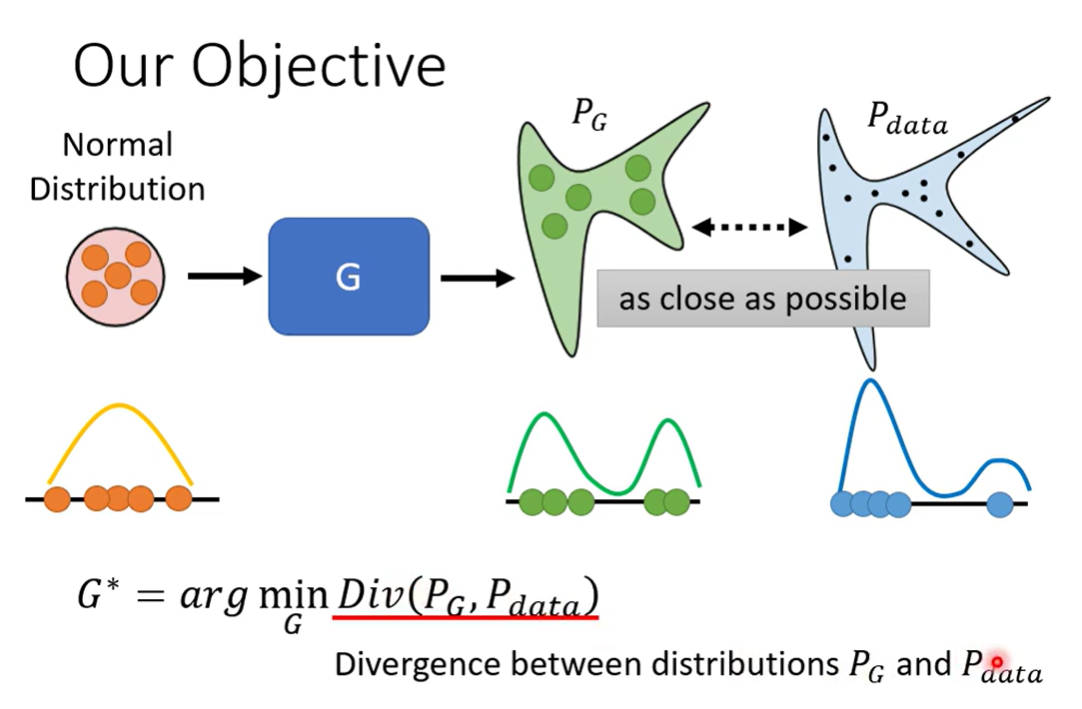
Overview
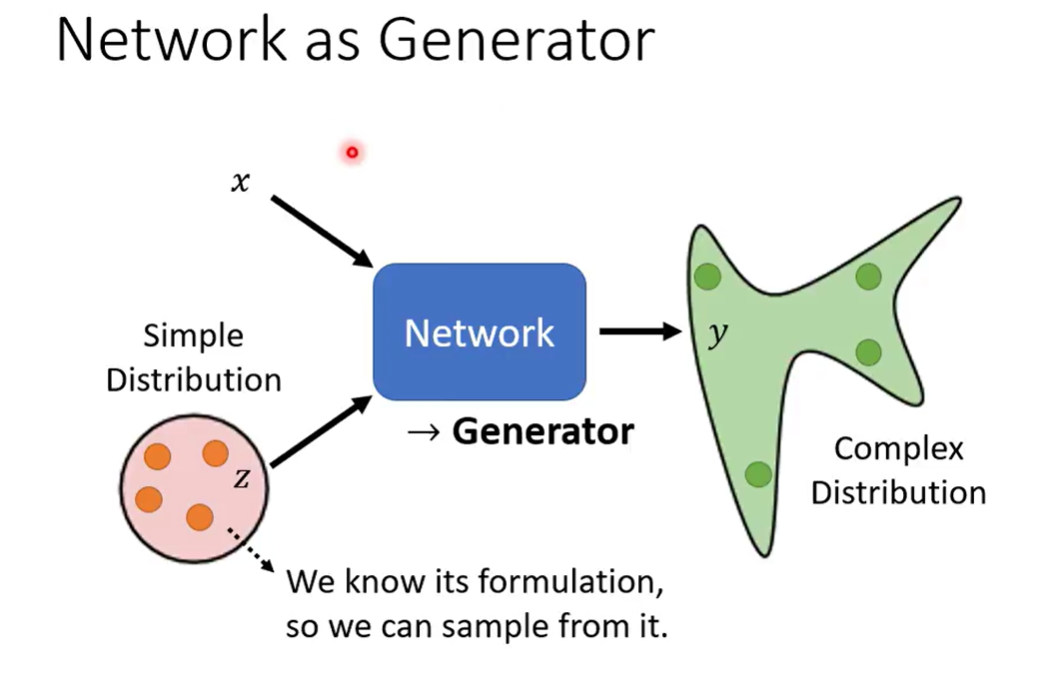
Network as Generator
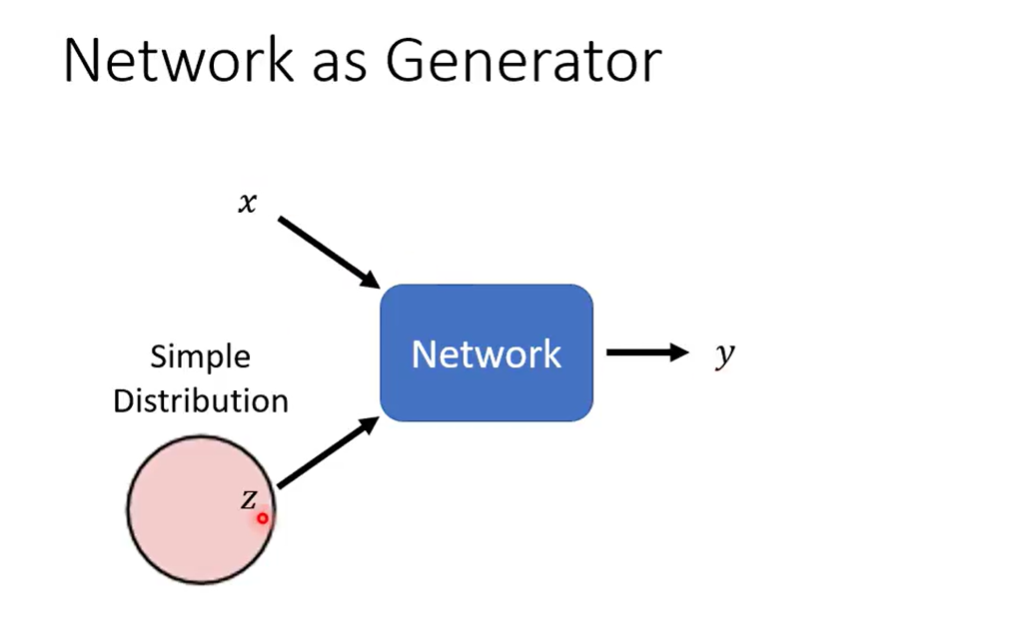
Simple enough(we know its formulation) sothat we can sample from it
模型得到两种输入,而从simple distribution得到的输入每次都不同,得到的输出也是一个distribution
这样的网络称为 Generator
Why distribution
如果只是surpervised learning(传统的) train下去的话,固定的输入只能得到固定的输出,输出是固定的,为了得到两种数据集中可能性相同的结果,模型可能两种同时输出
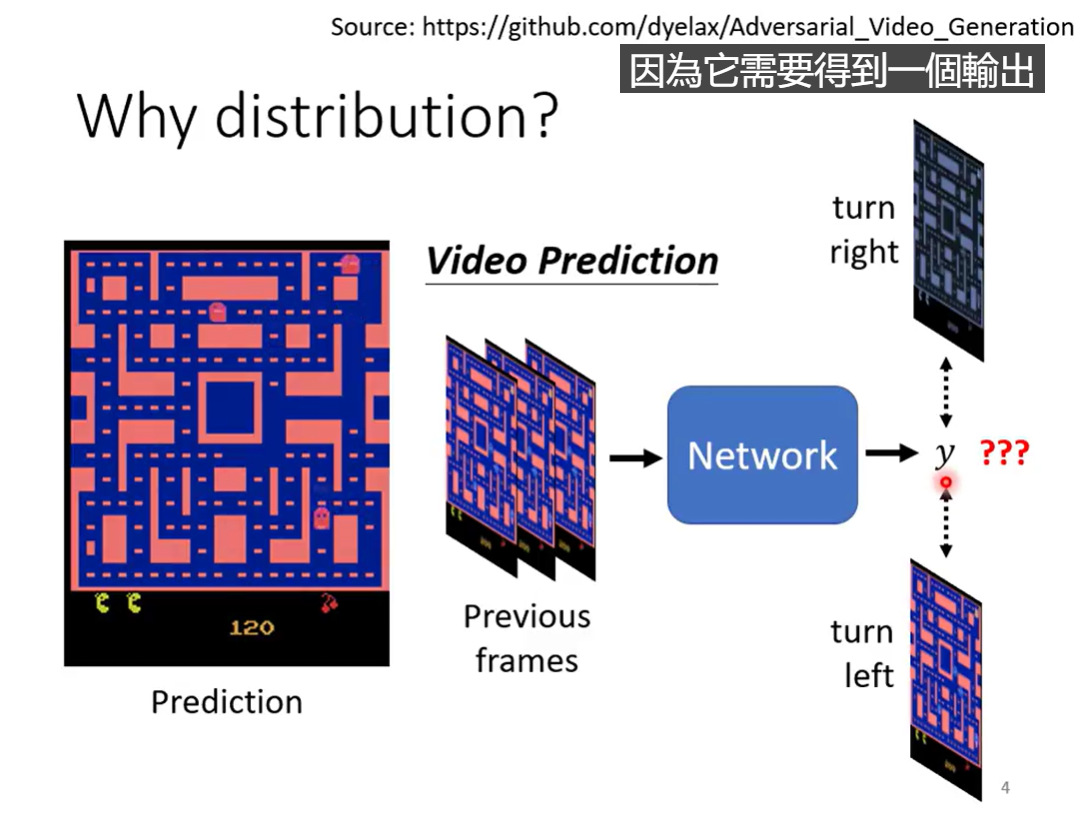
实际上就是,我们需要保留多种输出的可能性,并最终选择一种(需要一个分布)
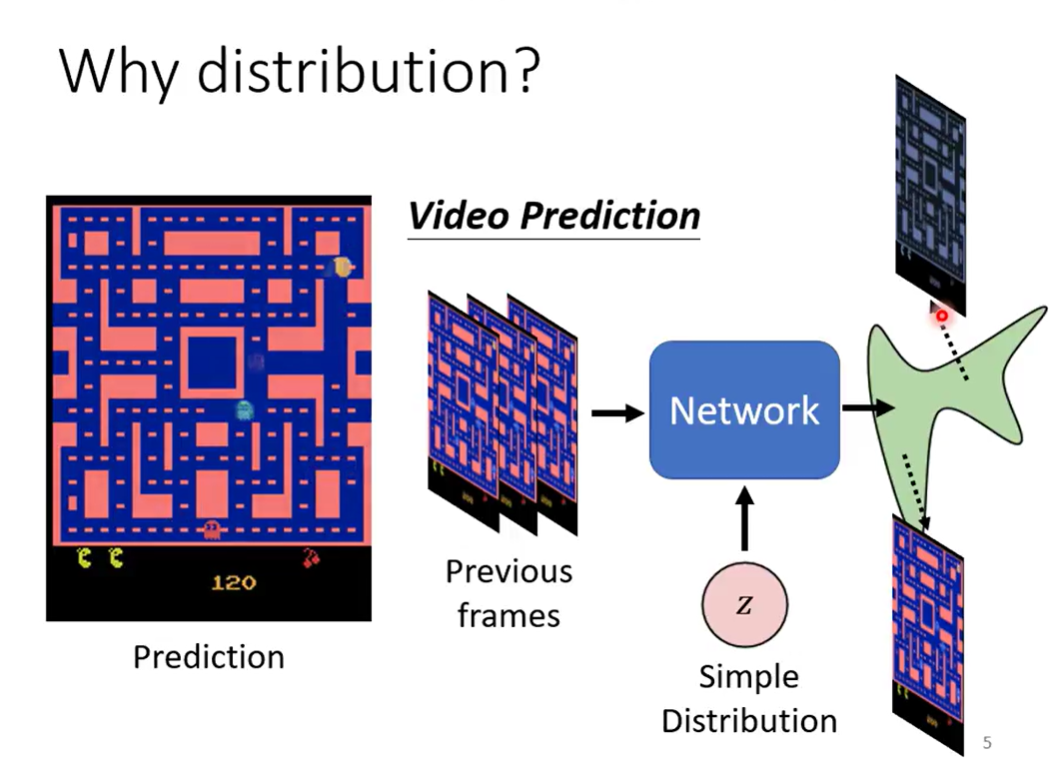
model needs creativity
Generative adversarial model(GAN)
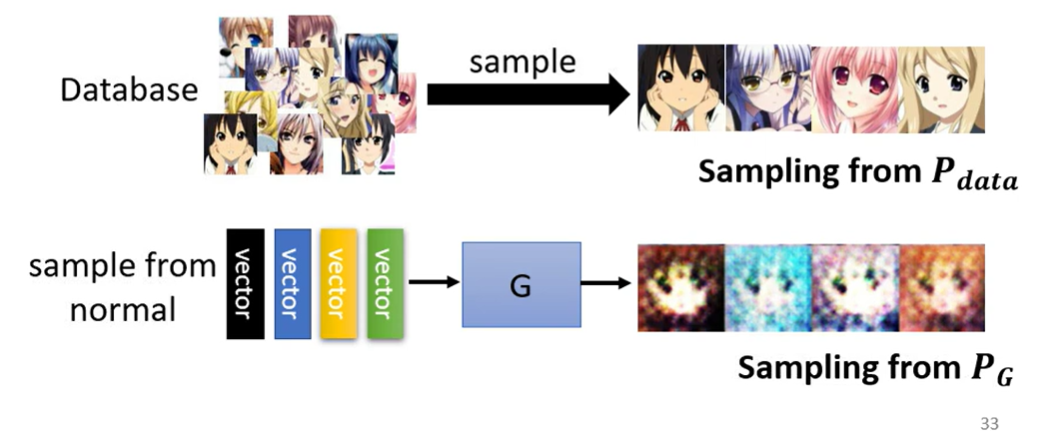
Anime Face Genertaion
unconditionla generation
先把 x 拿掉,直接用sample得到的向量进行生成
sample的分布用正态分布,sample得到的向量用低维向量表示,得到图片(高维向量)
