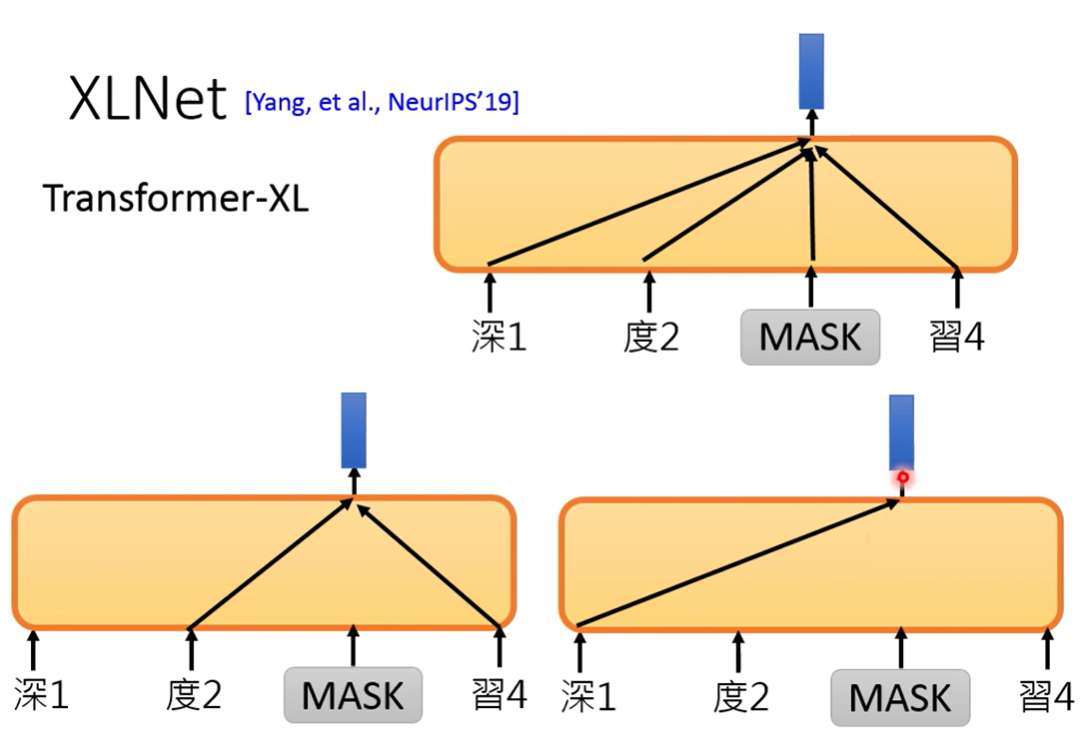
而且没有特殊的Mask的token(说下游任务没有这个token),进行了架构的改进
Next token
BERT并不擅长predict next token
MASS与BART
pre-train seq2seq model
