2021年的全家桶
BERT
Transformer Encoder
Self-supervised model (a kind of unsupervised)
How BERT self-supervised
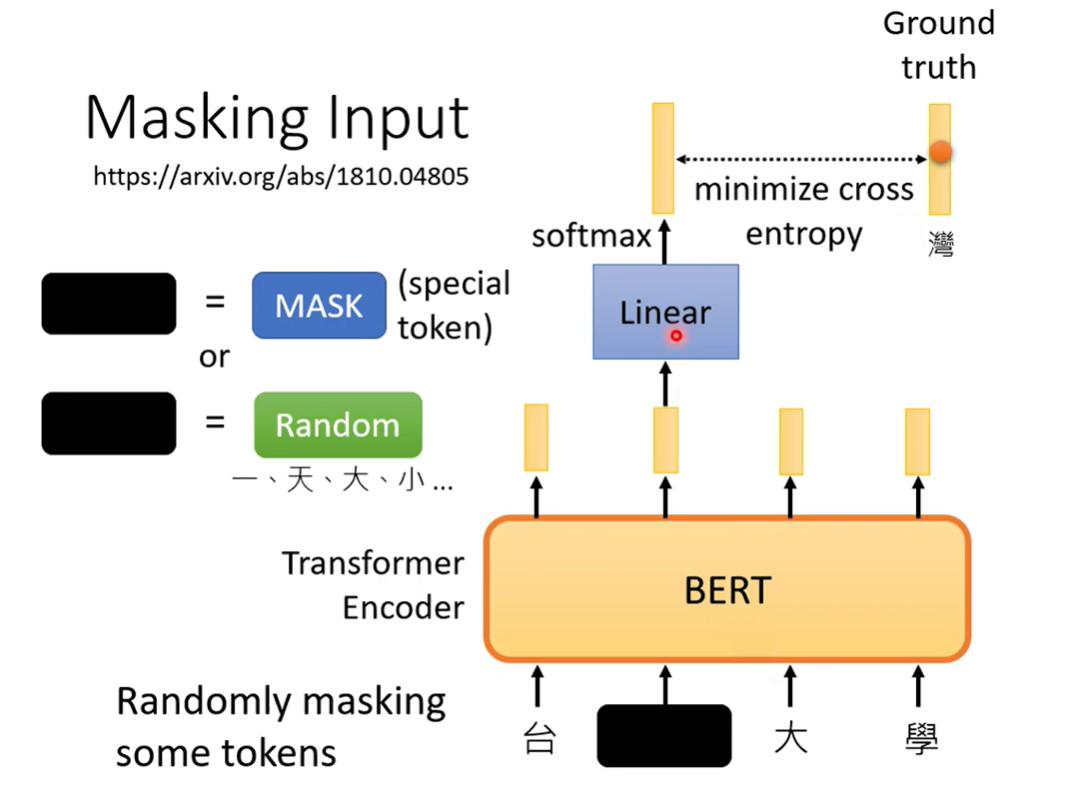
Masking Input
随机掩盖tokens
- 用特殊符号标识 --- MASK
- 随机更换 --- 随机变成另外的token
BERT 输入和输出都是向量的序列,注意线性的transform不包含在BERT中
Next Sentence Prediction
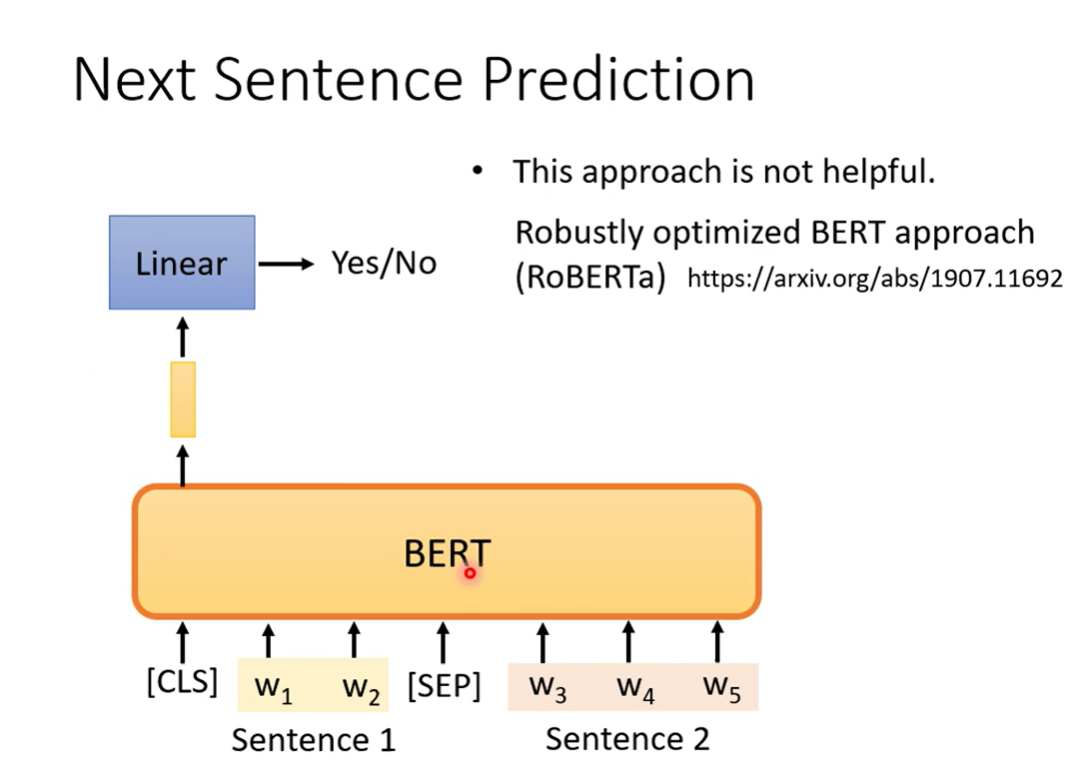