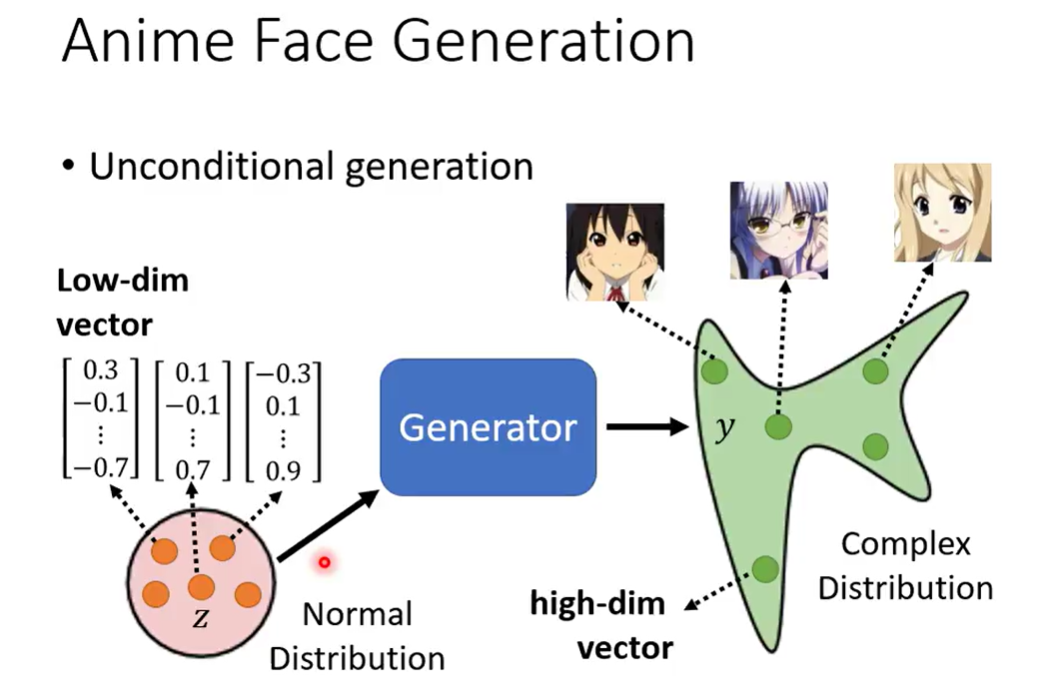
分布的影响可能不大,模型学到信息就行
如何得到损失 --- 训练一个discriminator,用于判定输出的图片是否符合要求(输出一个标量,表示符合要求的程度,符合要求得分高,不符得分低)
discriminator的架构没有限制
相比于supervised learning,supervised learning 相同的标签实际上对应多个解,模型无法学会应该输出什么,表现在图像上会是模糊的图片
Discriminator进行分类,指明了学习的方向
Basic Idea of GAN
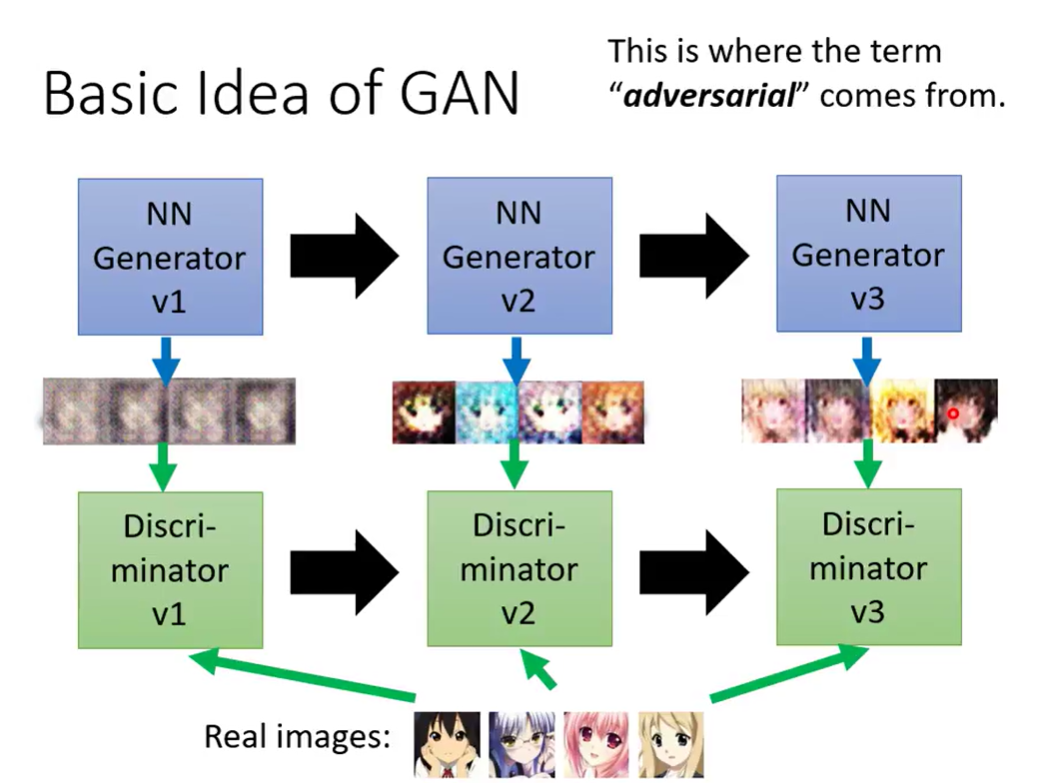
对抗
Algorithm
Training iteration
- Fix generator G, update discriminator D
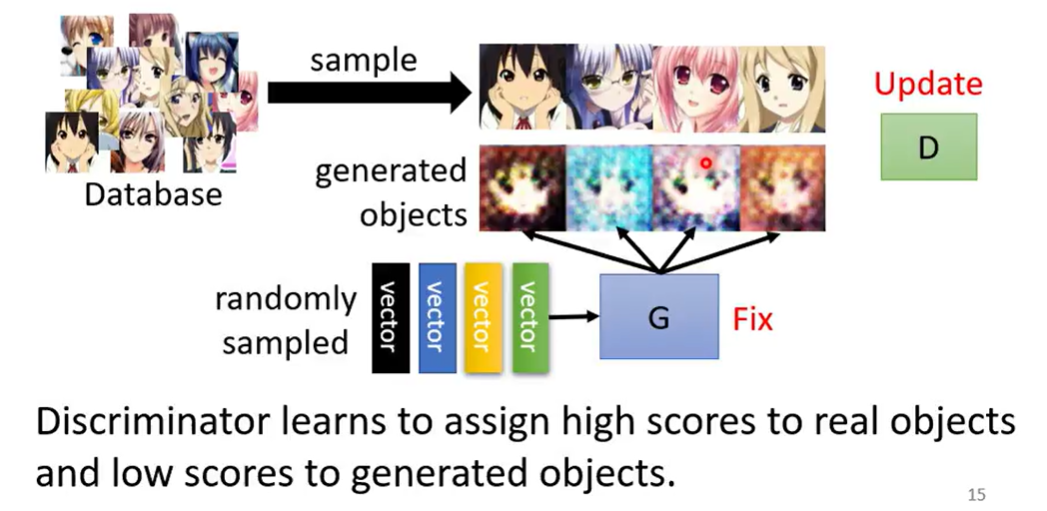
- 固定G下,随机sample得到vecotr,生成图片,再从database中sample出目标图片,训练D
- Fix discriminator D, update generator G
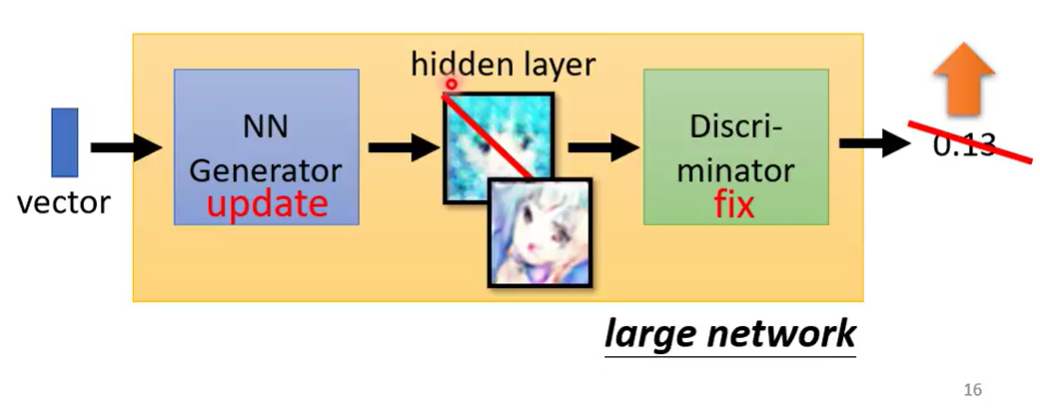
- G生成图片,交给D评分,目标是使分数变高
- 将G和D接起来,输入一个vector,(中间某一层得到了图片),然后评分,调整G的参数
- Iteration
Theory behind GAN
Objective
最小化生成的分布与目标分布之间的散度
但是在数学上,计算divergence很困难(积不出来)
GAN 通过sample 计算 Divergence
Discriminator