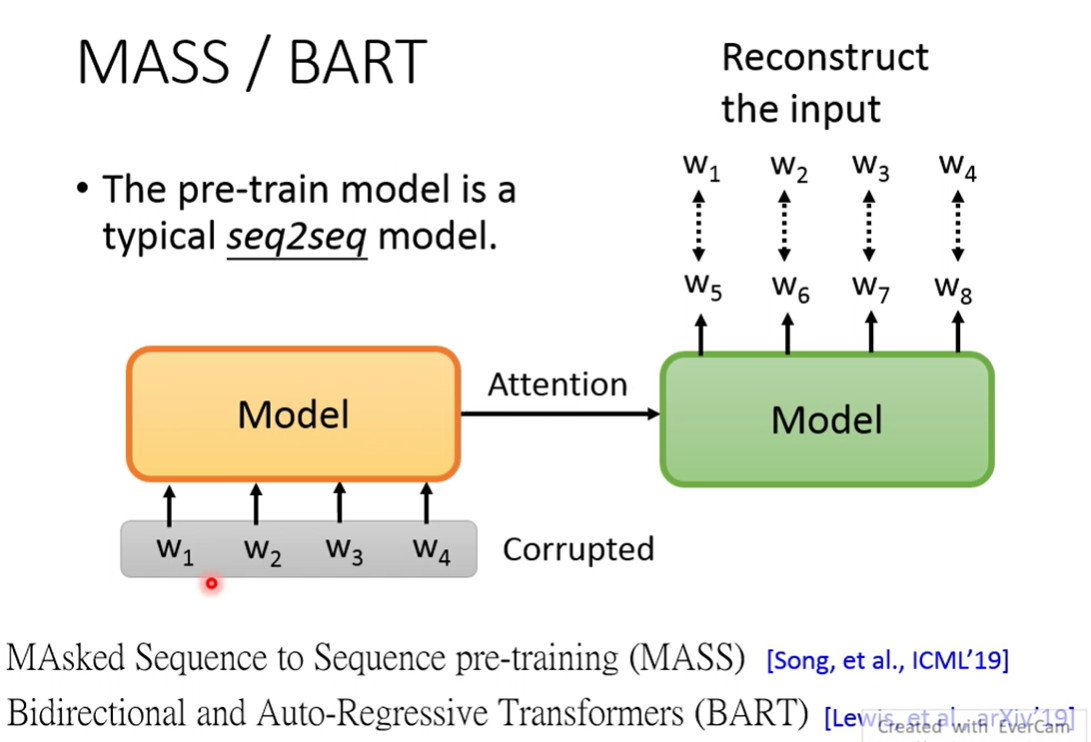
这个任务的输入必须有corrupt(否则模型只需要记住输入就可以)
MASS random mask(原始的paper只需要得到mask掉的部分就行)
BART 试了很多方法
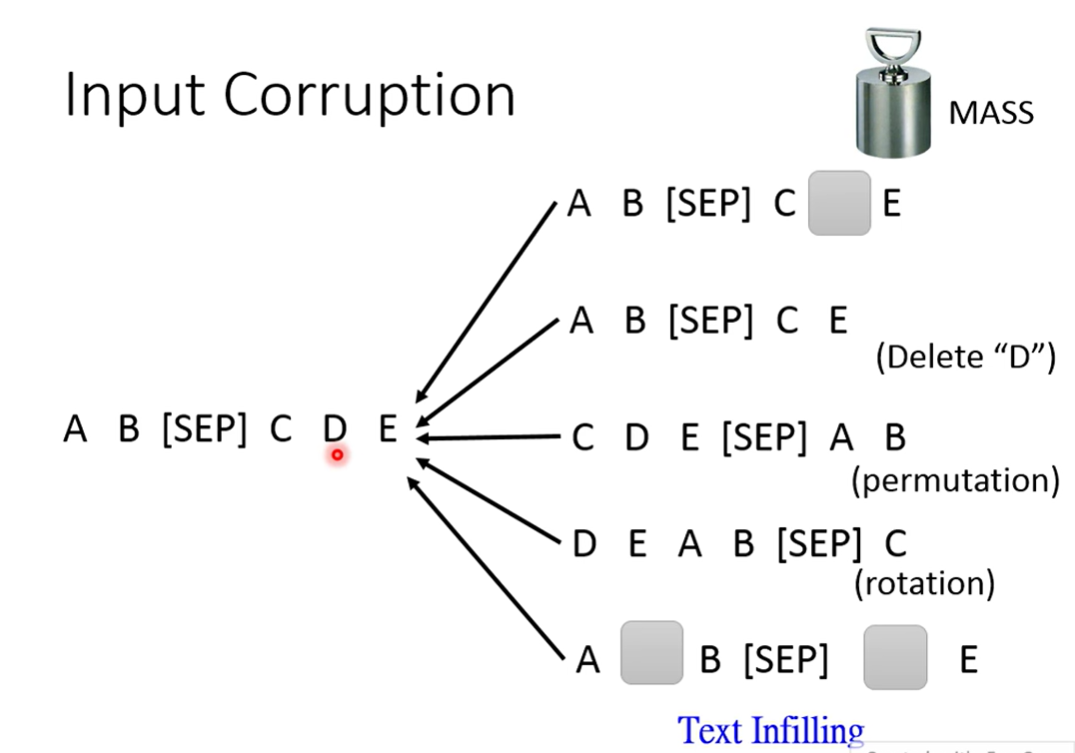
打乱顺序的mask不太work