两个句子间用特殊的token隔开,然后用一个特殊token标识开始,只取开始token对应的输出作二分,预测两个句子是否相接
在RoBERTa的论文中,指出这种训练方法没有太多帮助(对BERT的作用没有用)
李宏毅:可能太容易了

一个相近的任务,预测句子的顺序,可能比较有用
Downstream Task
Fine-tune(semi-supervised)
GLUE BERT任务标准 9个下游任务
Case 1 Sequence Classification
sentiment analysis
输入一个序列,通过第一个token的输出判定情感类别
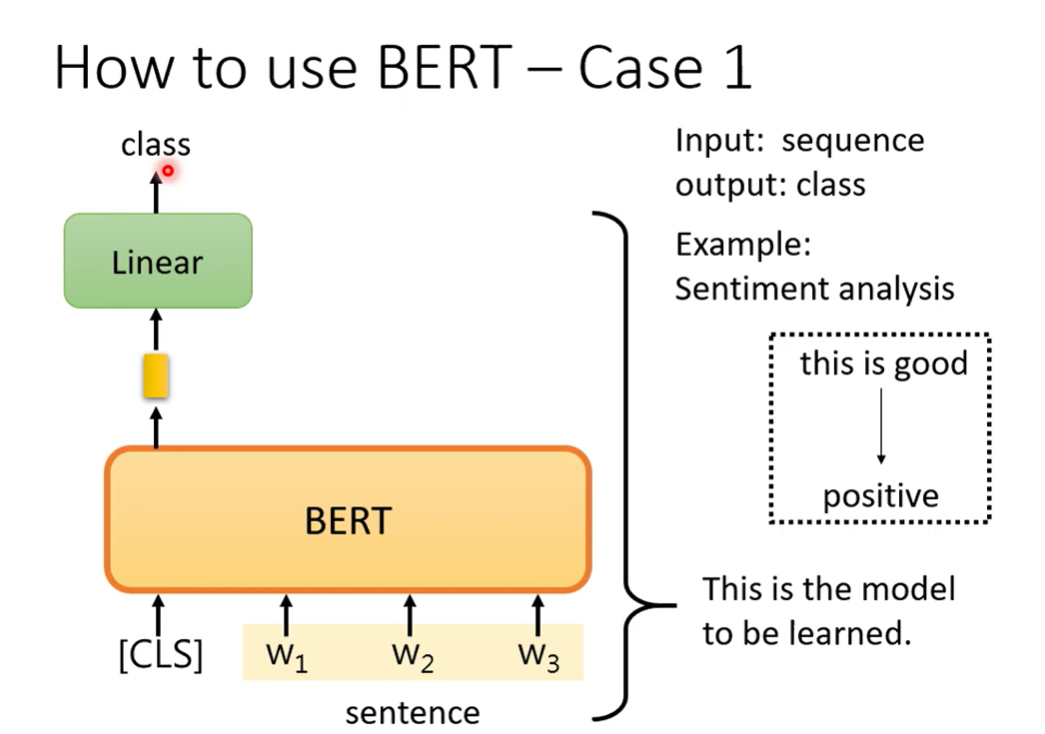
其中 Linear是随机初始化的,BERT是预训练权重
Why pre-train?
