Convolution

translation equivariance: Features of images don’t depend on their location in the image
关于图像尺寸:有的时候可以使用aspect ratio bucketing,即根据不同长宽比来划分图像到不同的桶中,同一个桶的图像resize或pad到相同尺寸,来避免过度transform导致的失真
对于ViT/Unet等架构来说,输入尺寸可以不唯一,所以在扩散模型/transformer-based的模型中这样的处理比较常见
注意:Convolution layers 是线性的,我们通常需要在网络中增加非线性的部分,可能是activation function,也可能是如 max pooling 的非线性计算
Normalization
Key idea: learn parameters that let us scale / shift the input data
目的是改变输入数据的分布,做法是通过学习的参数和归一化
LayerNorm

计算这个batch的statistic,通过学习到的系数进行调整
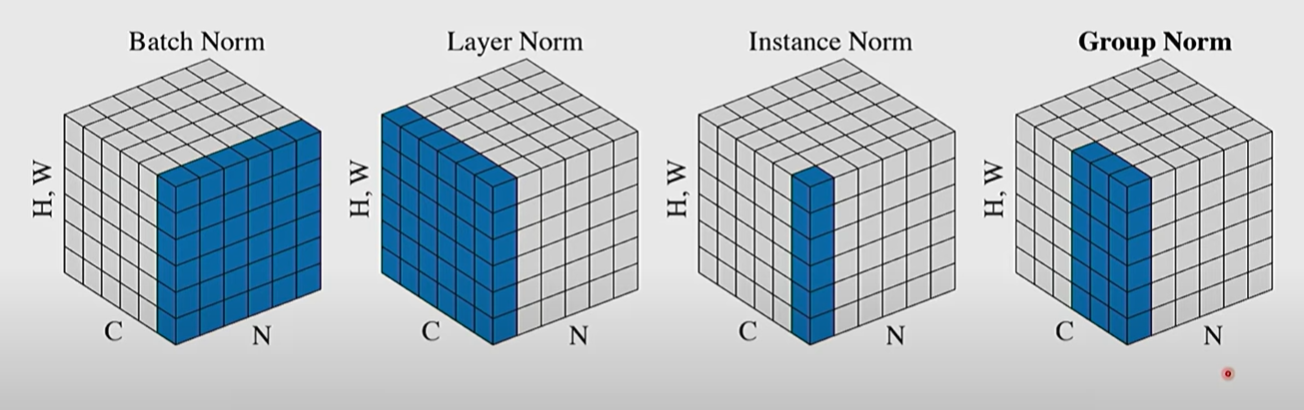
- Batch Norm是对batch进行归一化,即同一channel的不同sample进行归一化,得到
- Layer Norm是对layer进行归一化,即同一sample的不同channel进行归一化,得到
