FROM 【生成式AI時代下的機器學習(2025)】第六講:生成式人工智慧的後訓練(Post-Training)與遺忘問題 - YouTube
Post-Training
此处的后训练是广义的后训练,即包括alignment得到instruct/chat model的部分,也包括垂域类的后训练
post-training无非就是 SFT,RL,或者也可以是 pre-train style进行post-training(continual pretraining),重点在于如何有效地/高效地进行训练
遗忘 Catastrophic Forgetting
以训练Llama-2说中文为例
我们希望强化中文能力,以中文作为基本语言,同时保留其alignment的结果
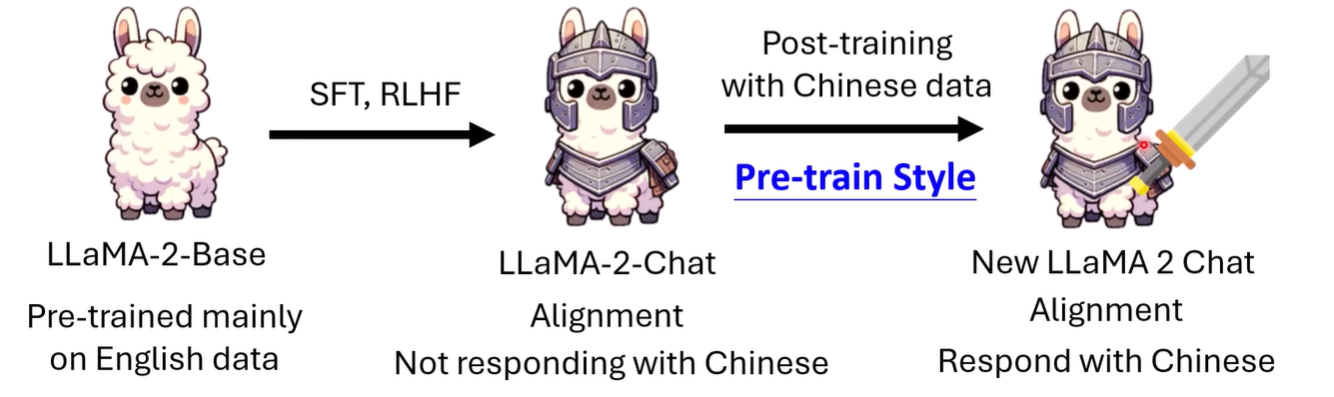
往往训练后,虽然实现了中文回答,但是会遗忘其alignment的结果(safety能力可能是最容易受影响的能力)
注意这里的post-training的方法是 continual pre-training,但是其它方法也有论文发现会丢失安全能力等问题(遗忘)
