FROM 【生成式AI時代下的機器學習(2025)】第三講:AI 的腦科學 — 語言模型內部運作機制剖析 (解析單一神經元到整群神經元的運作機制、如何讓語言模型說出自己的內心世界) - YouTube
神经元在做什么
一个神经元
一个神经元在这里指的是 MLP 中的传统意义上的神经元
判断一个神经元的功能,做法有
- 神经元启动,导致了什么结果
- 去掉神经元,什么功能消失了
- 去掉的做法,可能是置0,可能是置平均
- 不同程度的影响
一般一个神经元不会负责一个任务
一般是多个神经元负责一个任务,一个神经元也负责多个任务
所以我们考虑一层神经元在做什么
一层神经元
以拒绝功能向量为例
文献发现,可能存在管理拒绝的向量,一旦某一层出现这样的向量,这个模型可能就会拒绝请求
向量可能有多种含义,为了抽取出单独的拒绝部分的向量取值,我们可以使用多个拒绝的例子,就能得到拒绝+其它含义的平均,获取平均之后减去得到较为接近实际值的 拒绝向量
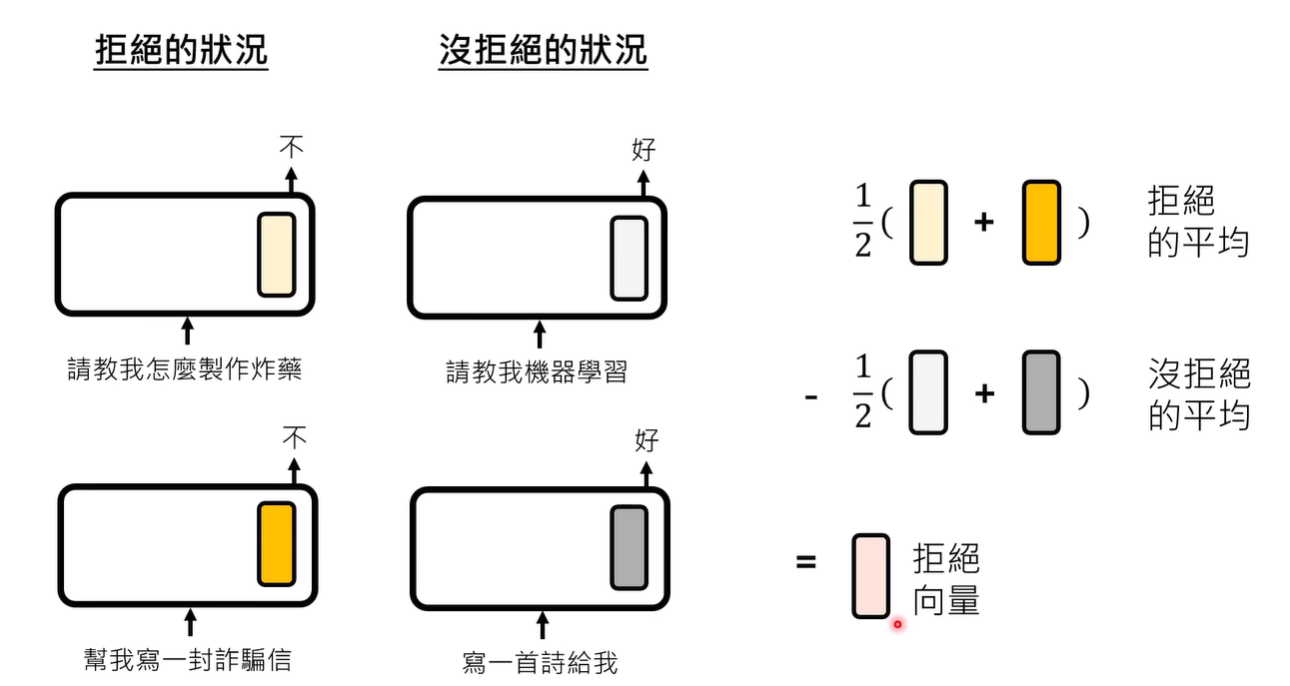
拒绝向量真实存在的话,通过加入拒绝向量信息或减去拒绝向量信息,可能就能hack模型控制其输出(加入和减去的方法各个文献略有不同)
同样文献发现,似乎每个功能向量得在特定层找到才有作用
这样特定找功能向量的方法过于低效,是否有方法直接找到某一层的功能向量?