- Instance Norm是对sample的一个channel本身进行归一化
- Group Norm 就如图所示
Dropout
在forward的时候,随机将激活值设为0
在test time会取消,但是由于test time没有dropout,你的输入的magnitude会远大于原本,所以最好使用dropout的probability对之后的输入进行scale

Activation function
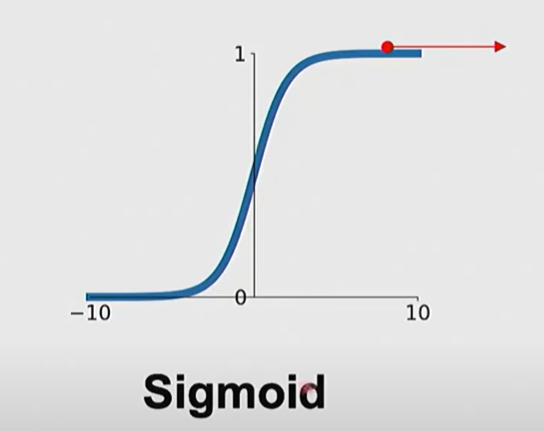
- sigmoid
- 在极小和极大时梯度过小,累乘后得到极端小的梯度
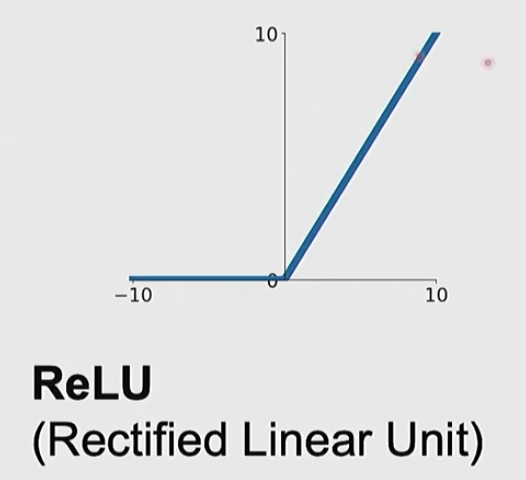
- ReLU
- 正值always 1,负值梯度为0
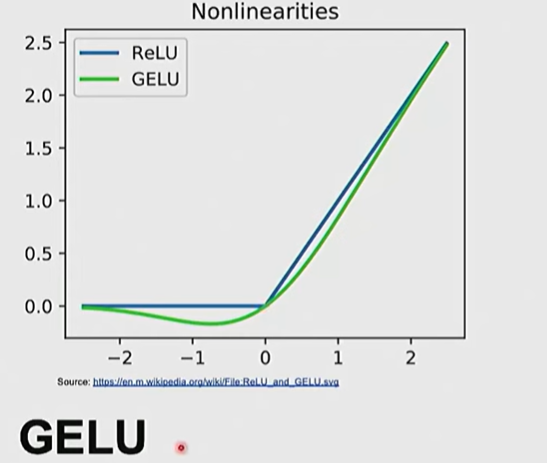
- GeLU
- 更缓和的ReLU,但更大的计算量
CNN
为什么选择 的卷积核,不是很能解释,不过 , stride为1的卷积核每一层会扩大感受野两个像素,三个的卷积核相当于一个 的卷积核,但是参数量更少,三层的non-linear activation function也能带来更多的非线性表达能力
卷积核的参数是 kernel_size x kernel_size x channel x kernel_num
下一层尺寸的统一计算式是 (size - kernel_size)/stride + 1
