Stable Diffusion
Diffusion Model Review
一个不错的概括
In a nutshell, Diffusion Models work by corrupting training data through the addition of Gaussian noise (called forward diffusion process), and then learning how to recover the original information by reversing this noising process step by step (called reverse diffusion process).
-
马尔可夫链的假设使得我们能公式化forward pass的过程,并得到从 到任意一步的加噪图片
-
原始的DDPM论文中,作者使用一个linear scheduler 来决定噪声的变化情况, 线性增加( ),后来的论文提出了改进,使用 cosine scheduler
- 线性的schedule 加噪速度过快,可能后面的加噪只是将一张纯噪声转化为另一张纯噪声,这样在训练上是浪费时间的,cosine schedule 减慢了加噪速度
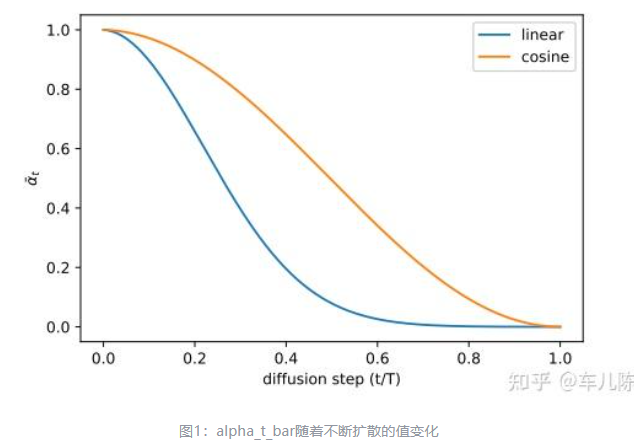
- 更多见 Cosine-Beta Schedule for Denoising Diffusion Models | Zain Nasir Improved Denoising Diffusion Probabilistic Models-知乎
-
Diffusion 模型预测的是 加在当前图片上的噪声原始的样子,即进行对应步数处理之前,从高斯分布中sample出来的噪声。无论是训练还是生成,只是生成通过数学推导得到前一步图像与这个噪声的关系(实验上这样的结果比较好而不是直接算出当前步数噪声得到原始图片)
-
关于Diffusion 模型内部的设计
- DDPM 是一个类似于U-net的架构
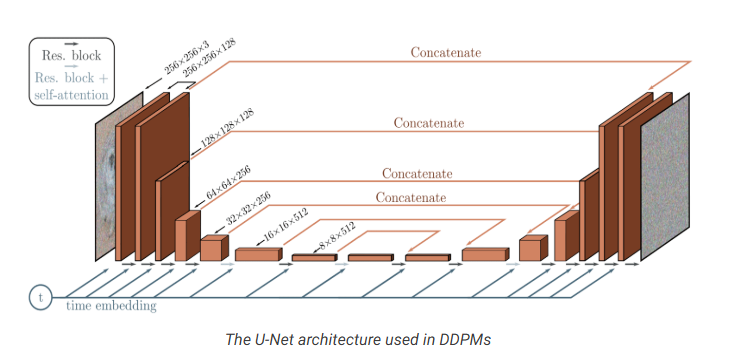
- 详见 DDPM
- 大概的话是
- encoder decoder,相同层数,中间有一个bottle neck来连接
- 每一层encoder包含两个Residual blocks,卷积,两倍下降
- 每一层decoder包含三个Residual blocks,x2 upsampling,恢复大小
- encoder和decoder对应阶段使用跳连连接
- 某些特征图(中间分辨率)feature map使用attention
- 编码时间得到time embedding,加入到各层中
关于损失函数
我们的目标是最大化 生成 x 的概率 ,而在最大化 的时候会遇到一个贝叶斯模型中不可解的概率分布,即
Note
由于我是废物所以我得补充一下
