虽然标题是PF-ODE,但是废物的我应该从DDPM开始回顾
DDPM是怎么想的
一般认为DDPM是Diffusion开山作
DDPM希望将模型生图的过程拆分为前向加噪过程和反向去噪过程,通过马尔可夫链的假设,DDPM为前向加噪进行建模
在这样的建模中
- 下一个状态只与前一个状态有关
- 基于正态分布,使得前向反向过程都在正态分布的假设下
- 和 的中为超参数,这样的加噪方式能够通过重参数化技巧简化 的计算
然后在反向去噪过程(denoising process)
我们希望能够得到分布 这个分布仍是高斯分布,则我们需要通过模型逐步建模反向过程
关键难点在 ,根据贝叶斯公式,我们需要知道 才能进行计算,即需要完整的数据分布,
我们可以通过加入condition 来进行估计
根据贝叶斯公式,有
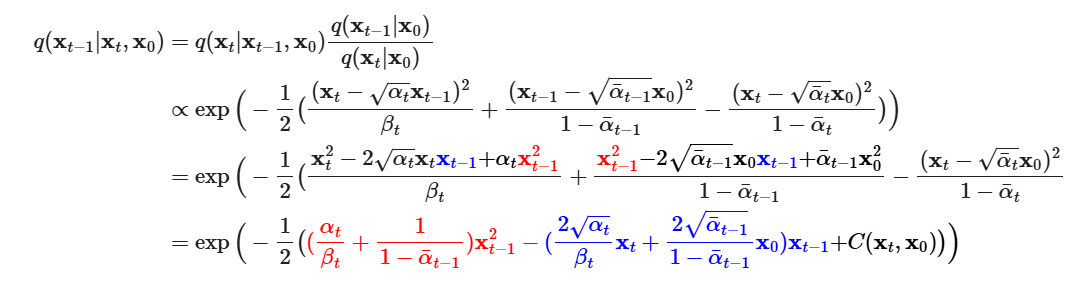
由此得到方差和期望
DDPM固定方差(通过指定),期望直接预测期望来进行预测
根据重参数化trick,进一步得到期望的表达式
此时只有 是未知的,在这里可以直接让模型预测这个噪声,就可以顺理成章地得到DDPM的训练损失和推理过程
但是这样略显草率,更严格来说,我们的目标是极大化似然函数
根据ELBO技巧,我们可以得到
可以拆分成几项KL散度加和
第一项可忽略,重点是中间项,对于已知的高斯分布的KL散度,有解析解,代入得到
DDPM实践中发现化简效果更佳
到这里我们训练了一个模型预测噪声,然后回到上面求出的均值和方差就可以逐步生成
DDIM 又是什么
在上面DDPM的推导中,有一步是 的分布推导。使用重参数化方法之后,我们消去了来求解均值
有一种想法是,如果我们能够通过估计并代入式子的话,是否也可以得到需要求解的结果
则我们希望训练一个模型,用模型的输出 来预估 ,损失设为
再次通过重参数化方法改写 和 (当成 来替换),这样仍然能将推导成类似的损失函数(见苏神生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪 - 科学空间|Scientific Spaces)
这样的做法和DDIM有相似的地方
Diffusion process
按照原论文的说法,DDIM 的核心观察是 DDPM的损失只依赖于forward过程的边际分布 ,而不直接依赖于联合分布 ,实际上应该就是不依赖于
基于此,我们可以尝试改写前向过程为非马尔可夫链形式
根据贝叶斯公式
根据representation trick,有
也有
和反解 得到的 ,代入得到分布
这样贝叶斯公式中的所有分布都已知,此时的前向process依赖于,也就不再是马尔可夫链,这里也可以看到反向过程的分布的随机性由控制, 是不受限制的,当趋近于0时,整个过程趋于确定
Generative process
就像上面DDPM 苏神的一个角度中说的,我们考虑能不能直接预测来建模
根据重参数化方法+使用模型预测噪声,我们可以得到
将其代入反向过程,得到decode distribution
此时我们引入了,改变了两个分布,损失形式仍为VLB,但与DDPM略有不同
论文提到, 当前置的权重系数原本受限于时间,DDIM论文证明当每个,模型参数不共享的话有最优解相同,我的理解是实际训练的时候并不考虑所有时间步而是单个项进行优化,此时无所谓权重系数所以直接取1。在上述定理下,优化和优化有时相同(论文这么说),所以认为二者等价,DDIM可以直接使用DDPM的损失
Speed up
当对所有 取0 的时候,会得到一个implicit probabilistic model(无法显式写出概率密度函数,模型由一个采样过程定义)。
DDIM认为,既然 丝毫不依赖于T时间步的forward process,为何不选取一个T的子集来进行forward 和 generate
定义一个子集 ,每个是increasing的subsequence of
如果 小于 significantly,那么我们就可以极大的减少inference时的computational cost
采样方法是
实际应用时,设置 为
当,与DDPM相同;当时,过程完全确定
另外的,论文设置了两种时间步的采样方法
- linear
- quadratic
- 两种方法的设定都使得最后一个时间步接近于
DDIM论文中给出了ODE的关系,我们先跳过这一段最后再回来看
SDE框架
内容不完全,最好参考这一篇很好的入门博客Diffusion学习笔记(三)——随机微分方程(SDE)