ResNet

直接scale up,更深的模型的表现,在训练集和测试集上都不如浅的模型
但是理论上来说,深的模型表达能力要超过浅的模型
为了让模型更容易至少学会像浅的模型一样的能力,我们可以简化训练目标
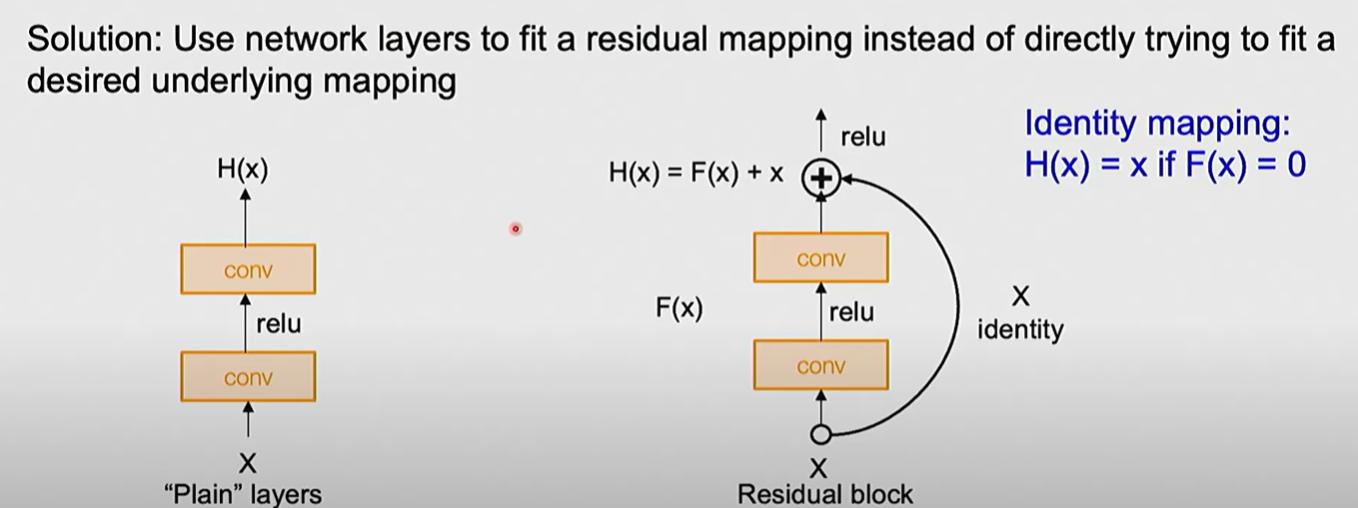
由于residual connection,模型只需要将参数设为0就能得到至少与浅模型一样的表现(identity function)
residual connection要求经过convolution之后尺寸不变,通常是,padding为1,stride为1的卷积核
Weight Initialization
如果初始化的时候weight过小,数值会逐渐小时,如果过大,数值会逐渐膨胀
kaiming initialization使用

在ReLU下,这样的初始化能保证每层的数值(mean and std)相对一致
Data
Data Preprocessing
归一化,pre-compute mean和std,然后归一化
为了简化可以假装符合imagenet的mean和std(一般是使用imagenet子集之类的)
Data augmentation
a kind of regularization
- Flips(horizontal, vertical(may not make sense))
- resize / cropping
