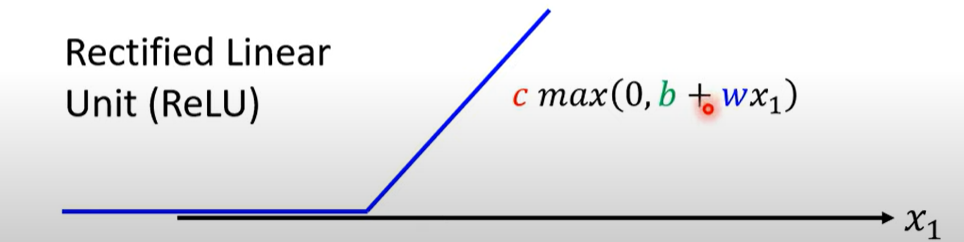
rectified linear activation funtion or ReLU ReLU通过正负区分输入
基本是默认的激活函数
谁大选谁
Limitation of sigmoid and Tanh
Gradient Problems
- 待补
ReLU Activation
avoid vanishing/exploding gradient issues(its gradient is either 0 or 1) but suffers from the dying ReLU problem
- dying ReLU problem — negative inputs lead to inactive neurons
- Cause negative input and 0 output, no gradient no update
- Impact Once a ReLU neuron gets stuck in this state where it only outputs zero, it is unlikely to recover 输出是0,梯度也是0,输入在这个神经元处消除了,而且因为梯度是0权重不会修改,所以神经元不再激活(死去)
- Resulting Issues 可能导致无法拟合
if input > 0:
return input
else:
return 0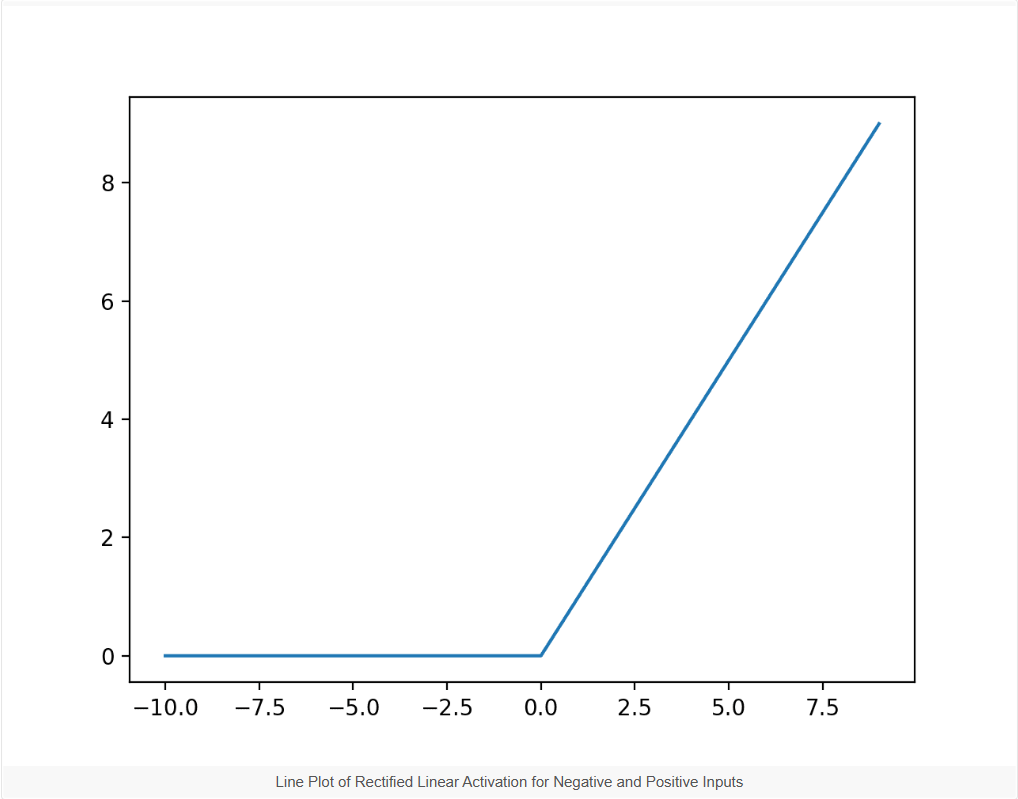
虽然不是光滑的,但是可以认为0处斜率是0
实际使用没有问题
advantages
- Computational Simplicity
return max(0, x)而不是指数计算(sigmoid & tanh)
- Representational Sparsity
- 返回真正的0(0.0) 而不是像sigmoid和tanh一样返回近似值
- allowing the activation of hidden layers in neural networks to contain one or more true zero values. 允许0
- 称为 稀疏表示(sparse representation)
- 这个稀疏表示在autoencoder中比较重要 👈不是很懂,详见deep learning(花书)
- Linear Behavior
- easy to optimize
- avoid vanishing gradients
- Deep networks
tips
- use ReLU as default activation function
- Use with MLPs, CNNs, but probably not RNNs
- 使用ReLU之后网络表现暴涨
- The surprising answer is that using a rectifying non-linearity is the single most important factor in improving the performance of a recognition system.