与 binary cross entropy是一致的
也就是实际上是当成一个classifier进行训练
经过推导后发现,的最大值 与 JS divergence 相关
直观上看
- 如果两个分布相差很大,Discriminator能够很容易区分开两个类别,从目标函数的角度来看,能够变得很大
- 如果两个分布相差很小,Discriminator很难分开,没办法变得很大
回到原来的目标,最小化两个分布的散度,而这个散度与的最大值相关,则原来的目标可以写成
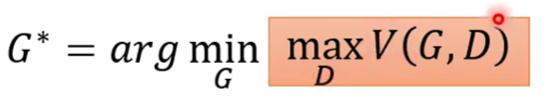
目标函数分为两层,一层优化Discriminator,另一层优化Gnerator,所以训练过程会像上述一样分开固定,进行迭代
通过改变divergence(目标函数),GAN就有不同的训练方法

Tips on GAN
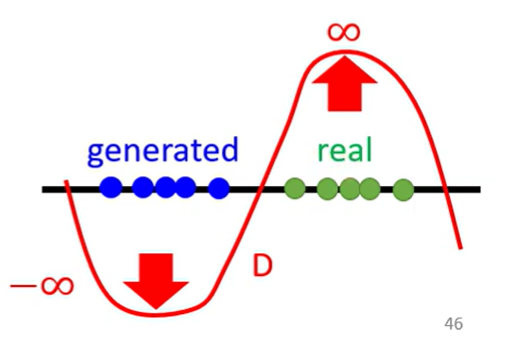
JS divergence is not suitable, for 2 reasons
- and 都是高维空间中的一小部分(manifold of high dimension 存在高维空间中但是只有低维的表现,三维中的球面,平面中的线),以这个角度来看,他们是难以重叠的(相近)
- 也可能实际上不是manifold,但是因为sample得不够,也可能不会有数据 ,导致同样得到同样的结论)
- JS divergence对不重叠的两个分布会一直得出
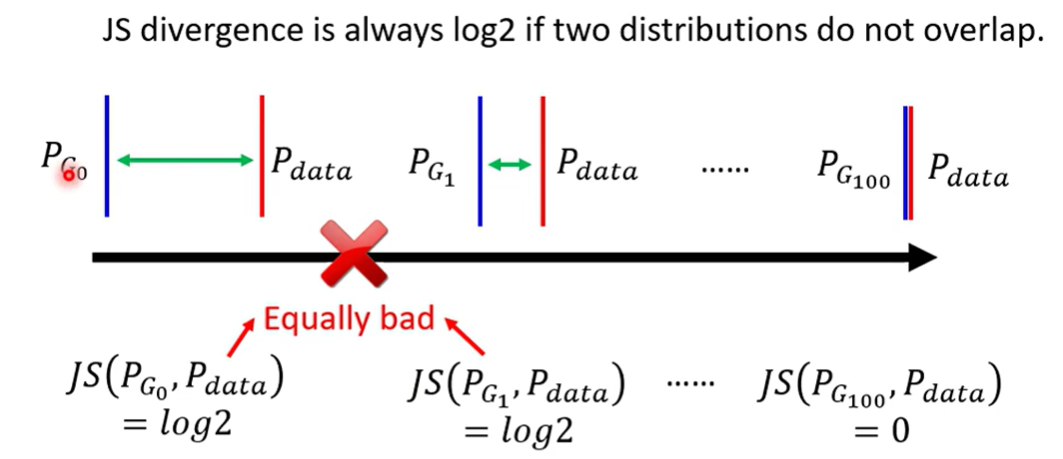
实操的时候,模型的正确率总是可以达到100%(可能是模型记住了sample出的样本),这样没有信息能够优化模型
Wasserstein distance
