Overview
分布式训练是指,在多个机器上进行模型训练,每个机器有多张GPU
分布式训练主要分为两种类型:数据并行化(Data Parallel),模型并行化(Model Parallel)
数据并行化
数据并行化指(按照一定的规则)将数据分配到不同的GPU上,每个GPU都复制一份模型,各自训练后将计算结果合并,再进行参数更新
一般用于数据量大,模型能够放在单个GPU上时
当数据量庞大时,使用单张卡训练,计算能力有限,进行一次完整训练需要的时间很长。同时单张卡时只能使用相对小的batch size,由于BatchNorm的使用,模型表现会与batch size正相关,小规模的Batch影响模型表现。此外,基于对比学习的训练算法,由于对负样本的需求,模型性能也与batch size的大小正相关。
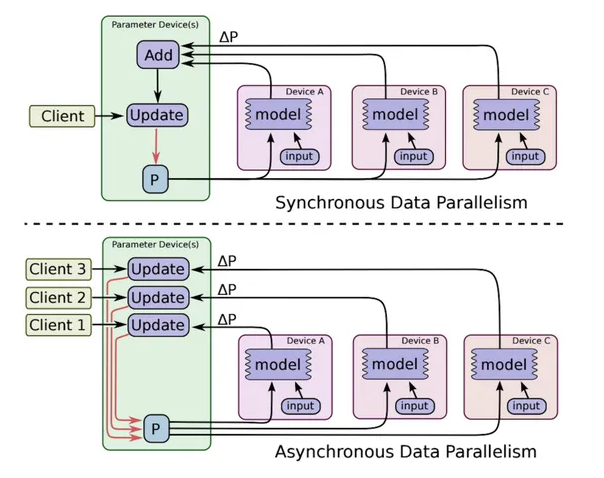
其中参数更新分为同步和异步
- 同步(synchronous): 等待所有GPU计算完毕后再进行参数更新
- 速度较慢,更新参数时合并了所有计算结果,相当于增大了batch size,训练结果较好
- 异步(asynchronous):每个GPU各自进行训练和参数更新
- 速度较快,可能产生Slow and Stale Gradients(梯度失效,梯度过期)问题,影响模型收敛,训练效果较差
Pytorch 中实现数据并行的方法有两种
DataParallel(DP)/Parameter Server
DP不是分布式训练方法,适用于单机多卡
粗浅地说
- 将一块GPU作为server,其余GPU作为worker,每个GPU上复制一份模型进行计算。
- 训练时,将数据拆分到不同的GPU上,每个worker进行计算,将梯度汇总到server上,在server进行模型参数更新,然后将更新后的模型同步到其它GPU上。
- 在数据集不是很大,卡规模小(4块)比较合适
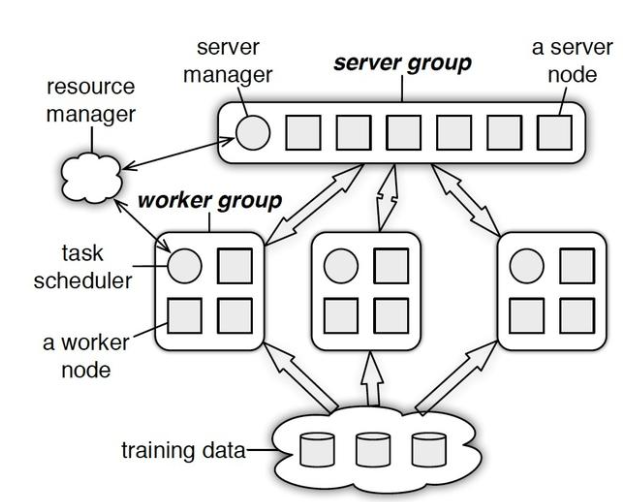
具体地说:
- 分为server group 和 worker group
- server group节点的主要功能是保存模型参数,接受worker节点计算出的局部梯度,汇总计算全局梯度,进行参数更新
- worker节点从server节点处拉去最新参数,计算局部梯度并上传
- PS(parameter server)采用异步非阻断式梯度下降,在进行push&pull的过程种允许继续计算梯度并上传(使用上一次的参数),速度更快,GPU利用率更高,但是可能影响模型收敛