Better than training from scratch
Case 2 sequence to sequence(same length)
输入句子,输出句子
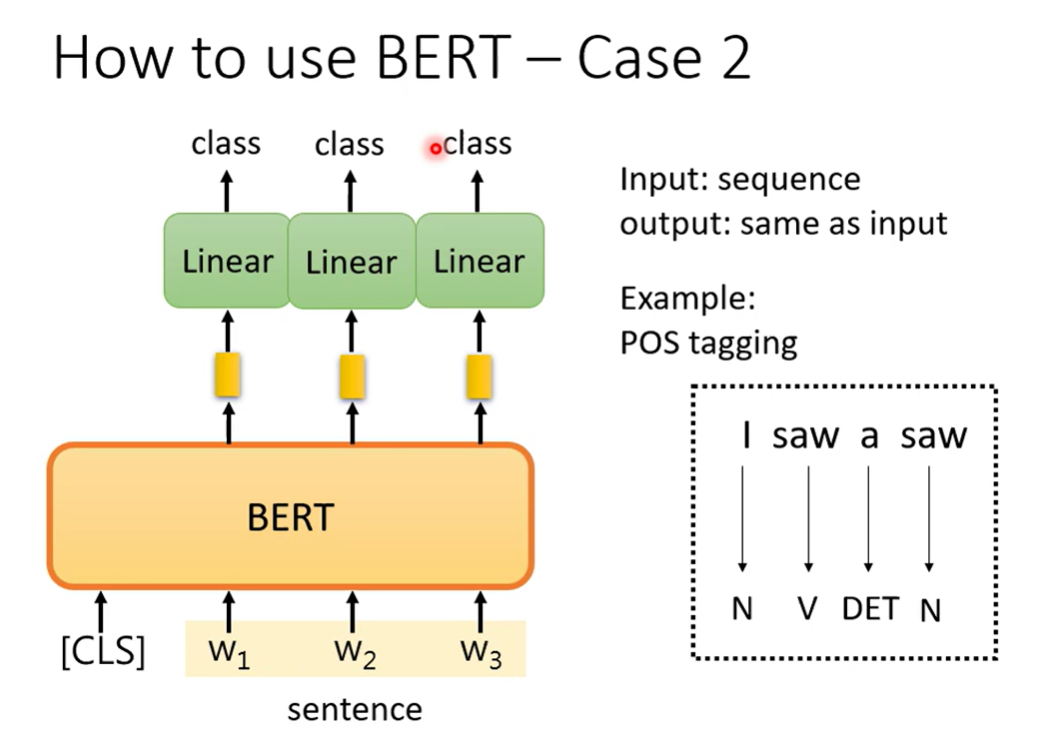
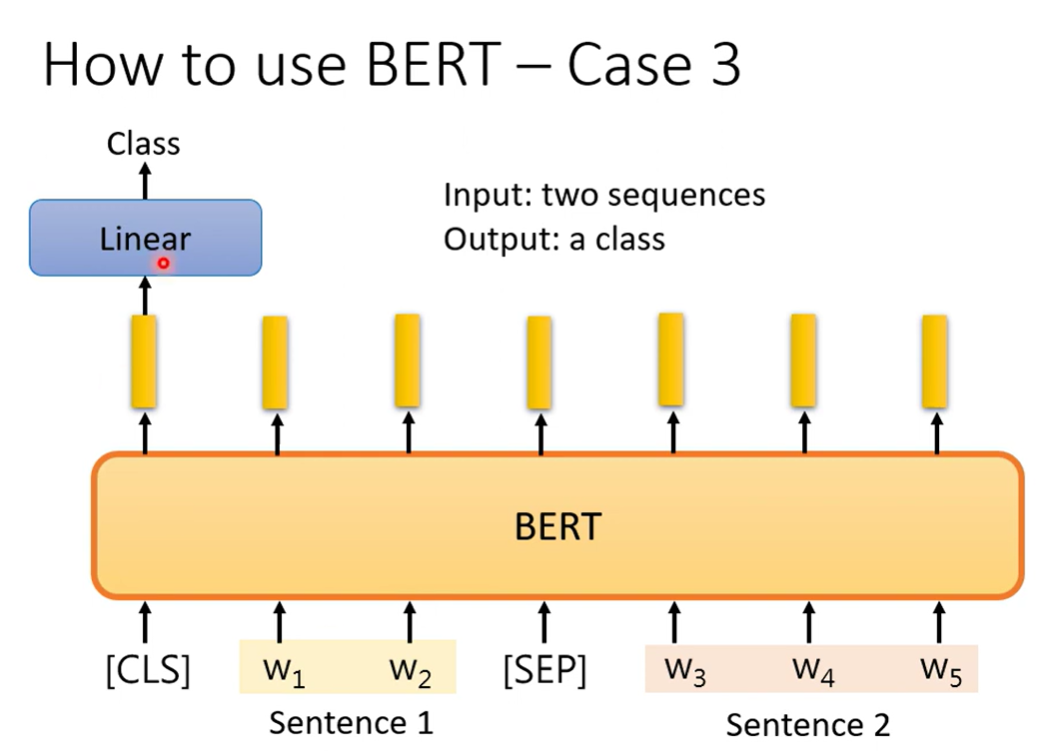