W 发 /v/
Earth mover distance 将两个分布的点推到一起需要的平均距离
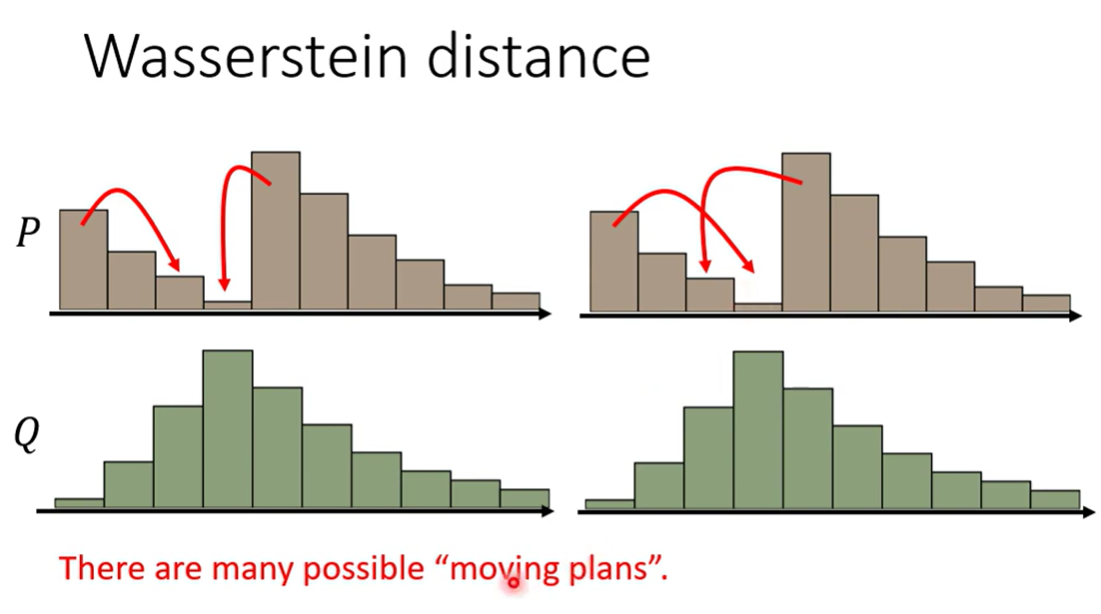
在移动的时候,有不同的moving plan
所以需要枚举所有方法,找到最短的平均距离
如果使用 Wasserstein distance
这样上述JS无法适用的情况能够得到解决

Wasserstein distance能够在中间过程产生优化信息,使得优化discriminator的过程能够实现
怎么计算Wasserstein distance

x指的是图片
从真实数据中得到的x,discriminator应该越大越好,从Generator得到的数据应该越小越好(使得值最大)
另外,D必须是 function,理解为足够的平滑
是一个限制,如果没有限制的话
直观上理解,足够平滑的话相近的点值差异不会太大,训练后两个分布会是接近的,同时要求不同分布值越大或越小越好,所以加上限制后,两个分布没有办法各自趋近于两个无限
但是怎么加上这个限制
- 原始论文,不知道怎么加,所以直接限制
- Improved WGAN
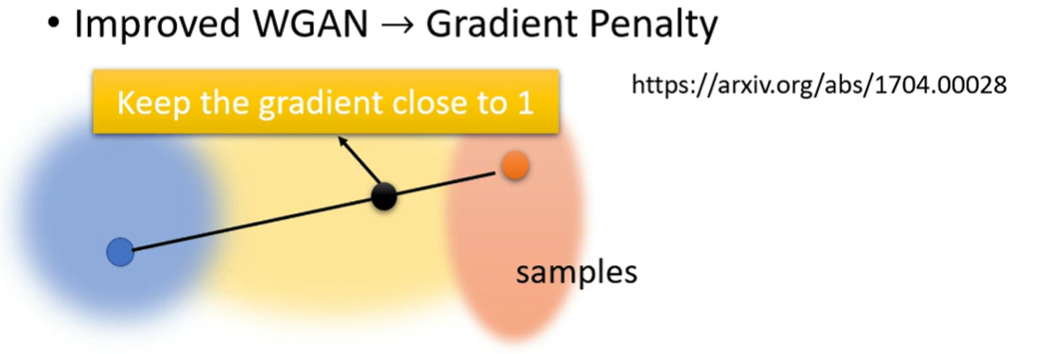
- 两个分布的sample,两点连线再取一个sample,要求gradient 接近1
- Spectral Normalization


理论上Discriminator每一次都是从头train到收敛,但是实际上这样train不动,所以实操上应该Discriminator的参数不会重新初始化
Training GAN
train GAN is still challenging
如果两个部分有一个停止进步,两边都可能train不动