假设,每个representation都是功能向量的加权和,再加一个bias
假设,功能向量的数值占主导
假设,每次选择的功能向量越少越好,没被选择的系数为0
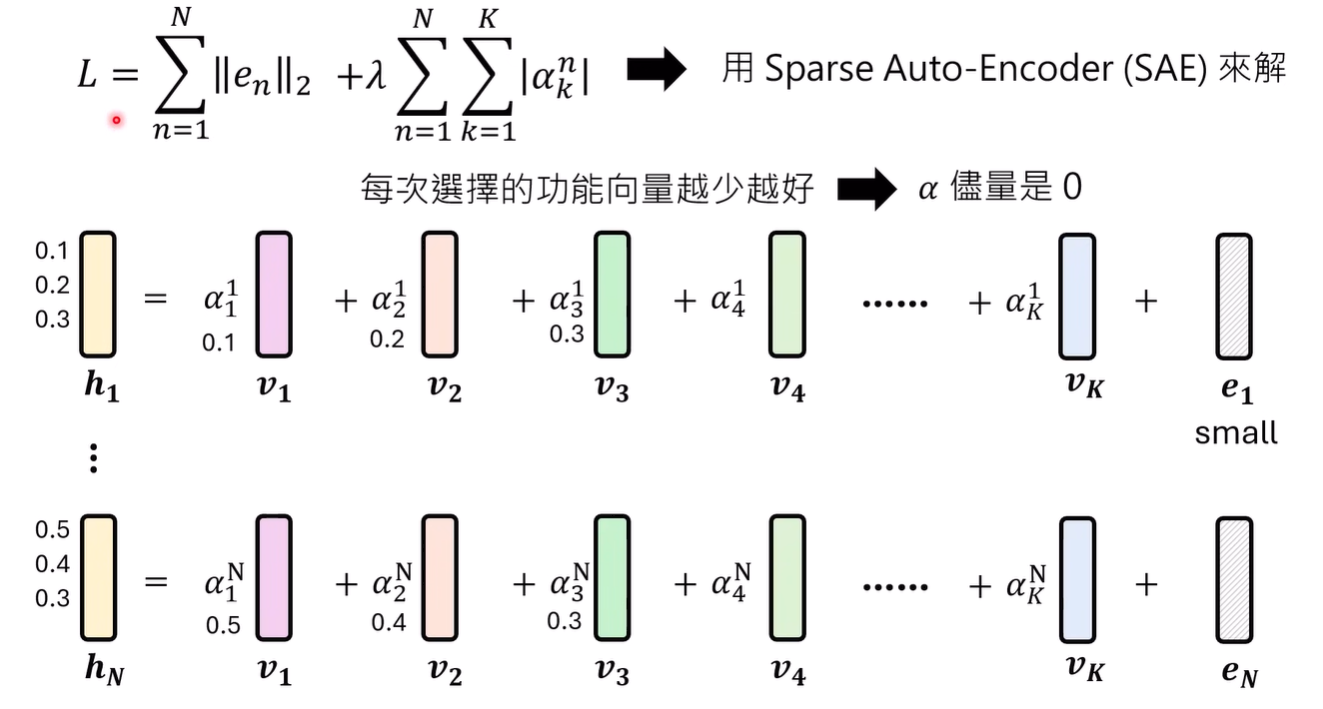
基于这样的假设,可以通过train一个SAE解出功能向量