Case 3 Two sequence classification
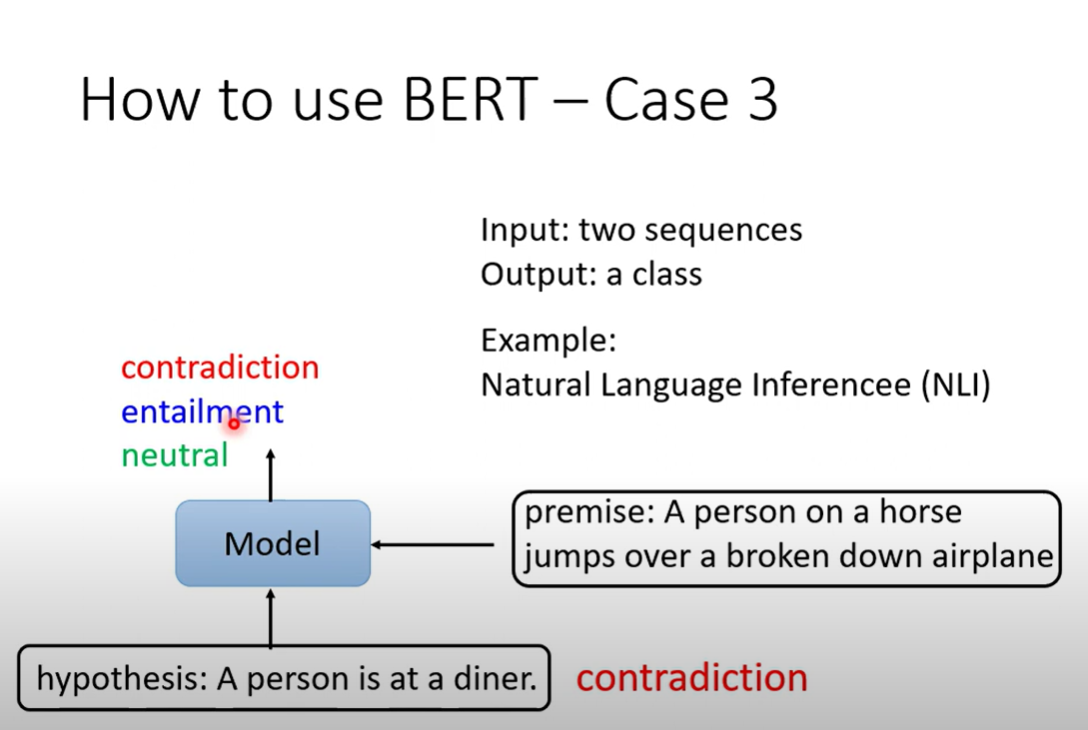
NLI natrual language inference
输入两个句子,输出两个句子的关系