- ResNet是随机选择长宽范围中的一个数L,然后resize data,让短边为L,随机采样 patch
test time augmentation
- color jitter
- contrast & brightness
- set random image regions to zero
- dropout
- cutout/random crop

一般是进行增强之后,肉眼观察是否仍在分布内。认为肉眼能分辨的,机器才能分辨
Transfer Learning
一个训练好的CNN,在高层的feature会很好地提取了特征,经过最终的linear layer得到分类结果。(与Module 1中的linear classifier相似,我们最后实际上是得到一个特征的提取器,通过权重矩阵与每个类别的权重进行内积,得到分类结果。)
所以在数据不足时,我们可以使用预训练好的模型,通过调整分类头或者fine-tune来得到一个新数据的分类器
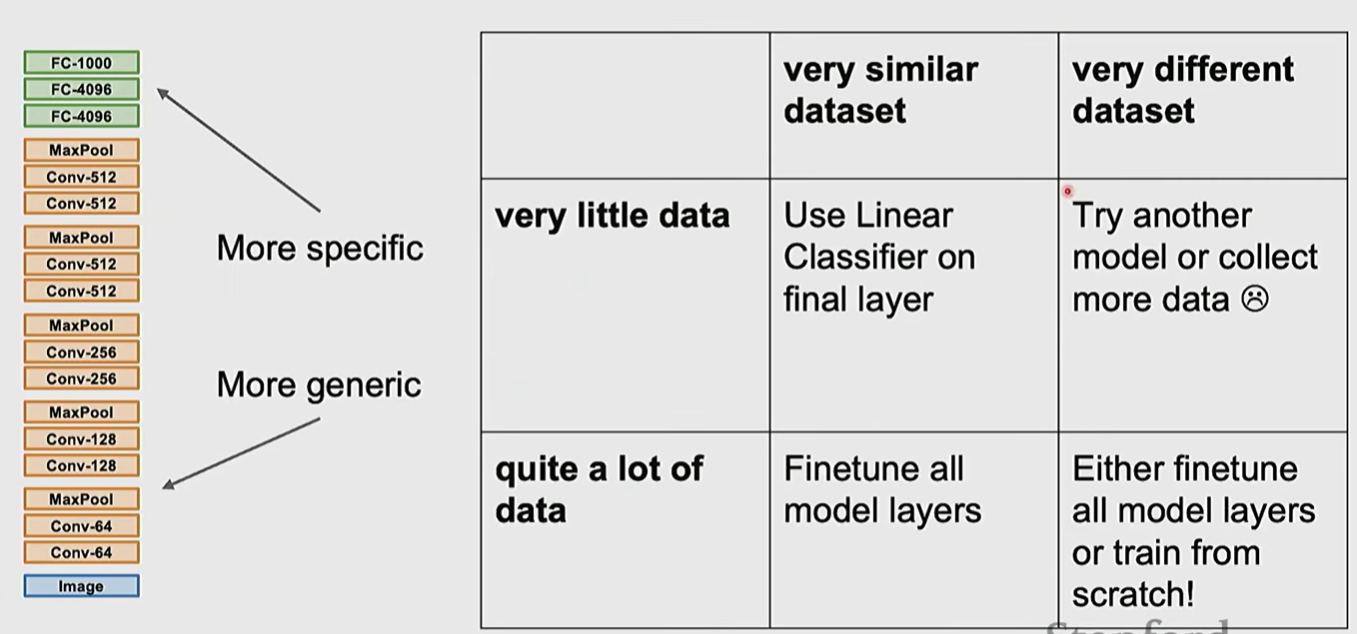
Hyperparameters
- check initial loss
- overfit a small sample(在一个小样本上过拟合,如果没办法实现,大概率是存在bug/模型不对)
- adjust LR
- Coarse grid of hyperparams,train for 1-5 epochs 粗粒度的调整超参
- refine grid, train longer 微调超参