作为一个废物我需要先跟着过一下基础知识,基本是抄下来的,再写一遍帮助自己梳理一下知识
随机微分方程首先涉及了随机过程的微积分概念,所以我们先从连续开始定义
均方微积分
定义3.1:(均方收敛) 设随机变量序列 和随机变量 的二阶矩有限(二次幂的期望存在),若均方极限
称均方收敛于X,记作 ( 为limit in mean square)或
定理3.1:若均方收敛,普通极限(期望的极限)和均方极限(均方极限的期望)在期望下可以交换位置
若
证明:由,可以得到 ,所以有
左右两边取极限,右边根据均方收敛得到0,所以,
定理3.2:若均方收敛,依概率收敛于X
由切比雪夫不等式
左右取极限,由均方收敛和定理3.1可得右边为0,所以, 依概率收敛于
定义3.2:随机过程的均方收敛
随机过程 满足,时
即t取极限时均方收敛
称在处均方连续,进一步地,在每个都均方连续,则在上均方连续
根据定理3.2,均方收敛则概率收敛,,当时间给出微小扰动时,扰动后的状态和扰动前有差别的概率趋近于0,体现了随机过程连续性的统计物理意义
定义3.3:定义随机过程极限
若均方极限
存在,则称该极限为在处的均方导数,记作,也称均方可导
每一处可导则在T上均方可导,记作 ,也是一个随机过程
均方导数和普通导数有相似的性质
定义3.4:定义积分
设随机过程 ,为任意普通函数。将分为n个子区间
记
如果当 趋近于0时, 能均方收敛于,称在T上均方可积,称为在T上的均方积分
定理3.3:若 在上均方可积,则
均方积分满足一些基本定理
牛顿-莱布尼兹公式 (均方可导, 均方连续)
期望计算
定义3.5:n阶线性随机微分方程
设随机过程 与 为随机过程, 的 n 阶均方方导数 存在, 为随机变量或常数,则称:
一阶线性微分方程写为
布朗运动
一条直线上,对称的随机游动,形式化表示为:经过时间,随机地向左或向右移动 个单位,向左或向右概率均为1/2,且每次移动互相独立,记为
令 表示 时刻质点的位置,有,其中 表示不超过 的最大整数
我们希望得到 分布,有 ,所以
说,如果考虑 的情景,,为了令 收敛且数值稳定,一般令 是 的同阶无穷小,即
此时
由中心极限定理可得
所以 趋于正态分布,即,
基于此,定义对于随机过程 ,如果
- 是独立增量过程
则称该随机过程是布朗运动,记为 (或维纳过程, )
若 ,称标准布朗运动
布朗运动是基于随机游走定义的,(时间间隔非常小时)服从正态分布,方差为 ,时间越长位置越不好预测
后续出现的布朗运动应该都是标准布朗运动
Ito积分 和 扩散过程
我们关心布朗运动两个时间节点移动的曲线长度。在随机过程中,可以采用 有界变差 来描述随机运动路径长度
将时间区间进行划分,,即将两个时间点的区间划分为多个时间步,每步的矢量距离为 ,所以曲线长度可近似为
总距离近似为
令 ,布朗运动 的有界变差 为
但是布朗运动的有界变差并不存在
定义二阶变差
布朗运动的二阶变差
DFW没有搞懂推导出二阶变差和它的推论目的是什么,暂时跳过
就结论而言,设 为随机过程,若积分
称积分 为 Ito积分
进一步的 形如
称为积分形式Ito随机微分方程
称为微分形式Ito随机微分方程或Ito过程或漂移布朗运动或扩散方程
扩散方程中, (与构成一阶均方微分方程)一项给出了下一时刻与当前时刻的确定性关系,中由于布朗运动,该项相当于噪声项,引入了随机性
Ito积分有一些性质
如期望为0
Ito引理(二元泰勒展开,高阶项可证为0)
Diffusion
回忆diffusion的加噪过程,
这样的加噪过程是离散的,为了应用到SDE中先考虑连续化。在每两个时间步中加入中间操作,不断反复可得连续过程
首先简化问题,考虑加噪过程是线性的
对前半项有 (斜率),后半项对标准正态分布采样,本身是离散的比较难连续化。我们已经知道布朗运动,所以可以直接用连续的布朗运动来替换
整个过程为
这里是简化后的随机微分方程,更通用的可以将扩展为 ,则得到了常见的一般形式的微分方程
顺带一提,宋飏博士在score based 论文中提出的扩散过程SDE保留了原有的前向关系式(即具体的加噪过程),称 VP过程 Variance Preserving
每个SDE都对应一个逆向过程,在生成扩散模型漫谈(五):一般框架之SDE篇 - 科学空间|Scientific Spaces中对扩散过程逆向SDE有一个简单的证明
扩散模型的逆向SDE为
直接求解过于困难,我们可以通过采样,离散化来求解,这种方法称为Euler-Maruyama Method