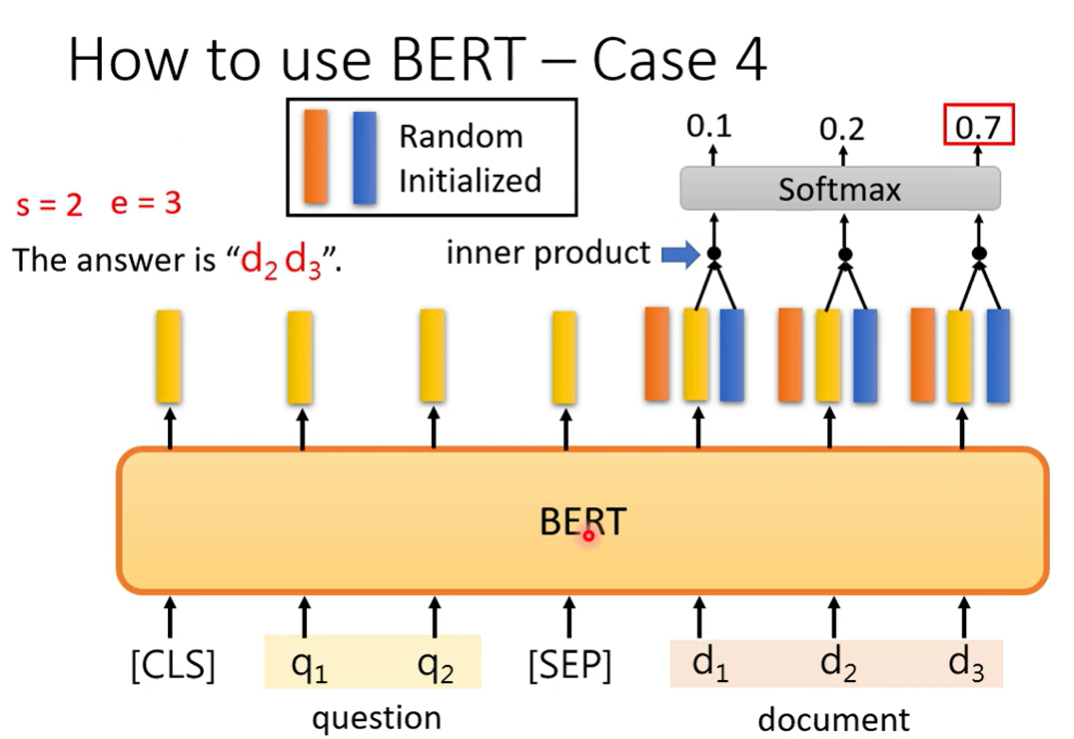
Case 4 Extraction-based QA
从文章中找到答案
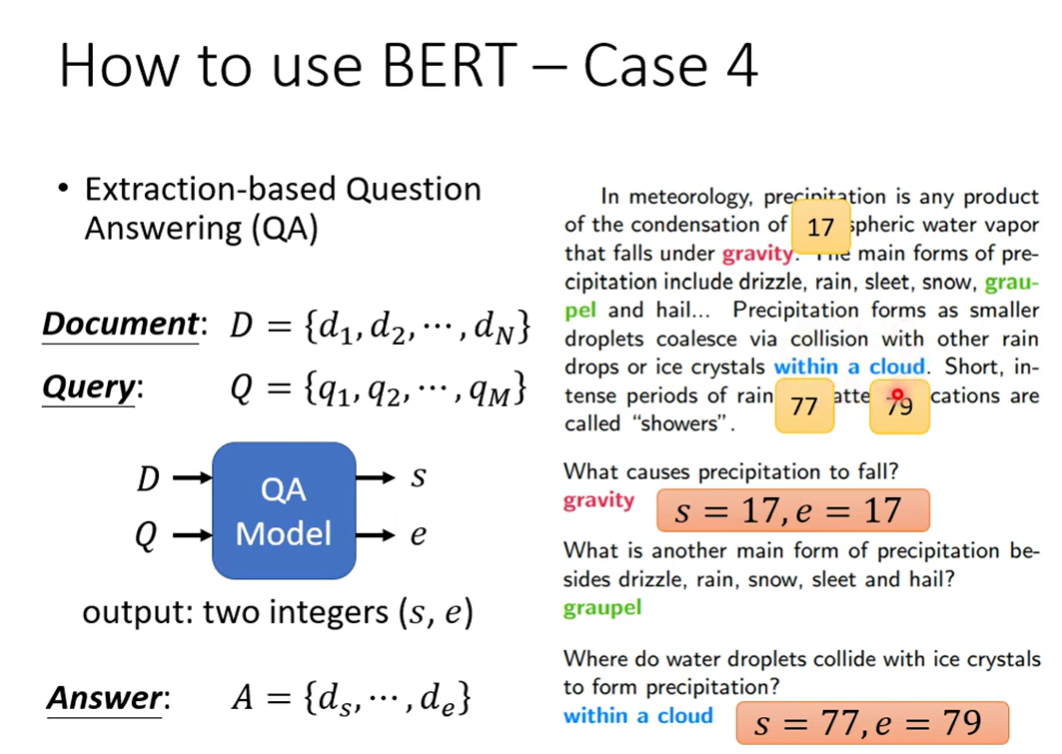
输入一篇文章,一个问题,然后输出两个整数,两个整数之间就是答案