GAN for Sequence Generation
拿GAN生成文字是较为困难的
- Generator 生成文字
- Discriminator 分辨是否符合目标(例如人类文字和不是人类文字)
Generator的输出结果是离散的token,当Generator的分布发生微小变化,可能生成的token是不变的,Discriminator输出的分数是不变的,那就没办法基于梯度下降优化
如果没办法使用梯度下降,那就试一下RL吧
但是RL也很难train
所以很难
Evaluate the quality of image
如何自动地评估Generator?
- 影像辨识系统,如果得到的分类结果和生成图片一致的话,可能就是比较好的
- 但是也会有Mode collapse的情况(局限在分布的某一个点中)

- 可能这个点能够骗过Discriminator
- 也可能有mode dropping
- 覆盖了一部分的分布,但是缺失了另一大部分

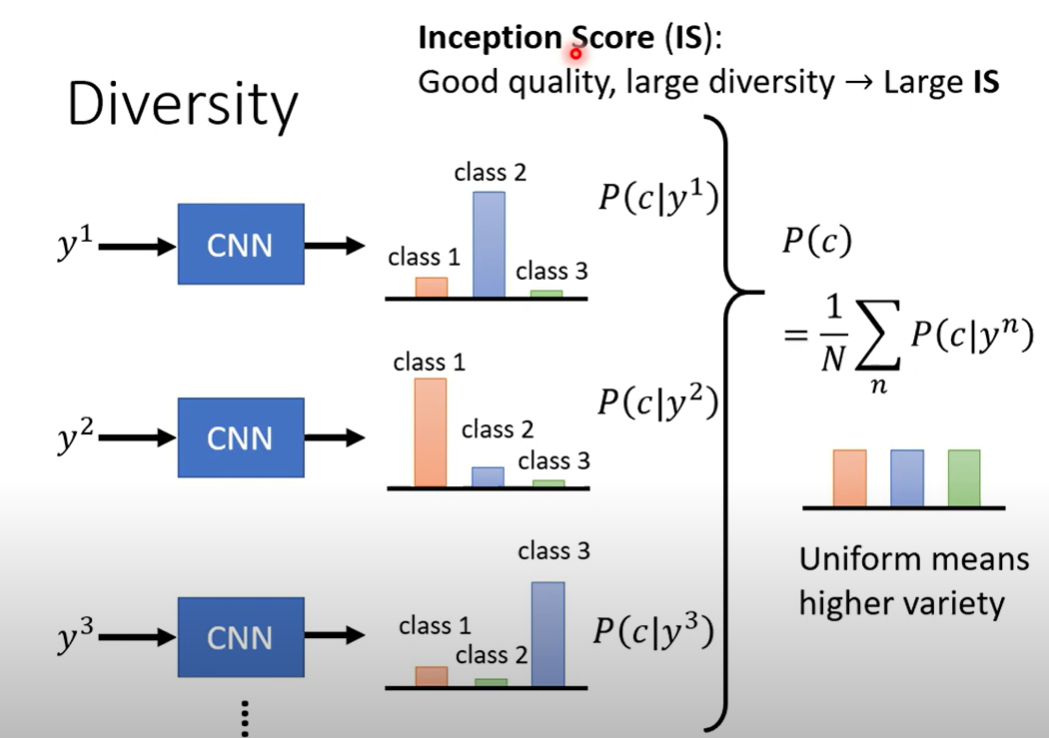
如何评估Diversity
-
train一堆classifier,负责不同类别
-
得到多个类别分类结果的概率,加和平均
-
如果每个类别都差不多均匀的话,认为模型足够diversity
-
-
Inception Score IS
-
并不一定适用,可能任务是无法被inception分类的
-
FID
- 不是拿类别而是使用logit(hidden state)
- 假设两个分布(GAN的输出和真实分布)都是 Gaussian distribution(很强的假设,毁有问题)
- 计算 Fréchet distance
- 越小越好
Memory GAN?