代码只需一行
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)- module 指定模型
- device_ids 指定使用的GPU,不指定使用所有GPU
- output_device 指定输出的GPU
- dim 指定切分数据的维度,默认为0(batch)
model = DataParallel(model, device_ids=[0, 1, 2])更多资料见
- DataParallel — PyTorch 2.5 documentation
- Pytorch 分布式训练 (DP, DDP)_if your script expects `—local-rank` argument to -CSDN博客
- DP, DDP源码解析-知乎
- 一文读懂「Parameter Server」的分布式机器学习训练原理 - 每日头条
缺点:
- 这种方法的瓶颈出现在server,server承担大量的计算和通信任务,随着GPU数量增加,通信开销线性增长
- DP为单进程多线程实现(方便通信,单机多卡),会陷入GIL问题
- 基本弃用
DistributedDataParallel(DDP)/Ring-All-Reduce
Ring-All-Reduce 架构
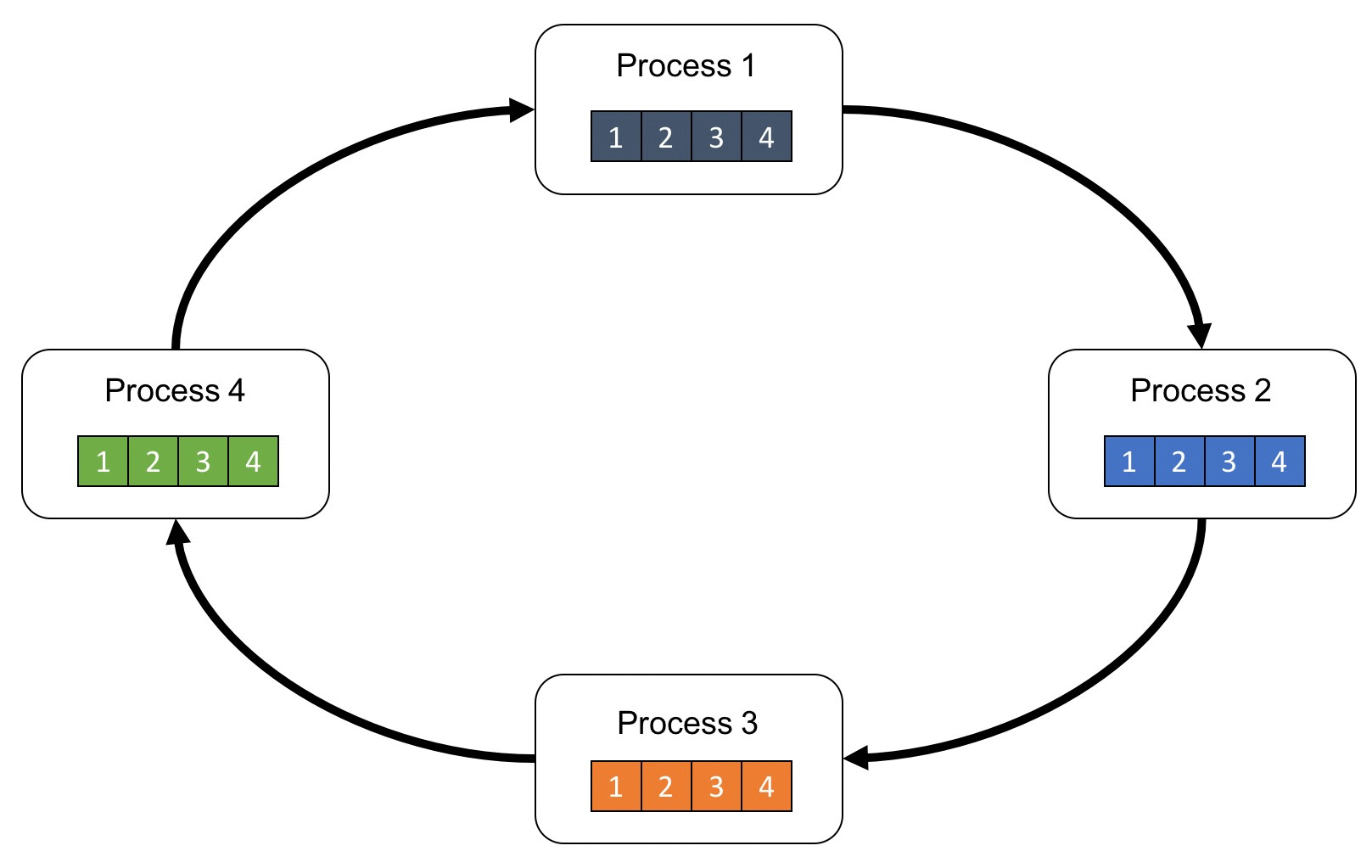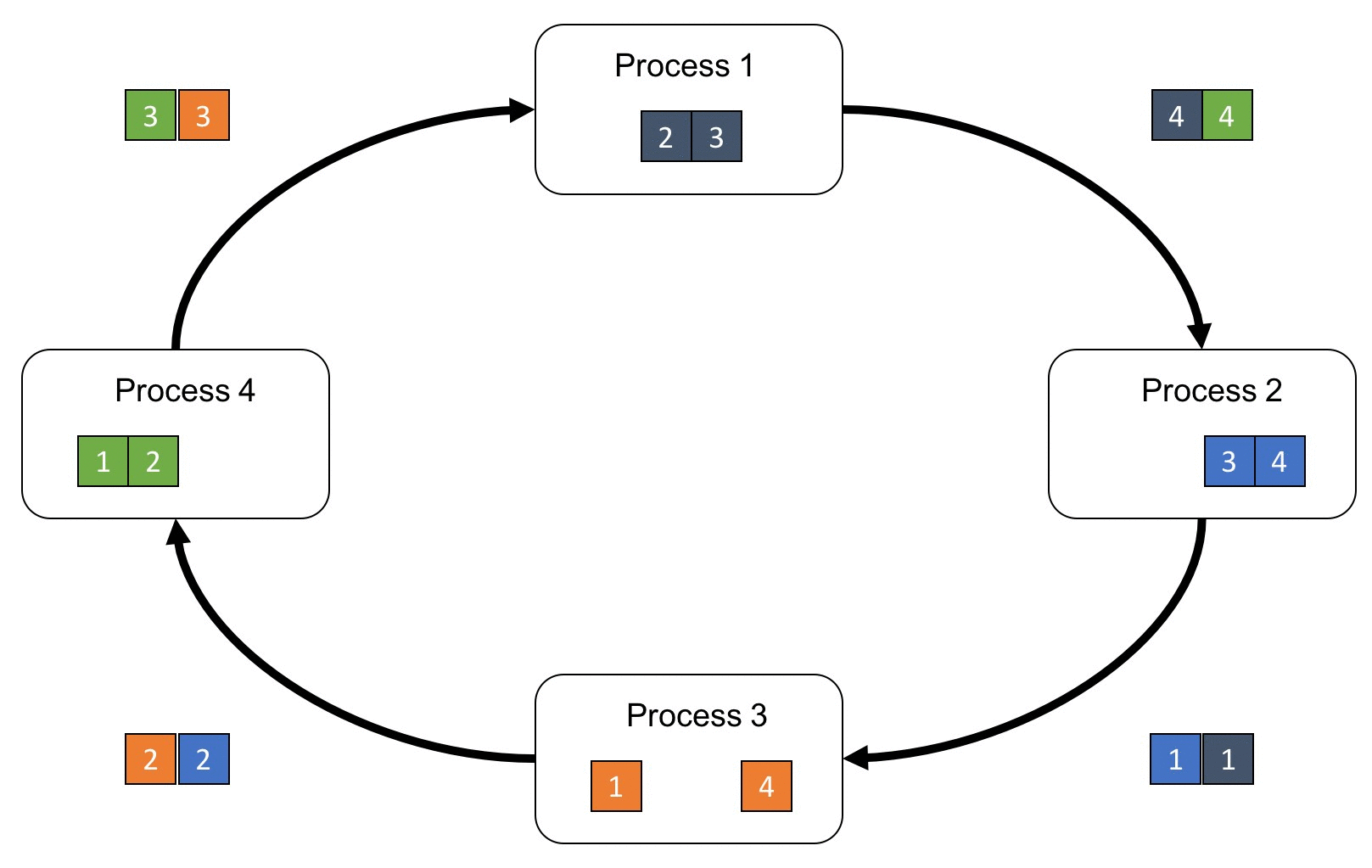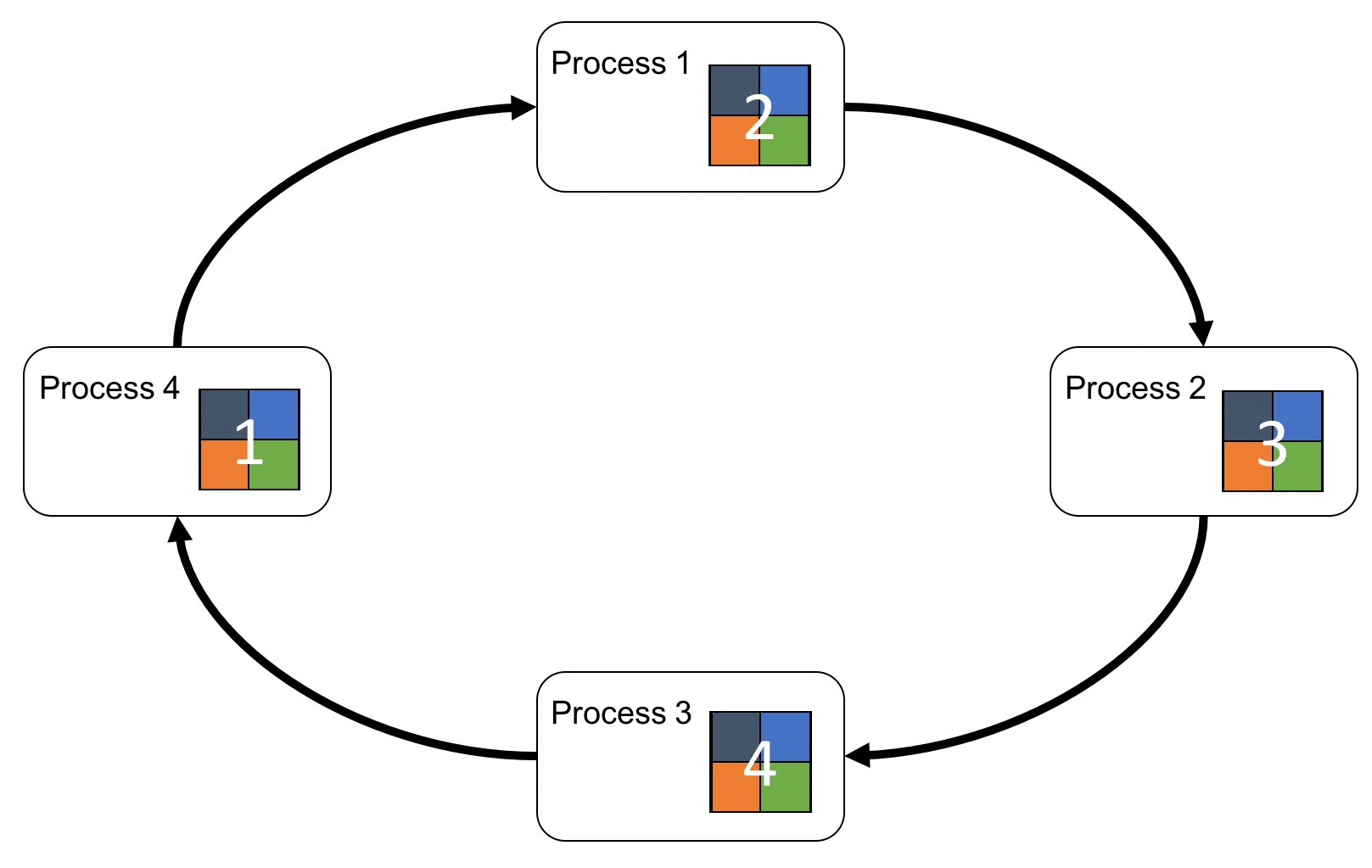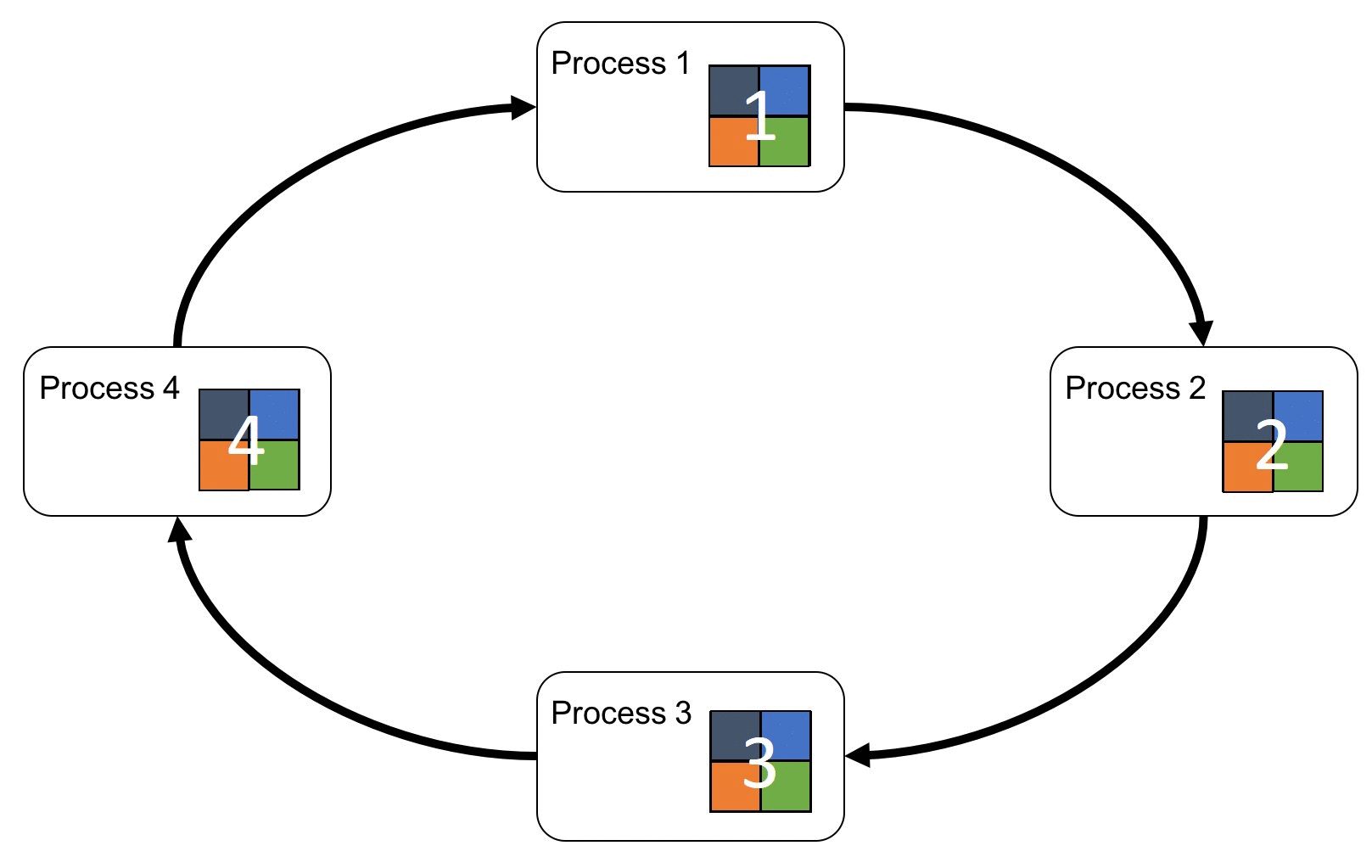
粗糙地说
-
N个GPU
-
第k个GPU将第k份数据传给下一个GPU(一次迭代),收到第k份数据的GPU将自己的第k份数据加入后传送给下一个GPU
-
经过N次迭代后,第k个GPU会收到所有GPU第k份数据的整合,用这份数据更新自身的参数
-
这样的方式,通信开销与GPU的数量无关(每个GPU只与左右两边的GPU通信)
-
每个GPU独立地对其分配到的数据进行前向传播和反向传播,每个GPU得到的梯度相同,每个模型副本在任何时间点都相同
更详细的见
- Bringing HPC Techniques to Deep Learning - Andrew Gibiansky
- Technologies behind Distributed Deep Learning: AllReduce - Preferred Networks Research & Development