实际上是全概率公式的连续形式,也就是通过积分消去隐变量z
这里后面的积分实际上意义不大,处理这样的问题有一个技巧,就是引入 ELBO(Evidence Lower Bound)(或叫 VLB Variational Lower Bound)
引入一个简单的分布,等式成立与分布无关
利用贝叶斯公式写成可拆分的形式,引入一项 用于化简
拆分得到
发现第二项是KL divergence
KL divergence 一定大于0,所以 一定满足
这一项可以转化为一个均值
这个均值就是lowerbound
由于 是固定的,所以如果我们最大化这个ELBO,我们就会更接近于真实分布
这是一种 Variational Inference(VI),在diffusion,VAE,Bayesian Neural Networks中很常见
Diffusion 的损失为
Diffusion中的这个VLB可以进一步reformulate为KL distance和entropy 项。
更详细的推导见 Diffusion
Training Process
文字的描述是
- 为每一个batch的图片随机sample 一个时间步
- 为图片加上 close form formula 计算得到的噪声
- 将时间步转化为 time embedding(DDPM中time embedding加入到各个U-Net block中,其它模型可能不同)
- 预测噪声
- 计算损失
- 更新参数
相同的图片可能会在随机时间步的sample中得到不同的噪声,模型能够学会不同时间步下的去噪,增加了模型的适用性

Sampling Process
输入一个随机sample的高斯噪声和从T到0的时间步,模型预测每个时间步的噪声并从照片中减去
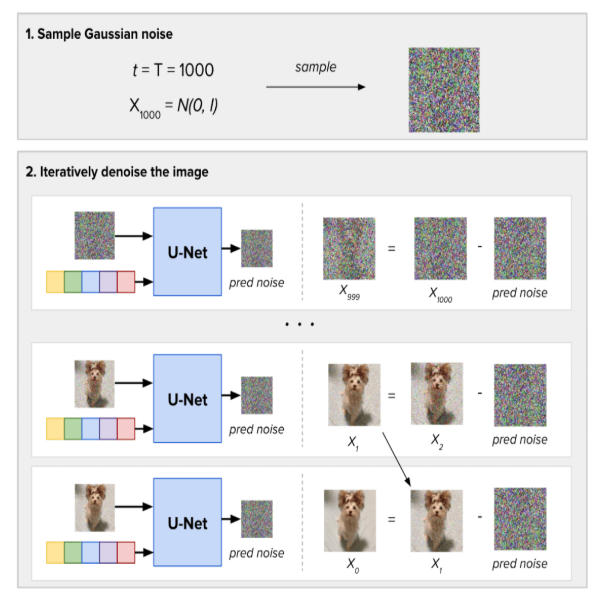
Stable Diffusion
Latent Diffusion Model(LDM) 优化了DDPM的结构,将原本pixel space进行的图片操作转移到latent space上,处理的图片变小,提高了计算效率
图片的encoder E 和 decoder D可以通过训练 Variational AutoEncoder 的变体实现
注意:forward diffusion process 和 reverse diffusion process 都在 latent space中
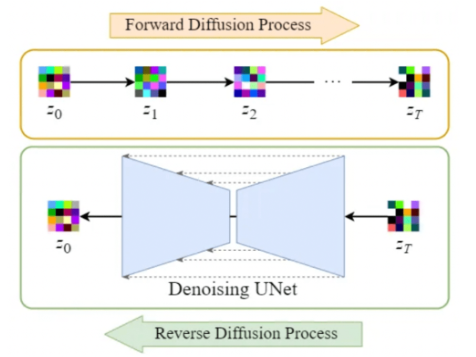
将diffusion process移入 latent space,实际上加快了模型的sample和denoising过程,可以把 LDM 看成是一种加速方法
Conditioning
Stable Diffusion 是 CFG/CFDM(Classifier-Free)
它能根据各种形式的输入(conditioning unputs, text, images…)来得到条件化的输出
具体是如何实现的?