生成的图像与原始数据高度相似

Conditional Generator
加入文字(condition)
Text-to-image
通过文字和sample生成图片
此时的训练数据需要是 label 的
上述的训练方法无法考虑条件
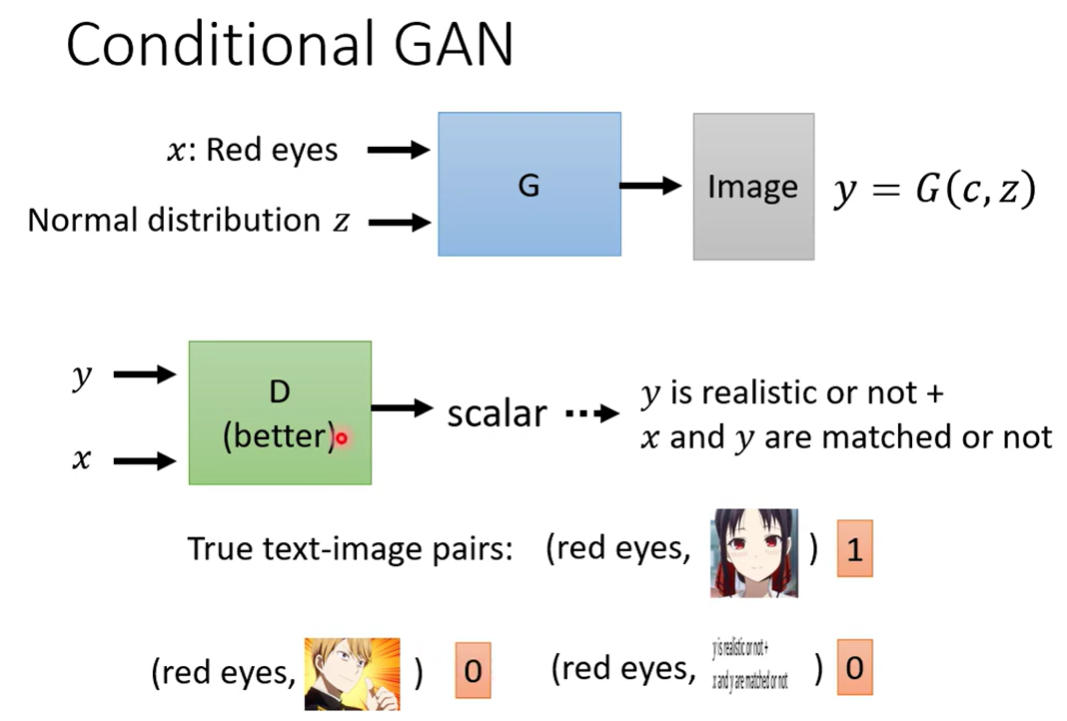
条件必须也作为输入,Discriminator需要通过 paired data进行训练
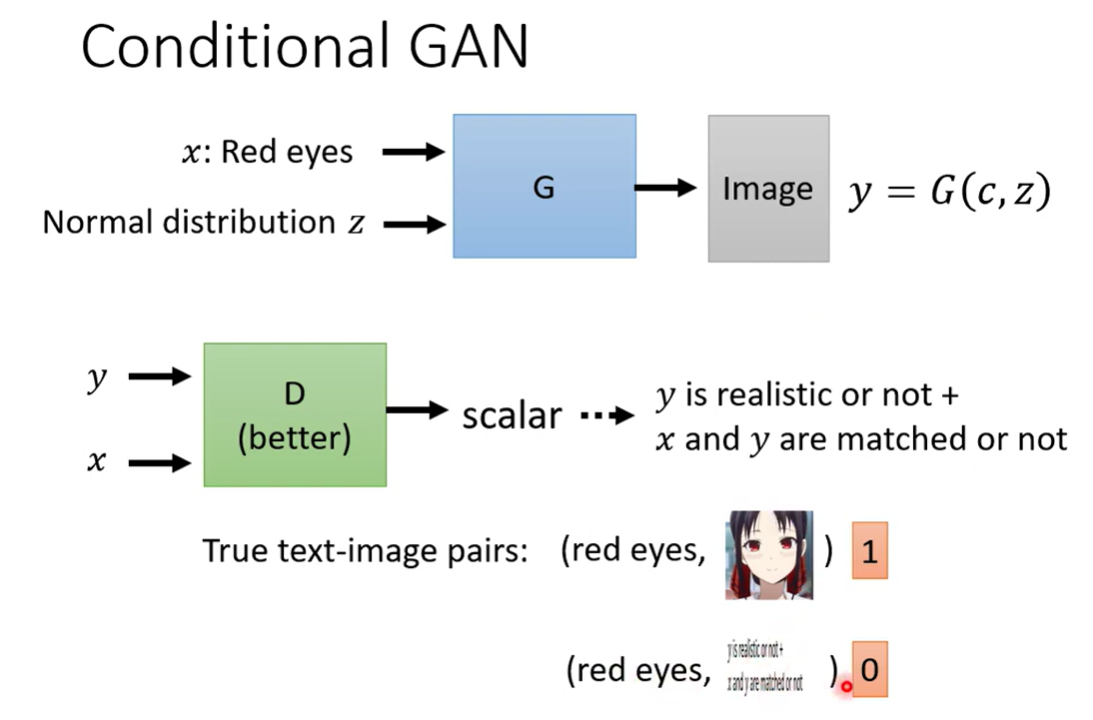
只是 低质图片作为反例不足以作为反例
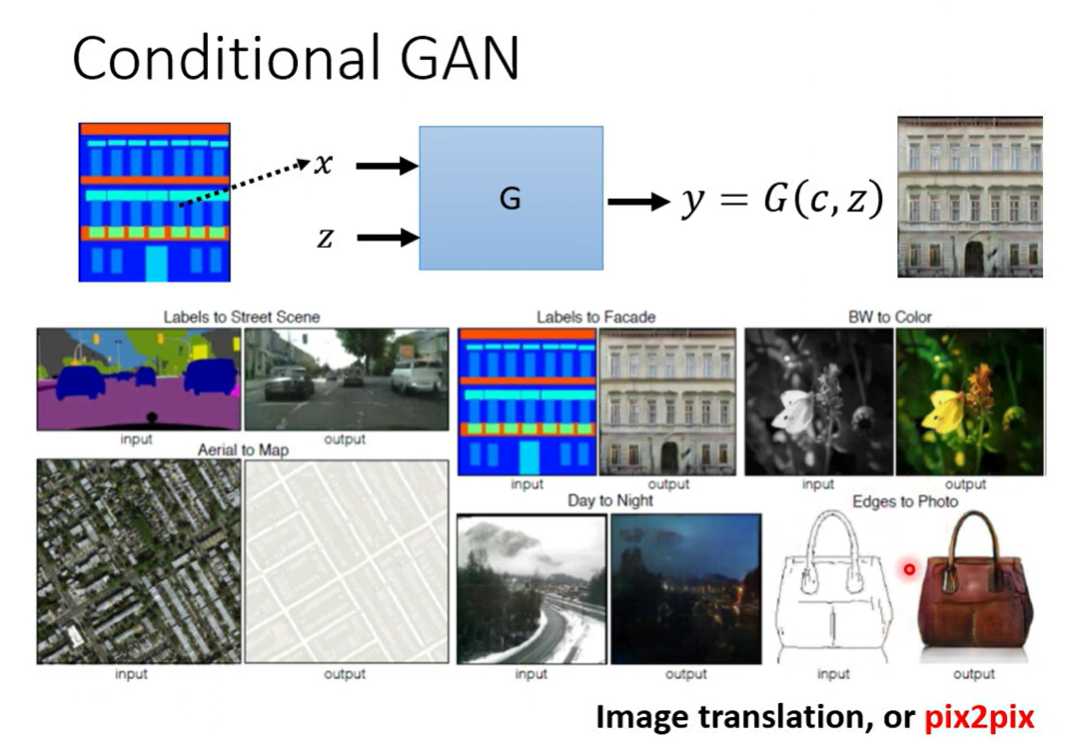