模型并行化
当模型太大时,可以对模型进行拆解,进行模型并行化
由于模型层间的依赖性,拆解后无法进行充分的并行计算,训练速度可能受影响
实际运用并不多
DDP 代码实现
Terminology
- group: 进程组,一般(默认)一个组
- backend: 进程通讯后端
- Pytorch 支持mpi, gloo, nccl(Nvidia GPU推荐)
- world_size: 进程组中进程的数量(一个组的话就是全局的进程数)
- 通常一个进程一个GPU(最快,最佳实践)
- 一个进程多张卡,复制模式(类似于DP)
- 一个进程多张卡,并行模式(模型拆解)
torch.distributed.get_world_size()得到进程数
- rank: 当前进程序号,
rank=0表示mastertorch.distributed.get_rank()得到序号
- local_rank: 每台机器上进程的序号,相对机器排序,每台机器都有
0,1,2,3,4,5,6...torch.distributed.local_rank()
一个简单的例子
import os
import torch
import torchvision
import torch.distributed as dist
import torch.utils.data.distributed
from torchvision import transforms
from torch.multiprocessing import Process
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
def main(rank):
dist.init_process_group("gloo", rank=rank, world_size=3)
torch.cuda.set_device(rank)
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST("./", train=True, transform=trans, target_transform=None, download=True)
train_sampler = torch.utils.data.distributed.DistributedSampler(data_set)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=256, sampler=train_sampler)