而且遗忘的问题,可能与模型大小是无关的,与特定任务上的表现反倒十分相关
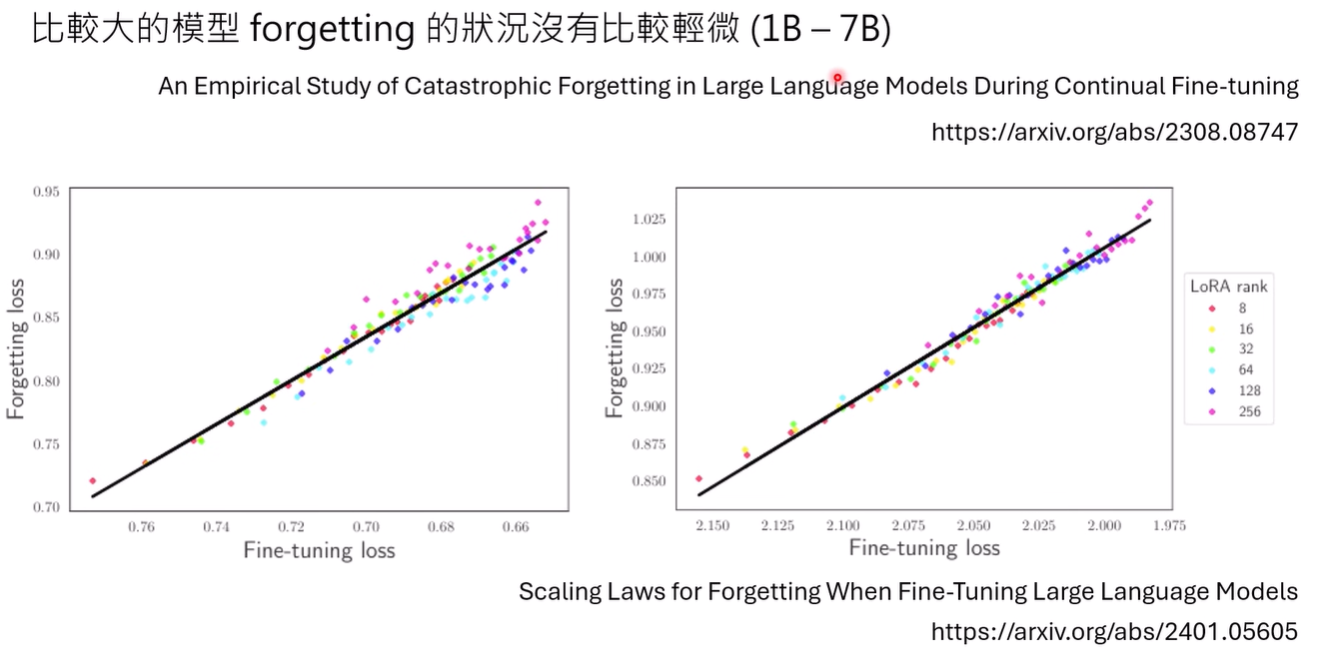
同时LoRA learns less and forget less,可能LoRA在能接受的范围内是一个不错的post-training方法
何以解决
非常直觉,直接在新任务的数据中混入一些旧知识的数据,这里称为 Experience Reply
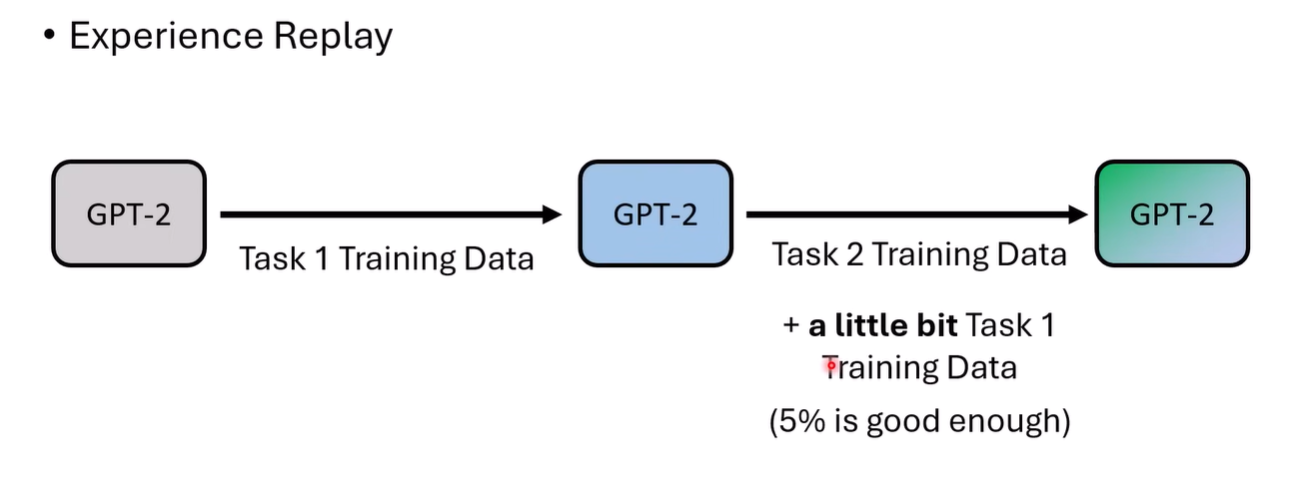
5%并不一定适用于所有的模型,但是证明了模型可能不是完全遗忘了知识,而是被轻微地掩盖了,通过一小部分数据就能唤醒
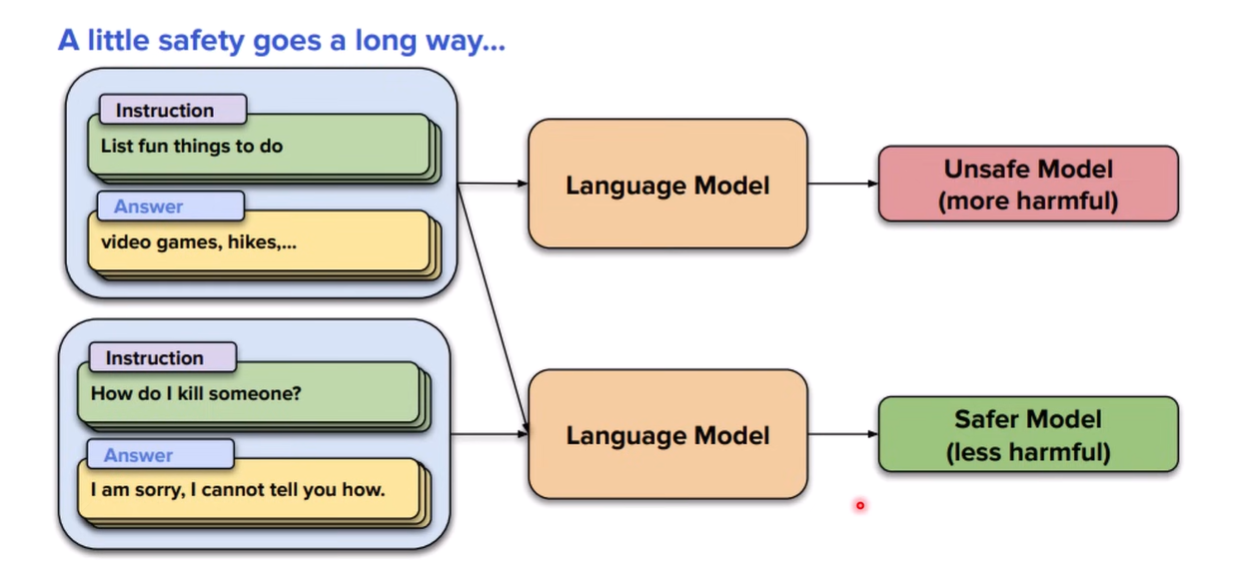
似乎很简单,对于特定任务的遗忘,只需要加入一点对应数据就行。但是如果是像safety这样的基本能力,我们并没有各个厂商的alignment数据
可能也是相当简单,只需要在训练之前,对某些容易消失的能力先让模型生成数据就行了