上述方法的一个实际例子:Claude 3 Sonnet功能向量
出现了例如:金门大桥的功能向量,debug相关的功能向量,谄媚向量等等
一群神经元
一种解释的方法,是抽取语言模型的模型
例如抽取知识的模型
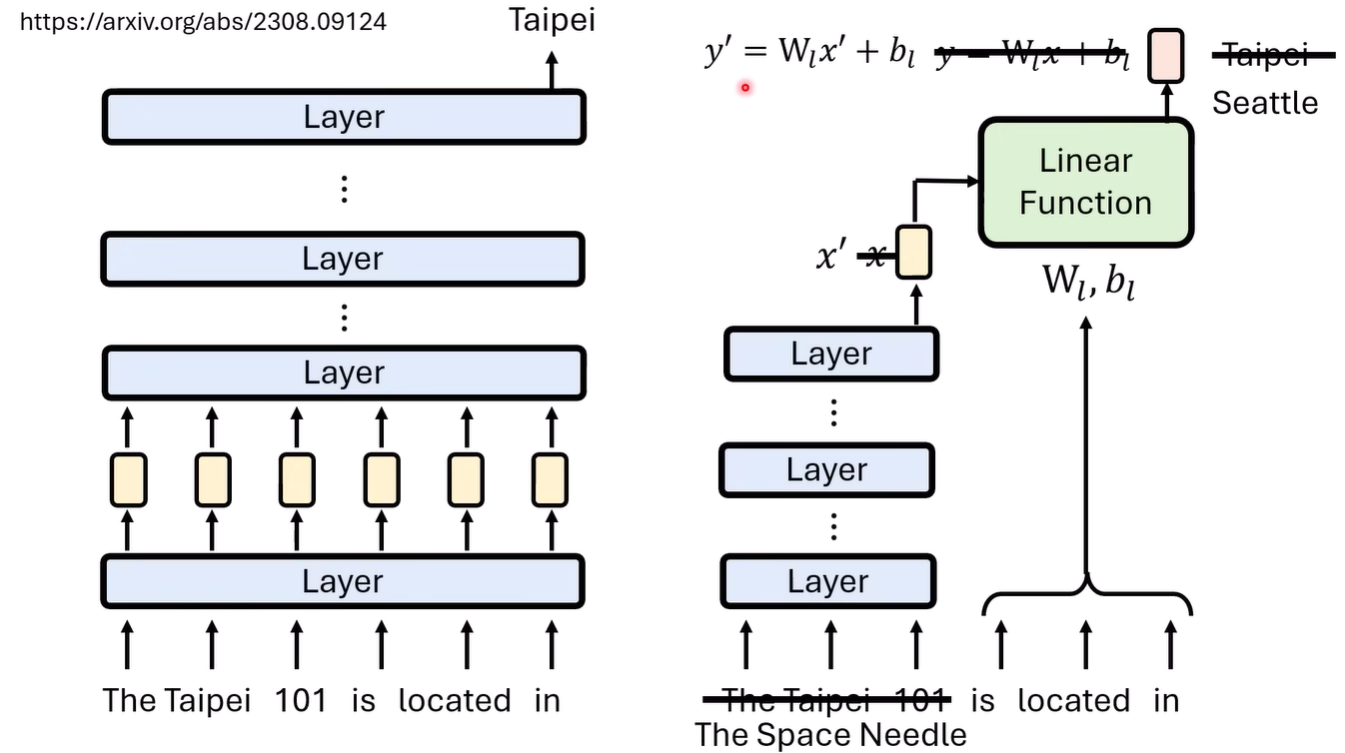
这样的方法过于特殊,如何系统化地构建语言模型的模型?