初始化两个向量,与文章的输出作inner product,一个向量分类出起始,另一个模型分类出结束
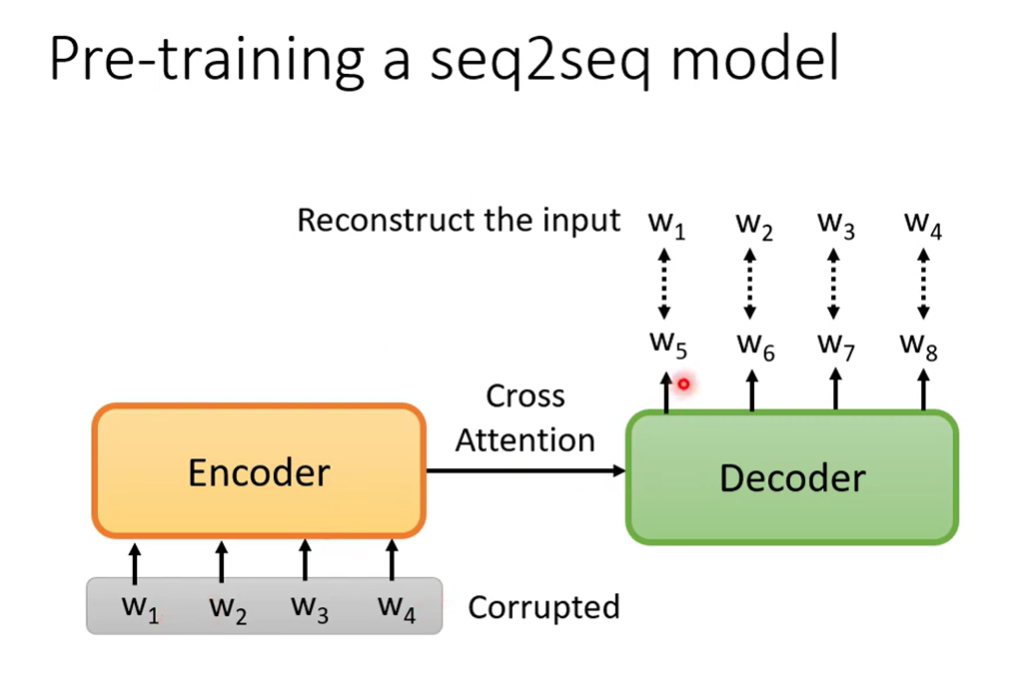
Pre-train seq2seq model
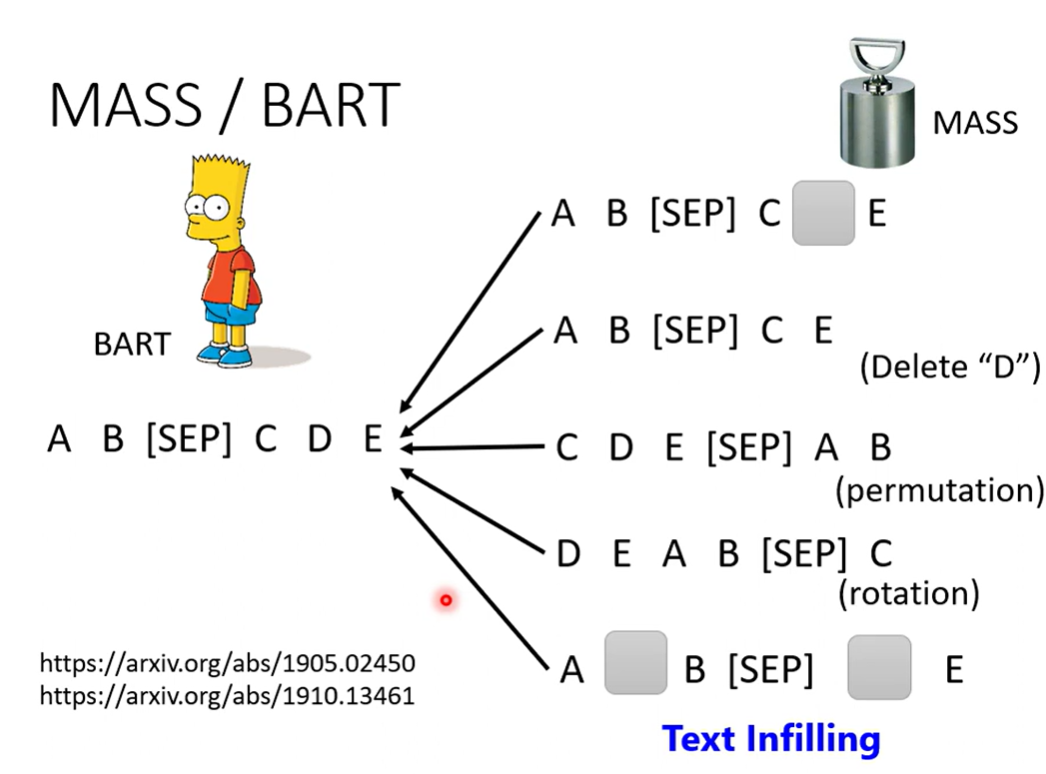
有许多corrupted的方法
T5测试了哪种比较好
Why does BERT work
一种解释是BERT能够输出带有上下文的embedding
同一个words的向量在不同语义中是不同的
GPT
Predict next token
Few-shot learning
没有learning, 但是few shot