net = torchvision.models.resnet101(num_classes=10)
# torch 1.8时测试采用torch.nn.Conv1d。 torch 2.0后修改为 torch.nn.Conv2d <2024.7修改>
net.conv1 = torch.nn.Conv2d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.cuda()
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[rank])
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(10):
for i, data in enumerate(data_loader_train):
images, labels = data
images, labels = images.cuda(), labels.cuda()
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if i % 10 == 0:
print("loss: {}".format(loss.item()))
if rank == 0:
torch.save(net, "my_net.pth")
if __name__ == "__main__":
size = 3
processes = []
for rank in range(size):
p = Process(target=main, args=(rank,))
p.start()
processes.append(p)
for p in processes:
p.join()相比于单卡训练有几处变化
- 加了几个环境变量
MASTER_ADDRMASTER_PORT def main(rank)增加了rank作为参数dist.init_process_group("gloo", rank=rank, world_size=3)进程组的初始化torch.cuda.set_device(rank)设置序号train_sampler = torch.utils.data.distributed.DistributedSampler(data_set)加了一个DistributedSampler用于处理数据data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=256, sampler=train_sampler)加入了samplernet = torch.nn.parallel.DistributedDataParallel(net, device_ids=[rank])给模型套一层并行化if rank == 0: torch.save(net, "my_net.pth")如果rank等于0(master device)才保存- 加了一个进程处理
启动
单机多卡
可以通过Process启动,也可以通过torch.multiprocessing.spawn 启动
if __name__ == "__main__":
world_size= 3
processes = []
# 创建进程组
for rank in range(world_size):
p = Process(target=main, args=(rank, world_size))
p.start()
processes.append(p)
for p in processes:
p.join()def main():
world_size= 3
mp.spawn(example,
args=(world_size,), # 注意这里不需要rank参数
nprocs=world_size,
join=True)多进程的程序需要加上if name == "__main__"
多机
每个进程一张卡
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--world_size", type=int)
parser.add_argument("--node_rank", type=int)
parser.add_argument("--master_addr", default="127.0.0.1", type=str)
parser.add_argument("--master_port", default="12355", type=str)
args = parser.parse_args()
def example(local_rank, node_rank, local_size, world_size):
# 初始化
rank = local_rank + node_rank * local_size
torch.cuda.set_device(local_rank)
dist.init_process_group("nccl",
init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=rank,