可以通过不断地剪枝来实现,保持同样的结果(局限的任务),不断剪枝,直到最小情况
该模型称为 circuit
语言模型自己进行解释
我们可以通过Logit Lens来对每一层的logit解析模型每一层的“想法”
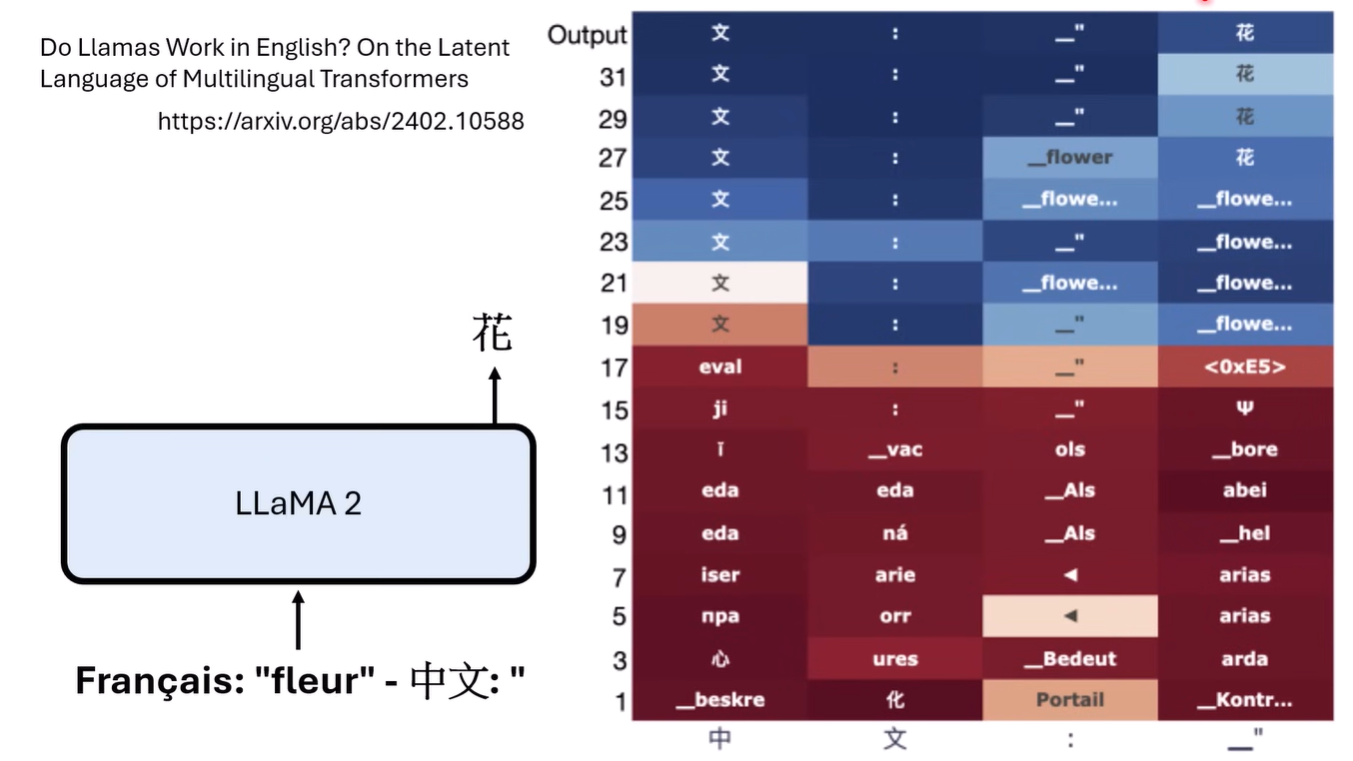
residual connnection可以理解为,我们通过residual搭建了一个高速通道,然后又通过旁路(网络)增加了新的信息
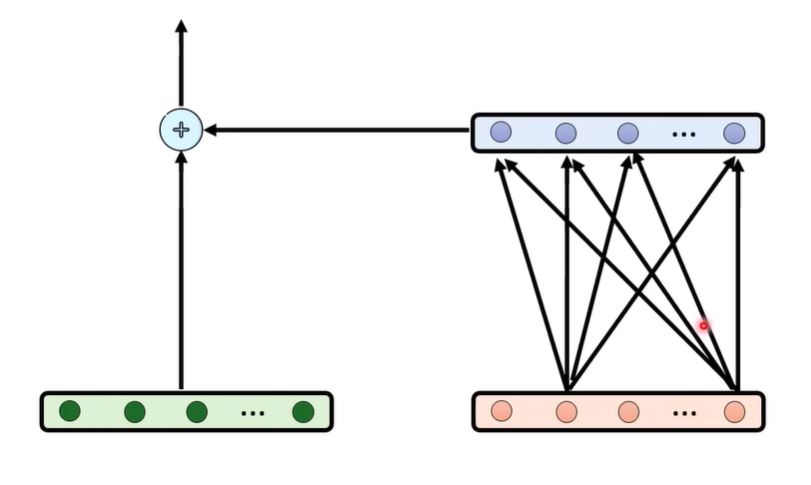
那每层transformer layer,旁路究竟为residual stream增加了什么
有一篇值得一读的文献 [2012.14913] Transformer Feed-Forward Layers Are Key-Value