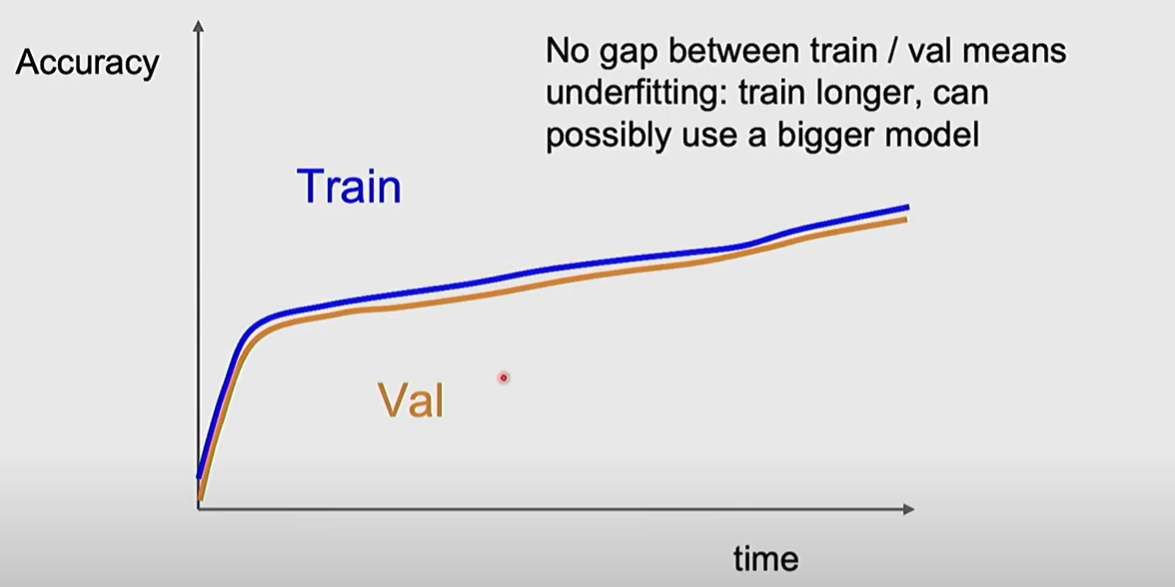
- Look at loss and accuracy curves
如果train acc 和 val acc十分接近而且不断上升,可能由于 underfitting: train longer或者bigger model
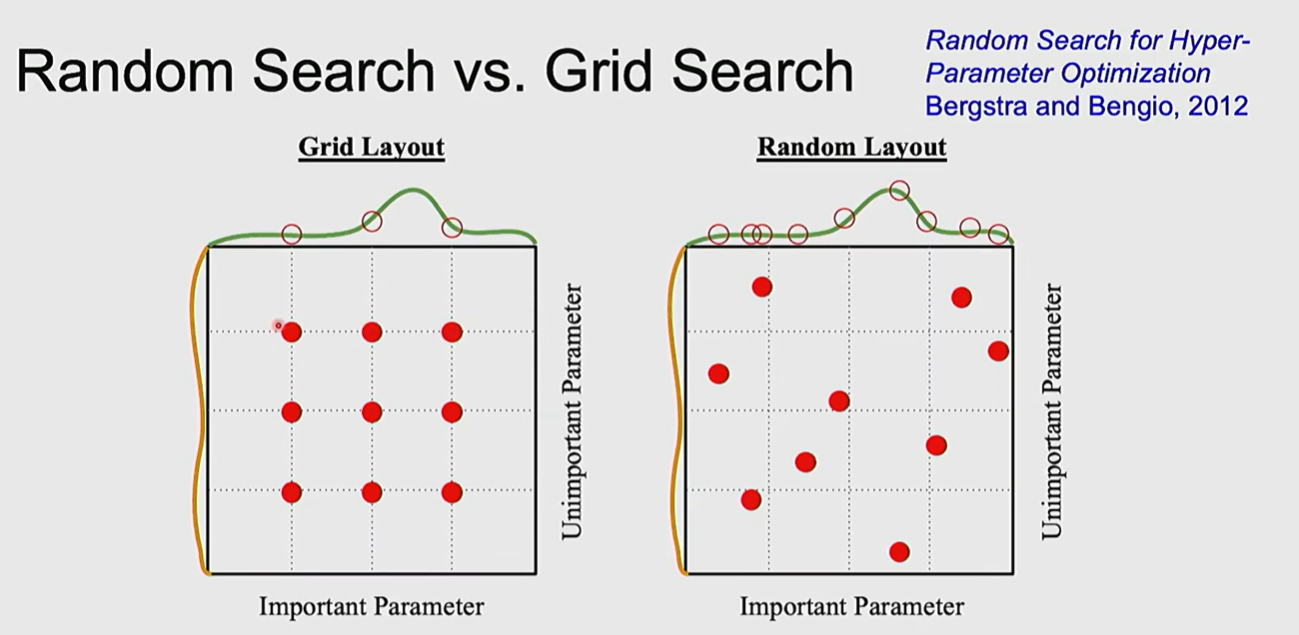
可能有时随机搜索会比规律的搜索更好
Famous Architecture
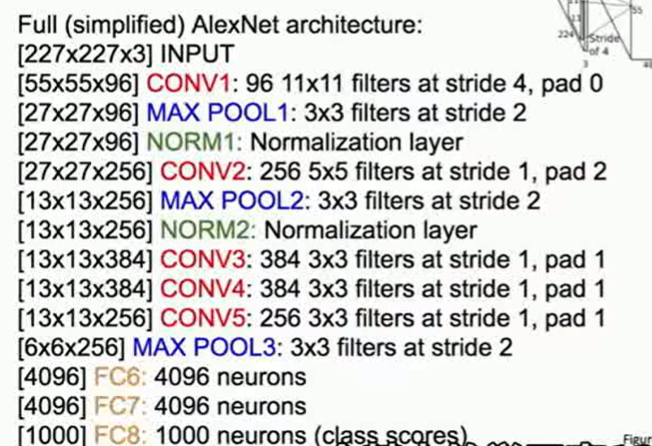
AlexNet
VGGNet

此时的结构基本是 con con pool, con con pool,最后加上三层FC
从这里的简单计算可以看到,内存占用(假设不使用重计算)主要是在一开始的convolution layer上
VGGNet 提出了 convolution
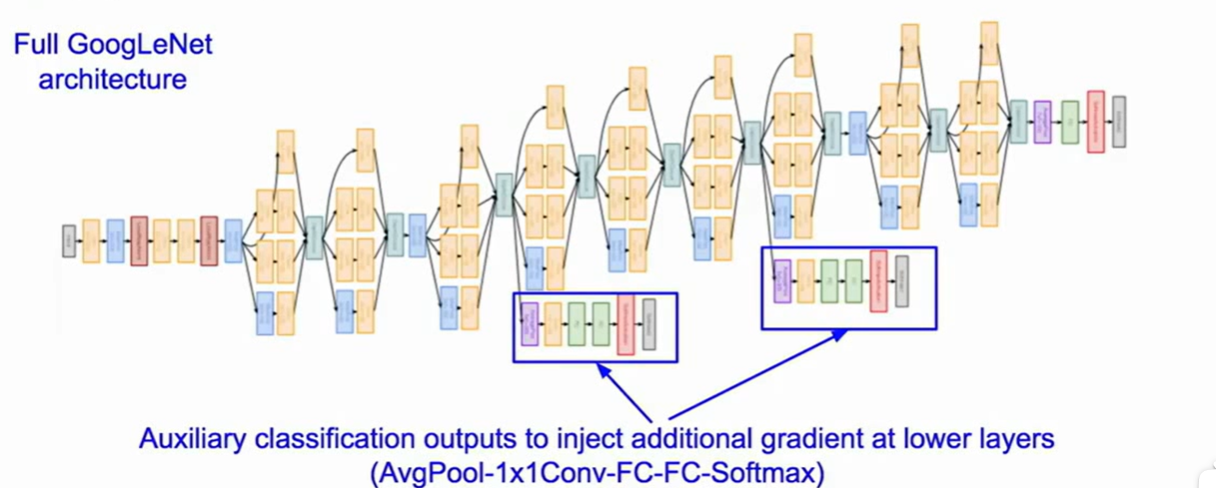
GoogleNet
inception moduel + no FC layer
inception module是在同一层进行多种卷积和pool运算,将得到的结果在channel层面结合作为下一层的输出
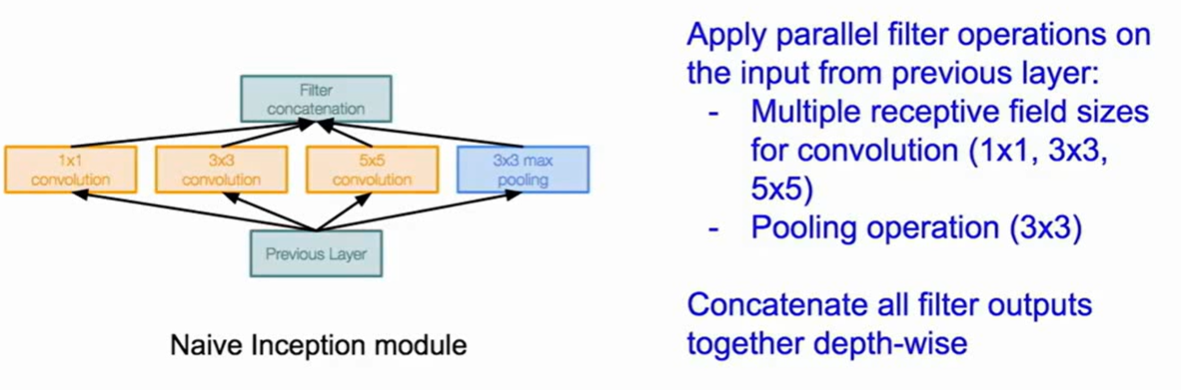
这样每一种操作都必须保证输出的feature map是一致的