Condition也可以是图片(image translation pix2pix)
GAN for unsupervised learning
完全没有标签的任务
- Image style transfer
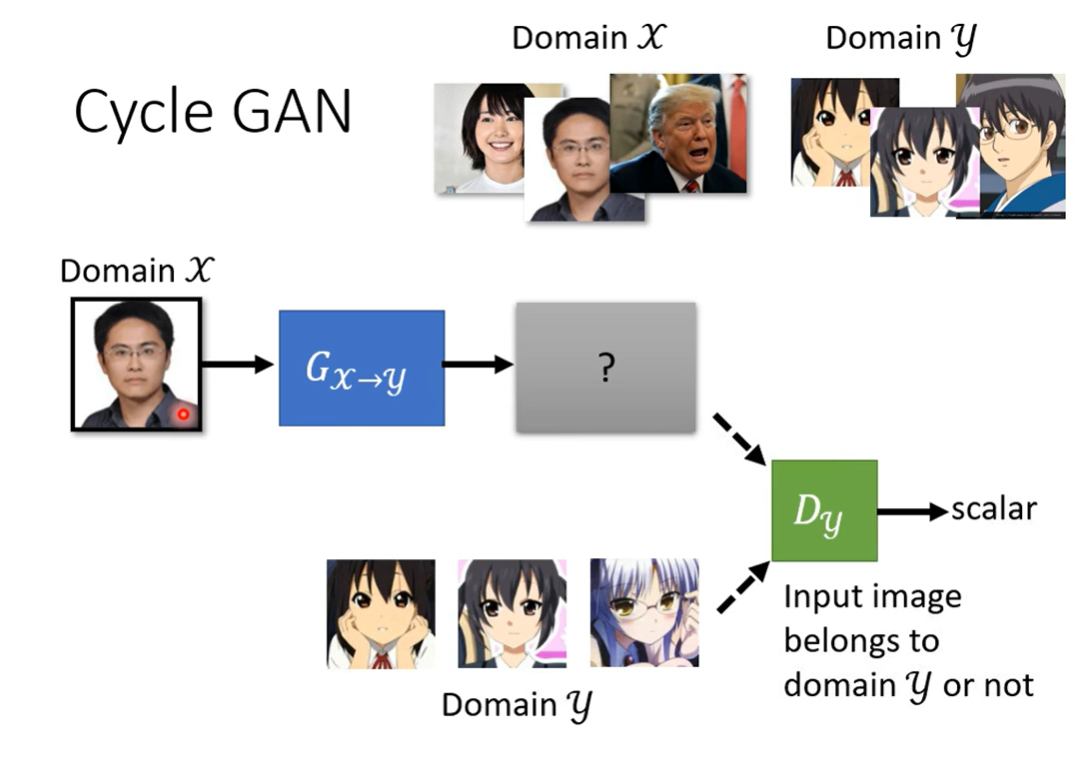
完全使用GAN的训练方法,选取一张图片(从X分布中抽样),进入Generator,然后使用Y分布中的图片和Generator生成的图片训练Discriminator,迭代train就结束了。
但是这样虽然X分布和Y分布形成了映射,没有约束保证输出与输入有关(只要把输入当成噪声就可以了)
如何加入约束呢
Cycle GAN