world_size=world_size)
# 创建模型
model = nn.Linear(10, 10).to(local_rank)
# 放入DDP
ddp_model = DDP(model, device_ids=[local_rank], output_device=local_rank)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# 进行前向后向计算
for i in range(1000):
outputs = ddp_model(torch.randn(20, 10).to(local_rank))
labels = torch.randn(20, 10).to(local_rank)
loss_fn(outputs, labels).backward()
optimizer.step()
def main():
local_size = torch.cuda.device_count()
print("local_size: %s" % local_size)
mp.spawn(example,
args=(args.node_rank, local_size, args.world_size,),
nprocs=local_size,
join=True)
if __name__=="__main__":
main()- node(节点数)指机器数量,rank的计算为
rank = local_rank + node_rank*local_size cuda.device设置为local_rankdist.init_process_group("nccl", init_method="tcp://{}{}".format(args.master_addr, args.master_port), rank=rank, world_size=world_size)增加了init_methodexample的第一个参数是local_rank
master_addr 是节点的IP地址
两个节点的启动方式
python demo.py --world_size=16 --node_rank=0 --master_addr="192.168.0.1" --master_port=22335
python demo.py --world_size=16 --node_rank=0 --master_addr="192.168.0.1" --master_port=22335单个进程多张卡
应该是单机多卡一个进程,允许多个进程一起
import torchvision
from torchvision import transforms
import torch.distributed as dist
import torch.utils.data.distributed
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--rank", default=0, type=int)
parser.add_argument("--world_size", default=1, type=int)
parser.add_argument("--master_addr", default="127.0.0.1", type=str)
parser.add_argument("--master_port", default="12355", type=str)
args = parser.parse_args()
def main(rank, world_size):
# 一个节点就一个rank,节点的数量等于world_size
dist.init_process_group("gloo",
init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
rank=rank,
world_size=world_size)
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST('~/DATA/', train=True,
transform=trans, target_transform=None, download=True)
train_sampler = torch.utils.data.distributed.DistributedSampler(data_set)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set,
batch_size=256,
sampler=train_sampler,
num_workers=16,
pin_memory=True)
net = torchvision.models.resnet101(num_classes=10)
net.conv1 = torch.nn.Conv2d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.cuda()