多种运算产生了较大的计算开销,同时多个结果的堆叠会产生特别深的feature map(多个inception运算之后)
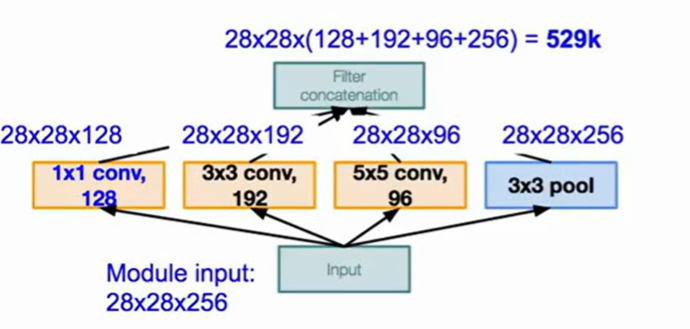
GoogleNet的做法是引入bottleneck 也就是 的convolution layer,bottleneck能将feature map投影到一个相同大小但是更浅的feature map中,在这里使得计算量大量减少
具体做法为
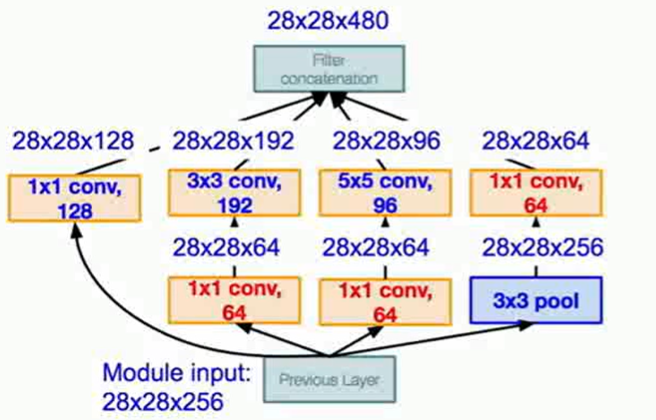
整体的结构是 vallina 架构,加上多层inception,然后是不使用FC的分类头。在模型中间甚至加上了两个也计算损失的输出,用于优化梯度更新
only google can do
ResNet
ResNet的结构是 多个residual block,每个block是两个的convolution layer加上residual connection
在最后没有FC,只有一个FC用于分类
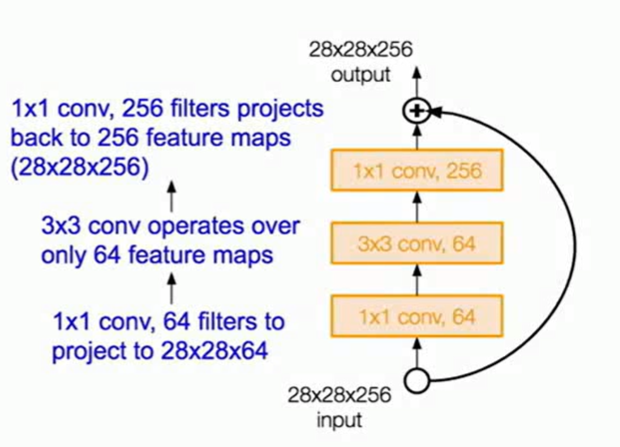
当scale up 更深的情况时,ResNet使用了bottleneck的结构
Others
He kaiming后续优化了ResNet的residual block的结构
ResNeXt将重点放在宽度上,每个residual block改成多个并行卷积层
DenseNet则是给每个层都进行了residual connection