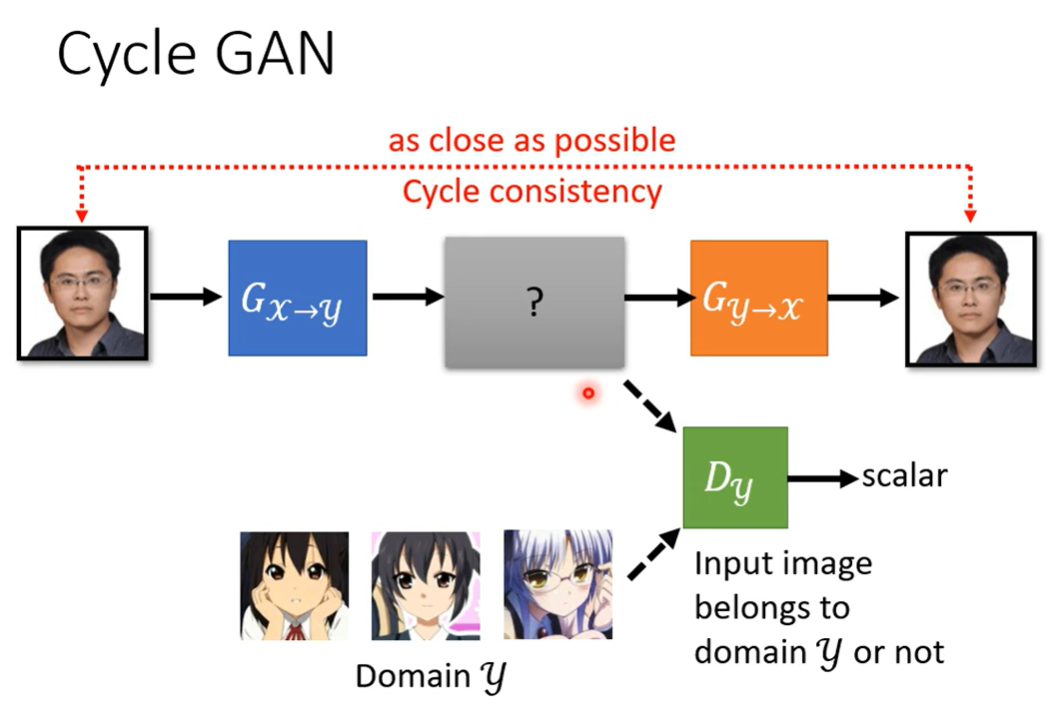
两个GAN,一个映射到Y,一个恢复原图,使得模型能够学到与原图相关的信息
但是这样也没能保证学会的信息是否合理,只要能转换就行了。
实操上问题不大。
训练的同时可以训练一个Y转到X的模型
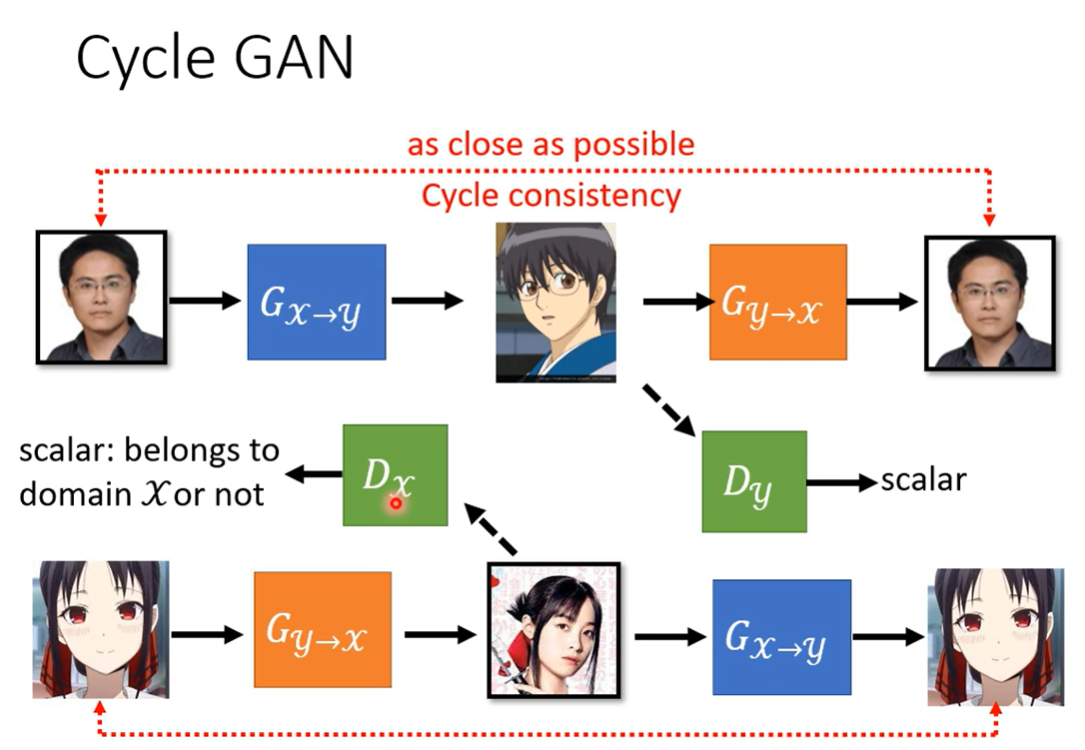
合起来是Cycle GAN
这样的任务能够用于文本生成
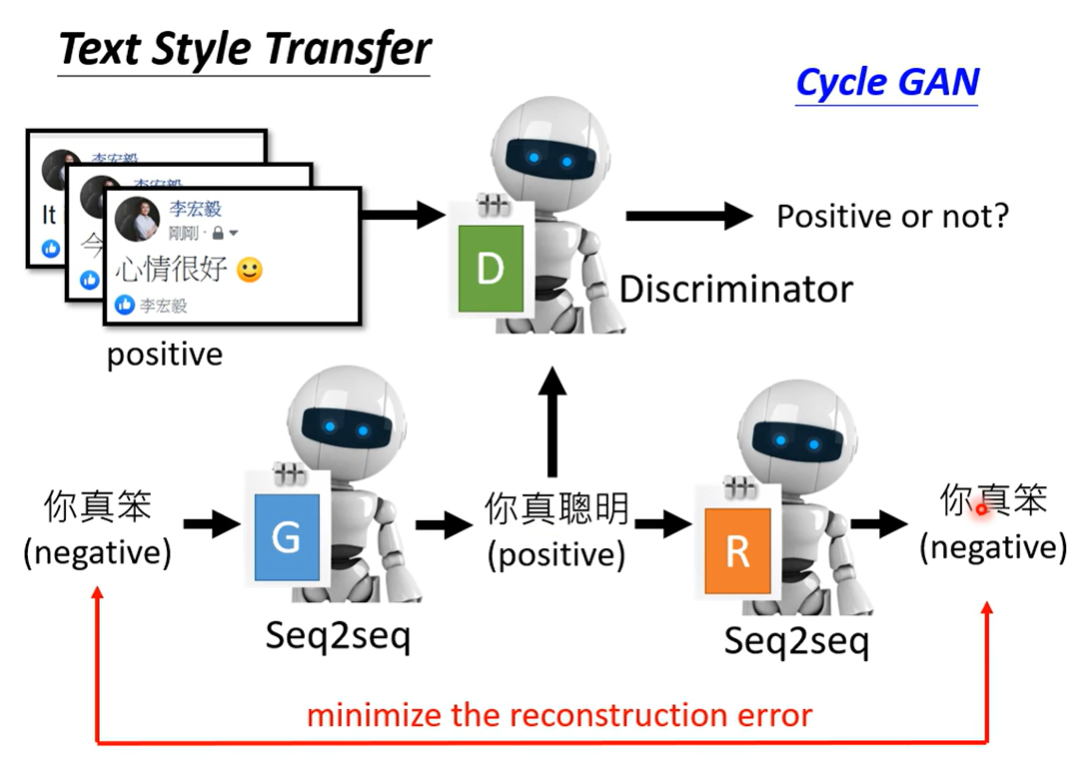
文字给Discriminator会有问题,所以得用RL硬做
- 无监督的长文章摘要
- 无监督的翻译
- 无监督的SASR 声音和GAN