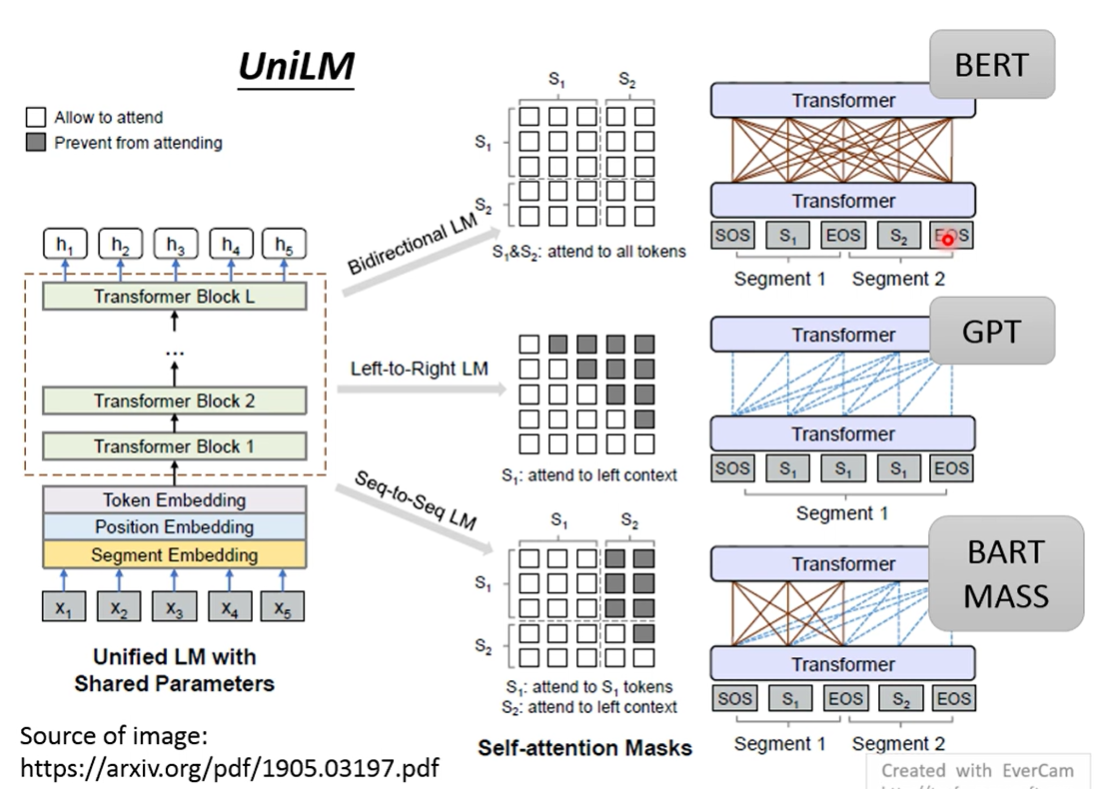
UniLM 同时是一个encoder, decoder, seq2seq
ELECTRA
Binary classify
replace token
判断是否被置换(生成的训练成本太大)
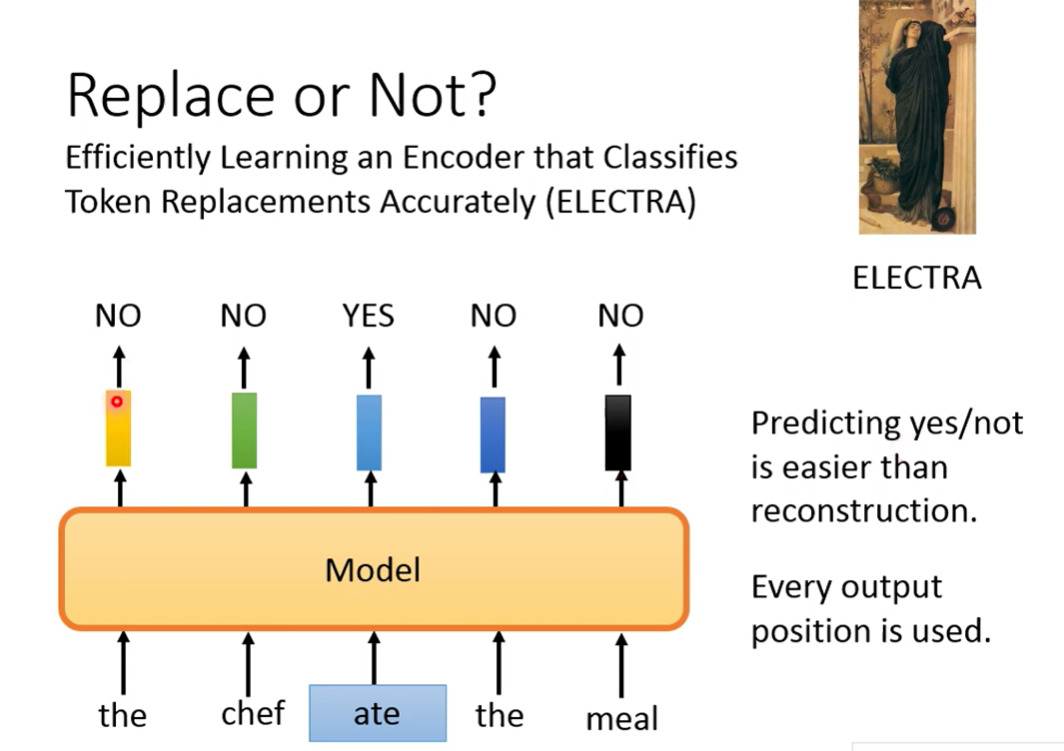
