FROM 【生成式AI時代下的機器學習(2025)】第五講:大型語言模型訓練方法「預訓練–對齊」(Pretrain-Alignment) 的強大與極限 - YouTube
高效的Pretrain?
如何进行有效的pretrain
多样性
有论文 Title Unavailable | Site Unreachable 做过这样的实验
收集N个人的资料,每个人的资料出现一次进行pretrain,然后提取N/2个人的资料制作Alignment的数据,在测试阶段提问未出现的人的信息,发现模型无法正确回答问题
而如果每个人的资料(或者几个人),在预训练阶段通过不同的方式出现了多次,就能够正确地回答问题
这里至少强调了,多样性给模型提供了理解文本的方法,而不会局限于单个样例
Quality
- 文章 textbook is all you need使用GPT生成textbook,发现这样的语料有利于高效训练
- 苹果的文章 Rephrasing the Web 使用一个Rephrase Model来重写网络上的文本,发现这样的文本训练起来比较高效
- 文章RefinedWeb提供了一系列的清洗流程,最终只保留了1/10的数据
- 论文[2305.16264] Scaling Data-Constrained Language Models 论证了有限算力下,最好让模型接触不同的资料(而不是重复相同的token)
- Title Unavailable | Site Unreachable HuggingFaceFW (FineData) Huggingface通过一系列实验论证了数据过滤的最佳实践并给出了相当出色的数据集
Alignment的问题
对齐得到的模型能力是有极限的,究竟什么样的能力能够通过alignment获得? 论文[2405.05904] Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? 进行了分类
以BaseLM的能力作为分类标准
- Highly Known
- Maybe Known
- Weakly Known
- Unkown
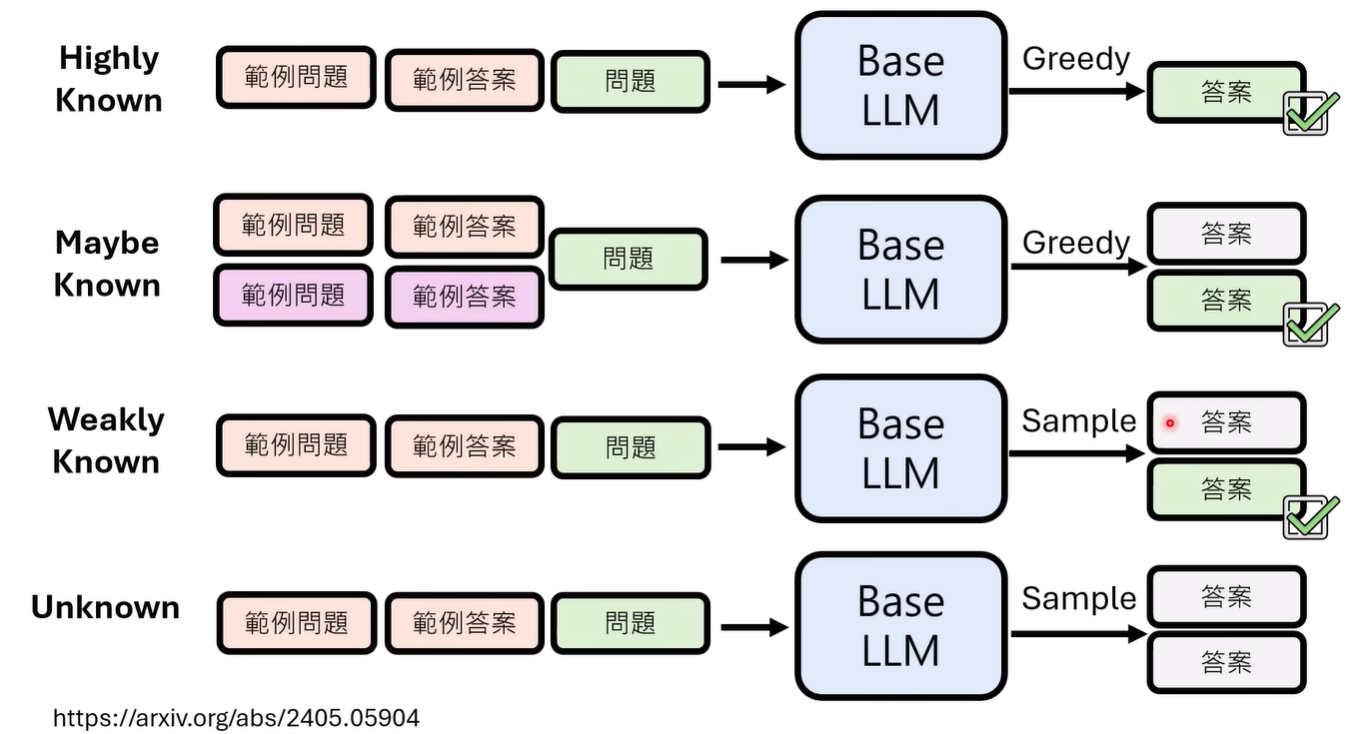
论文将所有类别放一起进行训练,得到如下结果
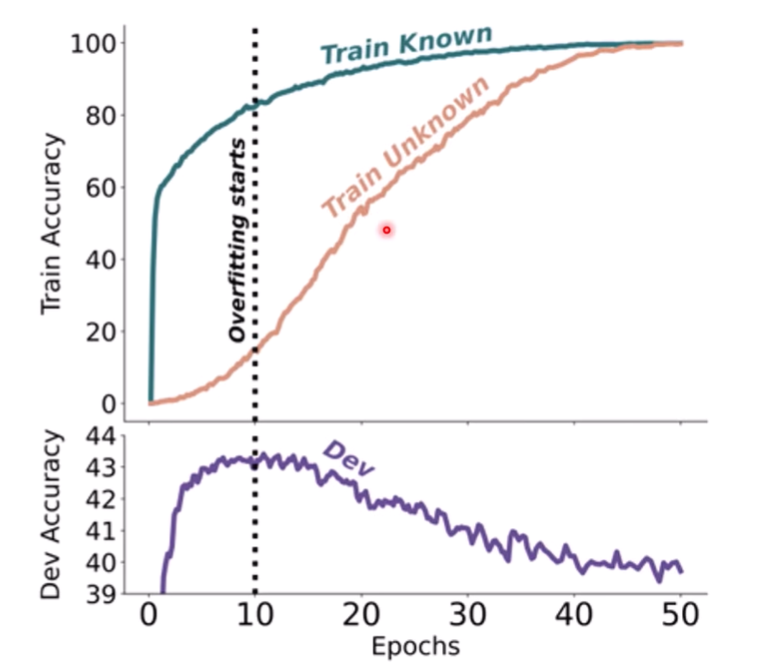
模型在学习未知知识的时候,在测试集上崩坏了
MaybeKnown的训练可能是最高效的
所以可能Alignment没办法学习新知识,当然取决于Alignment的方法
但是RL可能存在争议
Pretrain的问题
pretrain的数据分布会带来影响
- 论文[2309.13638] Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve 列举了一些不一定充分论证的例子
- pretrain中的脏数据知识可能无法被alignment消除(可以通过第一讲的logit lens看到)
- alignment改变了激活它们的概率