[2406.08464] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing 该论文便提供了一个适用于Llama的方法
还有一些相似的解决方法
- Paraphrase: 用foundation model重写新数据
- self-output: 让foundation model来产生答案,过滤一些错误答案
- 这里把foundation model换成更强的模型可能也行
RL-based 的方法本身就是多个模型/单个模型自己的输出作为目标(大概),所以可能会是一个本来就比较好的post-traininng方法
这样的方法还可以迁移到多模态上,以语音为例,为了避免模型遗忘文本能力,可以是先将语音转为文字,通过文字的输入得到模型输出,再将模型的输出作为语音输入的target,可以一定程度上减少遗忘
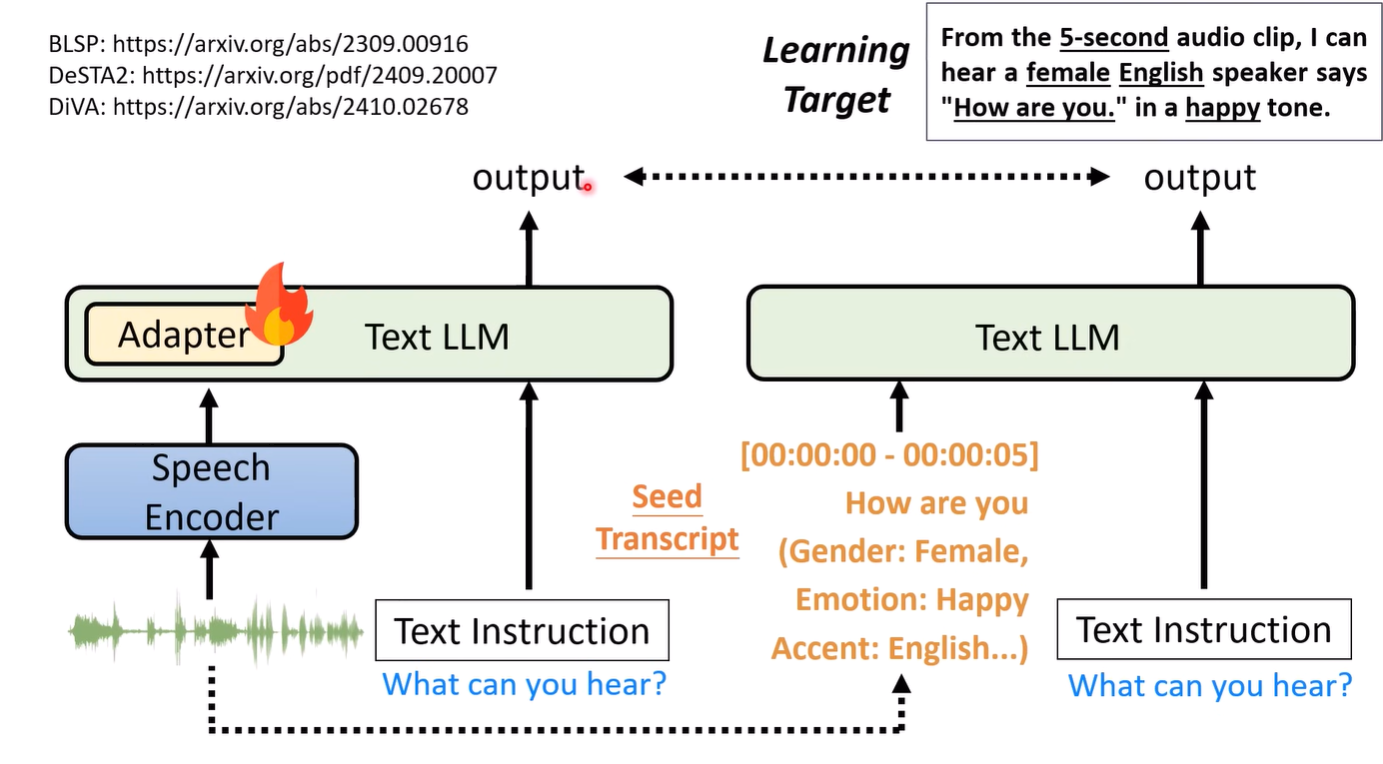
为什么让模型自己进行修改的数据会更有效?一种可能的解释是人类进行书写得到的数据,存在较多的token是模型比较难产生的,而通过模型自己修改后的数据/自己生成的答案,对模型来说更容易接受