# net中不需要指定设备!
net = torch.nn.parallel.DistributedDataParallel(net)
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(1):
for i, data in enumerate(data_loader_train):
images, labels = data
images, labels = images.cuda(), labels.cuda()
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if i % 10 == 0:
print("loss: {}".format(loss.item()))
if __name__ == '__main__':
main(args.rank, args.world_size)
rank等于节点编号world_size等于节点数量- DDP不需要指定device
启动
python demo.py --world_size=2 --rank=0 --master_addr="192.168.0.1" --master_port=22335
python demo.py --world_size=2 --rank=1 --master_addr="192.168.0.1" --master_port=22335launch
比较老的方式,将被torchrun取代
import torch
import torchvision
import torch.utils.data.distributed
import argparse
import torch.distributed as dist
from torchvision import transforms
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int) # 增加local_rank
args = parser.parse_args()
torch.cuda.set_device(args.local_rank)
def main():
dist.init_process_group("nccl", init_method='env://') # init_method方式修改
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST('~/DATA/', train=True,
transform=trans, target_transform=None, download=True)
train_sampler = torch.utils.data.distributed.DistributedSampler(data_set)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set,
batch_size=256,
sampler=train_sampler,
num_workers=16,
pin_memory=True)
net = torchvision.models.resnet101(num_classes=10)
net.conv1 = torch.nn.Conv2d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.cuda()
# DDP 输出方式修改:
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[args.local_rank],
output_device=args.local_rank)
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
for epoch in range(1):
for i, data in enumerate(data_loader_train):
images, labels = data
# 要将数据送入指定的对应的gpu中
images.to(args.local_rank, non_blocking=True)
labels.to(args.local_rank, non_blocking=True)
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if i % 10 == 0:
print("loss: {}".format(loss.item()))
if __name__ == "__main__":
main()launch是torch.distributed.launch,主要的作用是参数定义和传递,启动多进程
使用launch的时候应该注意
- 增加一个
local_rank的参数 init_method为env://本地- DDP 都指向
local_rank
启动
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=2 --mode_rank=0 --master_addr="192.168.0.1" --master_port=12355 demo.py
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=2 --mode_rank=1 --master_addr="192.168.0.1" --master_port=12355 demo.py
-m: run library module as a script
设置nnodes的数量为1,就是单机多卡
torchrun
torchrun demo.py也可以和launch一样调用
python -m torch.distributed.run --use-env demo.pyimport torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
class DummyModel(nn.Module):
def __init__(self):
super(DummyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.net2 = nn.Sequential(nn.Linear(10, 10), nn.LayerNorm(10))
self.net3 = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
def forward(self, x):
return self.layer_norm(self.net3(self.net2(self.net1(x))))
def main():
dist.init_process_group("nccl")
rank = dist.get_rank()
if rank == 0:
print(f"local rank: {rank}, world size: {dist.get_world_size()}")
torch.cuda.set_device(rank)
model = DummyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
for i in range(1000):
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
if rank == 0 and i % 100 == 0:
print(f"Iteration: {i/1000 * 100} %")
if rank == 0:
print("Training completed.")
if __name__ == '__main__':
main()启动
多机
torchrun --nproc_per_node 8 --nnodes 2 --node_rank 0 --rdzv_endpoint 10.192.2.1:62111 demo.py 单机
torchrun --nproc_per_node 8 --nnodes 1 --node_rank 0 --master_addr localhost --master_port 61112 ddp_example.py
torchrun --nproc_per_node 8 --nnodes=1 --standalone ddp_example.py功能函数
torch.distributed.is_nccl_available() # 判断nccl是否可用
torch.distributed.is_mpi_available() # 判断mpi是否可用
torch.distributed.is_gloo_available() # 判断gloo是否可用
torch.distributed.get_backend(group=None) # 获取后端,group=None,使用默认的group
torch.distributed.get_rank(group=None) # 获取当前进程rank,group=None,使用默认的group