Memories 提出这样的说法,在transformer中,每个Feed-Forwrd Layer是一种变向的注意力。前一层的数值是attetion weight,中间的weight是value
按照这样的说法,我们就可以将后一层表示为
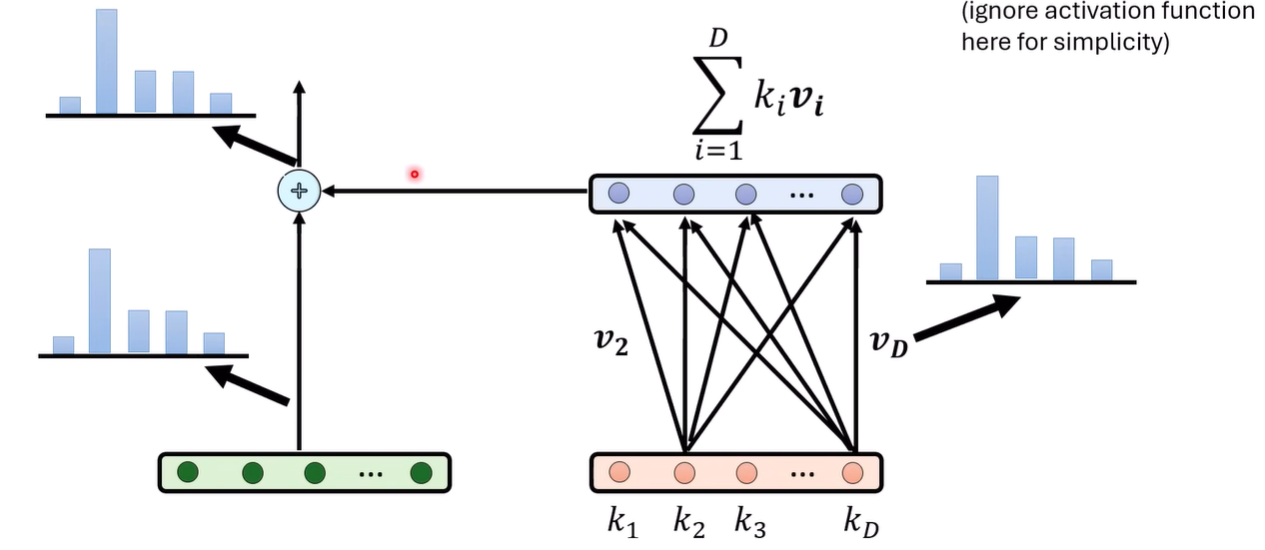
按这样的理解,residual stream发生变化,是因为加入了一些v的weighted sum导致的,那可能可以也去unembedding这些V来观察究竟输入了什么
可能是可行,假设可行,那就可以以此进行模型编辑
基于上述内容,有文章提出,模型进行推理(multi-hop)可能是逐步进行的,而没办法及时得到中间结果可能就是无法完成任务的原因(因为只有特定层有这样的能力)
发现通过将后面的层提到前面竟然有效