但是这样需要置换的token并不显然(语法上正确之类的),否则变成十分简单的任务
所以引入 small BERT 来进行置换
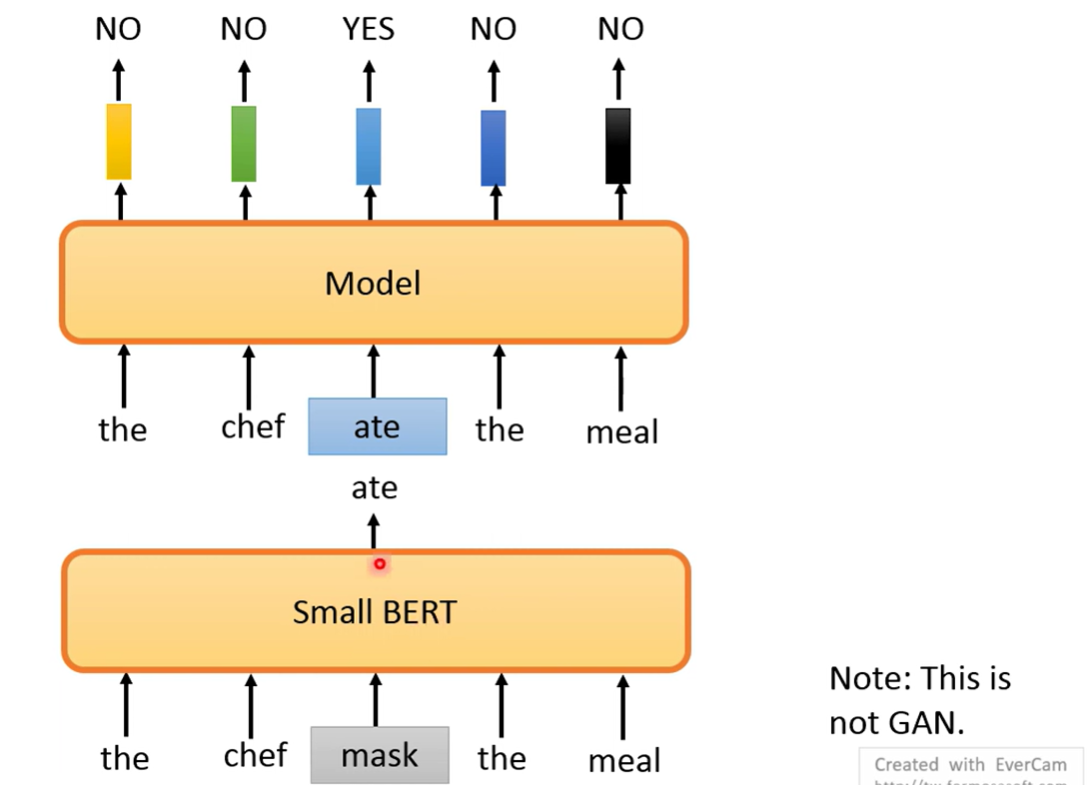
训练成本大幅降低
Sentence Level
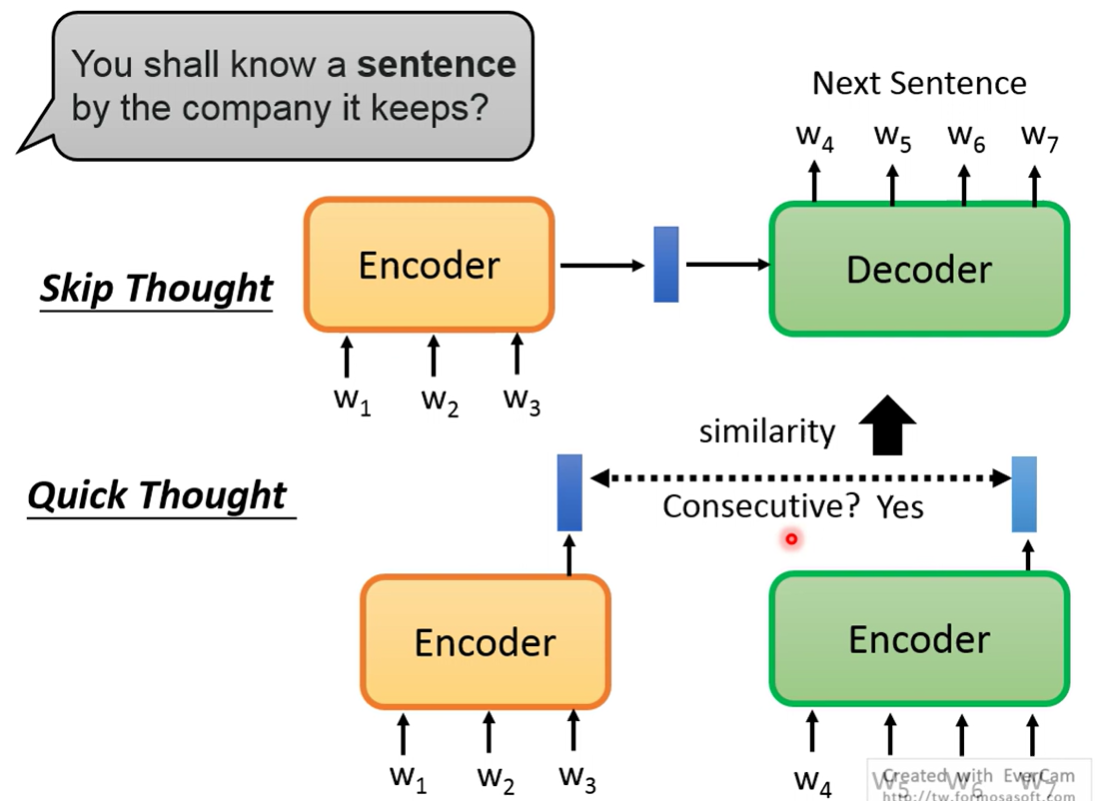