SD将condition进行encode之后,与U-Net架构进行交叉注意力运算
- Text input: 通过BERT/CLIP等模型,编码为embedding,进入注意力块的运算
- Other conditioning:image,semantic map等通常是接到输入上进入U-Net
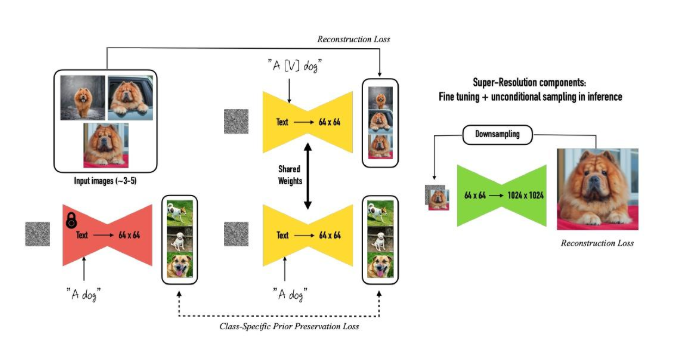
DreamBooth
DreamBooth 是一种个性化文生图算法
它希望将特定主题的物体与一个独特标识符绑定,模型微调后通过独特标识符的prompt就可以生成该主题物体的新图片
为此论文设计了一种prompt格式 a [identifier] [class noun]
其中
- identifier 是与输入图片物体绑定的特殊标识符
- class noun 是目标类别,加入类别的目的是为了使用模型的先验知识将指定物体与模型对该物体的认识相融合,来实现不同场景下不同姿势物体的生成
如何选择特殊标识符
- 如果使用已存在的单词,可能让模型丢失关于原单词的语义理解,同时也可能因为先验的理解而影响效果
- 如果随便构造,分词器可能会将这个单词拆分,导致与上述一样的情况
- 使用词表中的罕见词会是一个比较合适的做法,例如
TOK
DreamBooth 希望通过少量的图片进行微调,在微调得到特定物体的理解的同时,不丢失原先的模型能力
普通微调的方法可能出现 过拟合,分布漂移(忘记通用能力,仅适配特定任务)等问题
为了保持原有能力,论文提出一个新的损失
其中 是新设计的prompt输入, 是去调特殊标识符的prompt,第一部分学习特定物体的生成,第二部分维持原能力,通过简单的加权和权衡
History
Stable Diffusion
Stabel Diffusion 的演变更多是 sacling up的过程,随着text encoder和U-Net 参数量和训练数据的增大,模型能力逐渐增强
从细节上看的话
- Stable Diffusion v1 系列
- 从SD 1.1 开始,没有1.0,Latent Diffusion 的原创性存在争议
- 使用预训练的CLIP模型
- 从第一代开始没有太多的变化,在前面的基础上微调
- SD 1.5 为代表作,生态丰富
- Stable Diffusion 2 系列
- 2.0 相比 1系列scale up,2.2对2.1 fine-tune
- 分辨率上升 (768x768)
- 重新训练了更大的 CLIP,支持图像放大,引入了depth2img(输入图像提取灰度图(相当于基本构图),进行图生图)
- 并不受社区欢迎,效果一般但是规模大
- Stable Diffusion XL
- SD XL,1024x1024,支持LoRA,ControlNet
- 再次 scale up
- SD XL 分为 Base 和 refiner 两部分,由Base 生成最终图像的 latent representation 然后由 refiner 进行调整,但是实际不见得加上refiner效果更好
- 加入了 图片的大小和位置编码(傅里叶编码,加到time embedding上)
- 多宽高比训练策略,按不同宽高比分桶,提高泛化性
- 重新训练了VAE解码器
- Stable Diffusion 3
- 引入DiT,text encoder为T5+CLIP
DALL-E & Imagen
-
DALL-E2
- CLIP得到 text embedding,Diffusion得到image embedding,然后decoder生成图像 (unCLIP)
-
DALL-E3
- GPT集成,Image captioner生成图像描述(实验发现长描述更好),使用Transformer架构模型作为text encoder
- 没有太多创新,主要是 caption 的生成
-
Imagen
- Imagen 2 是 T5 作为text encoder,通过diffusion生成图像,通过super-resolution pipeline放大图像
- Imagen 2是pixel space
- Imagen 3虽然放出来了,但是好像没有模型细节的技术报告
- Imagen 2 是 T5 作为text encoder,通过diffusion生成图像,通过super-resolution pipeline放大图像