- When using ReLU with CNNs, they can be used as the activation function on the filter maps themselves, followed then by a pooling layer.
- ReLU were thought to not be appropriate for Recurrent Neural Networks (RNNs) such as the Long Short-Term Memory Network (LSTM) by default
- use smaller bias imput value
- When using ReLU in your network, consider setting the bias to a small value, such as 0.1
- 花书这么写,但是有些争议,可以都试试
- Use “He Weight Initialization” 👈 没看懂 PyTorch中的Xavier以及He权重初始化方法解释_pytorch中he初始化-CSDN博客
- 何恺明也太强了
- Scale Input Data
- standardizing variables to have a zero mean(均值为0) and unit variance(方差为0) or normalizing each value to the scale 0-to-1
- Use Weight Penalty
- ReLU is unbounded in the positive domain
- L1 or L2 vector norm ← 使用L1比较好
Limitations of ReLU
- dying ReLU
- 当大权重或者异常输入时,可能会导致为了拟合实际输出,偏移bias变成很大的负数,可能导致正常的输入也是负的,此时所有输入都是负的,输出就是0,梯度原地消失
Other ReLU
- Leaky ReLU (LReLU or LReL) modifies the function to allow small negative values when the input is less than zero.
- The Exponential Linear Unit, or ELU, is a generalization of the ReLU that uses a parameterized exponential function to transition from the positive to small negative values.
- The Parametric ReLU, or PReLU, learns parameters that control the shape and leaky-ness of the function.
- Maxout is an alternative piecewise linear function that returns the maximum of the inputs, designed to be used in conjunction with the dropout regularization technique.
Leaky ReLU
Leaky ReLU introduces a small gradient for negative inputs
通过调整学习率和评估来调整斜率
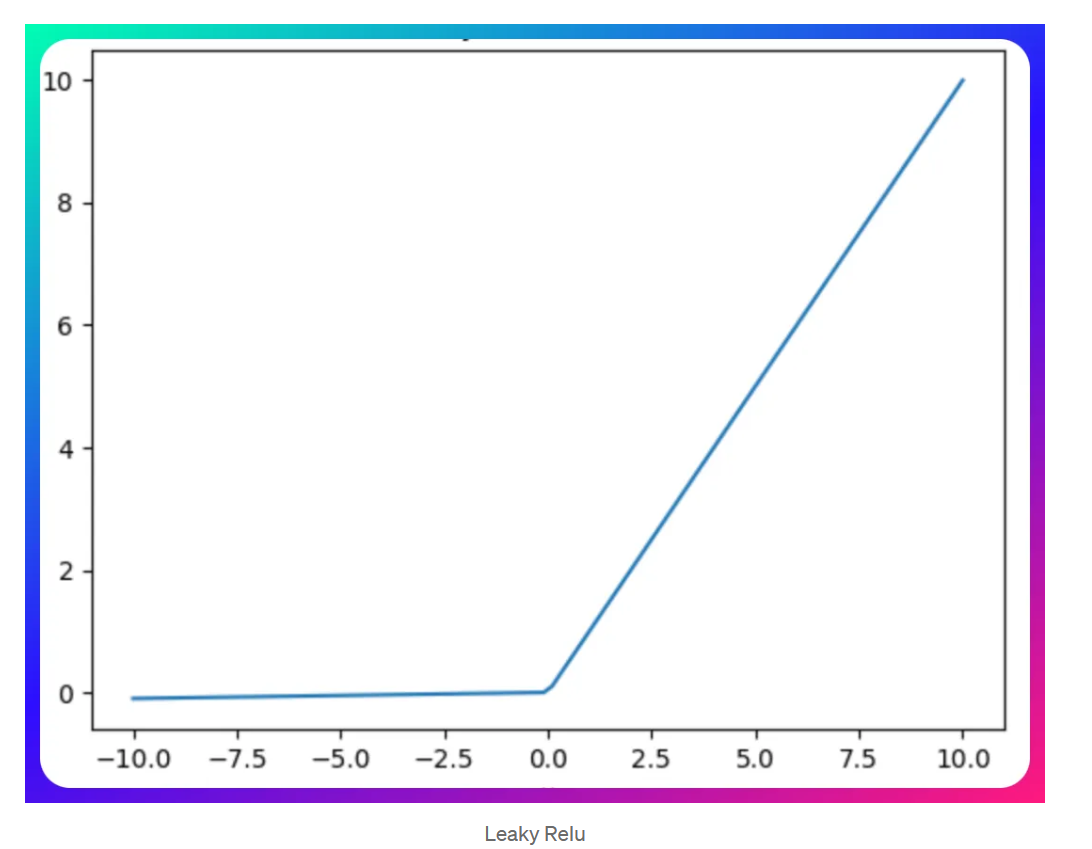
负数部分有一点斜率
disadvantege: Inconsistent output for negative input
Parametric ReLU(PReLU)
with learnable slope parameter
effectiveness in various applications:
- computer vision
- speech recognition 需要fine-tune得到对应的超参数(learnable parameter)
Gaussian Error Linear Unit (GeLU)
probabilistic foundations and smooth approximation characteristics
GeLU is a smooth approximation of the rectifier function, scaling inputs by their percentile rather than their sign
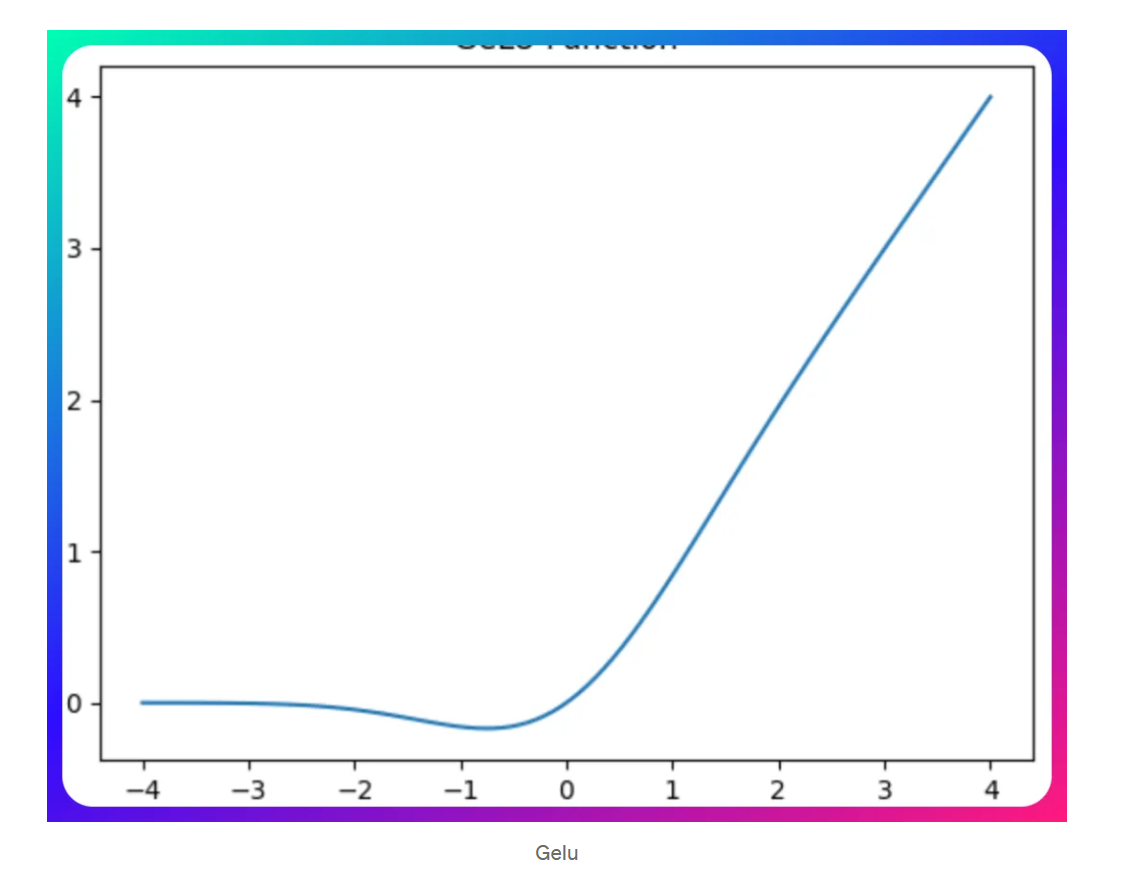
- gained notable popularity in transformer architectures
光滑且非线性,能够很好拟合复杂的模型(CV…)