sentence embedding
Skip thought 通过encoder生成embedding,用decoder生成next sentence,如果两个句子都能后接同一个句子,embedding应该会相似
Quick thought 通过两个encoder生成同一个句子的embedding,如果是句子相近要求embedding相近
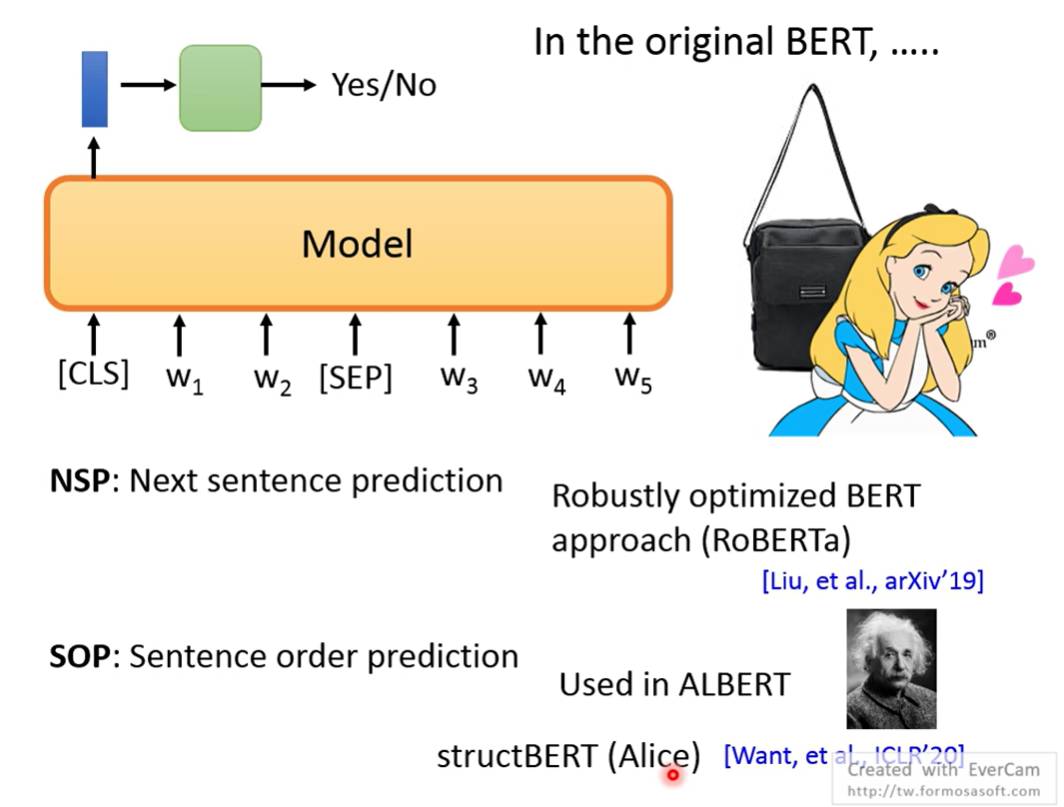
NSP,第一个token预测句子是否相连
SOP,调换句子顺序判断顺序是否正确
Alice,两者结合
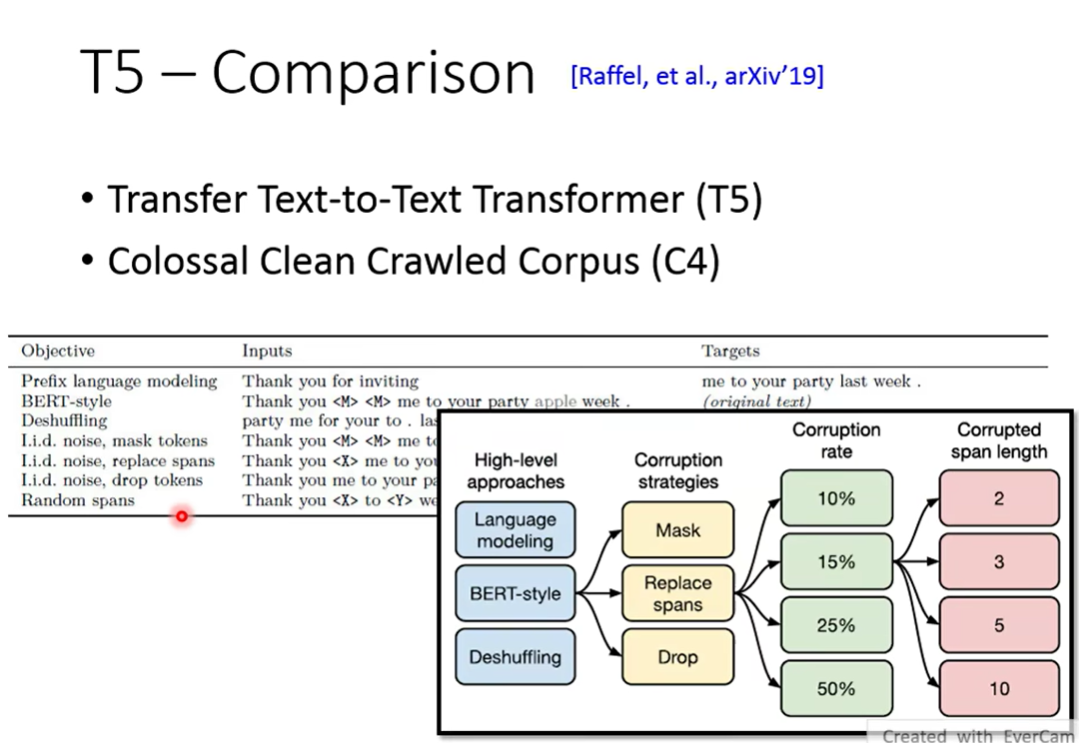
T5 把各种方法pre-train了一遍