我们从标准正态分布采样 ,通过上式不断求解。
但是实际上 是不知道的,也就是score function未知,我们需要通过模型拟合,使用得分匹配算法
等价于引入的形式
最后得到采样方法
此处博客提到了这样的采样方法要比基于MCMC的朗之万采样SMLD模型效率更高,前者两个时间步间进行一次采样(调用一次score function),后者需要多次调用
另外的,基于朗之万方程采样的模型可以称为 VE(Variance Exploding) 模型
可以通过其前向过程对应的逆向SDE推导出朗之万方程
Notes
VP 和 VE
DDPM被称为VP(Variance Preserving),即方差紧缩。这是因为DDPM的前向过程为
有一个对的缩放(通过很小的来压制),并通过方差并不大的来进行加噪
而NCSN被称为 VE(Variance Exploding),即方差爆炸。它的前向是它没有缩放,是通过方差很大的 来压制
SDE框架统一了NCSN和DDPM,可证二者实际上完全等价
SDE 最终是通过score function来进行生成过程,对于DDPM来说,DDPM没有训练过预测score,可进一步证明
即实际上二者只是方向不同,可以直接将DDPM迁移到score based的采样方法上
PF-ODE
PF-ODE(Probability flow ODE)
概率流常微分方程
DDIM不考虑前向传播过程,直接考虑边际分布,加速了采样。那SDE有没有类似的做法呢
找到SDE对应的边际分布的方法就是 Fokker-Planck 方程
博客Diffusion学习笔记(四)——概率流ODE(Probability flow ODE)的推导略显复杂,此处记录一下苏神的推导生成扩散模型漫谈(六):一般框架之ODE篇 - 科学空间|Scientific Spaces
首先改变一下记号方便参照原博客
回顾一下SDE的前向
我们希望直接得到SDE对应的边际分布而不是通过逐步考虑随机性来进行采样
我的理解是,每个SDE都对应一个边际分布,之所以有 “分布” 是因为引入了随机性,我们希望像DDIM一样直接得到边际分布来得到一个更泛化的形式
我们可以引入Dirac函数
Dirac函数可以通过求期望来得到分布
我们希望得到描述边际分布的微分方程,或者说得到,则通过Dirac函数问题转化为对求期望(这里得到的实际上是,需要去取极限消去)
另外,Dirac函数还有如下性质
两边求偏导
接下来推导F-P方程
代入得到 的具体形式
泰勒展开
求期望
左右两边除以,取极限得到
对于任意的,如果满足 有以下等价变换
这个变换相当于把换成 ,将换成,二者完全等价
这个新的F-P方程对应于SDE
我们再对比两个SDE
两个F-P方程完全等价,所以两个SDE对应的边际分布是相同的,也就是存在多条不同的路径/前向过程(通过不同的方差),我们就得到了一个DDIM的升级版
此时的逆向SDE为
将置为0,我们得到ODE
称为概率流ODE,中间的 未知,所以需要用模型拟合,也会对应一个神经ODE
代入可以得到其逆向和前向是一致的,我们得到了一个确定性的可逆的过程
这和flow matching一致,这样的做法允许我们进行精确的计算,又由于可逆性允许进行图像编辑等
另外的,对ODE的加速求解方法研究较多,我们也可以使用一些ODE求解方法来进行加速
当为线性时(),得到DDIM
References
- [2006.11239] Denoising Diffusion Probabilistic Models
- [2010.02502] Denoising Diffusion Implicit Models
- [2011.13456] Score-Based Generative Modeling through Stochastic Differential Equations
- Diffusion学习笔记(三)——随机微分方程(SDE)
- Diffusion学习笔记(四)——概率流ODE(Probability flow ODE)
- 生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪 - 科学空间|Scientific Spaces
- 生成扩散模型漫谈(四):DDIM = 高观点DDPM - 科学空间|Scientific Spaces
- 生成扩散模型漫谈(五):一般框架之SDE篇 - 科学空间|Scientific Spaces
- 扩散模型之DDIM