PCA
A notes from Deep Learning Foundations and Concepts (Christopher M. Bishop, Hugh Bishop)
Principal component analysis, or PCA, is widely used for applications such as dimensionality reduction, lossy data compression, feature extraction, and data visualization. It is also known as the Kosambi–Karhunen–Loeve transform.
PCA can be defined as the linear proejction that maximizes the variance of the projecrted data, or it can be defined as the linear projection that minimizes the average projection cost(hte mean squared distance between the data points and their projections)
Given a dataset, PCA seeks a space of lower dimensionality(known as principal subspace) that satisfies the definitions above.
Maximum variance formulation
Consider a data set of observations where , and is a variable with dimensionality D.
Our goal is to project the data onto a space having demensionality , while maximizing the variance after projected
assume that is given
When , we can define the direction of the space using a -dimensional vector , and without loss of generality, we choose that satisfies
then projection of will be
the mean of the procjected data is
the variance will be
where is the data covariance matrix
And then maximize the projected variance
To prevent , A appropriate constraint comes from the normalization condition
Introduce a Lagrange multiplier denoted by
then the formula becomes
Setting the derivative with respect to equal to zero, there is a stationary point when
It says that must be an eigenvector of . If left-multiply by , and with the condition
the variance will be
Maximizing the variance becomes choosing the eigonvector that has the largest eigonvalue . This eigonvector is kown as the first principal component
We can then define additional principal components in an incremental fashion(增量) by choosing each new direction to be that which maximizes the projected variance amongst all possible directions orthogonal to those already considered. (取所有与当前选择的方向正交的最大化方差的方向)
In the case of -dimensional projection space, the optimal solution would be the eigonvectors of the covariance matrix that have the largest eigenvalues
总结来说,找到维的投影空间,先计算均值,以均值计算协方差矩阵,求解协方差矩阵的个最大特征值对应的特征向量。
Minimum-error formulation
Introduce a complete orthonormal set of D-dimensional basis vectors where that satisfy
each dataset can be represented exactly by a linear combination of the basis vectors
It can be regarded as a rotation of the coordinate system to a new system defined by the
Taking the inner product with , we can obtain
and since orthonormality
we can obtain , and sothat we can write
However, we use D-dimentional space for the expression, our goal is to represent the data in subspace.
We can approximate the data by
where the depend on the particular data point, and are constants
We are free to choose , the and the so as to minimize the projection error(Introduce by reduction in dimensionality)
The error can be defined as
Substituting into all formula, setting the derivative with respect to to zero, and making use of the orthonormality conditions, we obtain
And respect to to zero, we obtain
where
Substitute for and , the difference between data and projection becomes
We can see the minimum error is given by the orthogonal projection
We therefore obtain the error purely of the in the form
Aim to avoid , we must add a constraint to the minimization
For a intuition about the result, let’s consider a case that , and
By adding Lagrange multiplier , we minimize
It is the same as the maximum variance process, we just obtain the minimum instead
By setting the derivative with respect to to zero, we obtain
back-subtitude it into , we obtain
With the goal to minimize , we choose the smaller eigonvalue, and therefore we choose the eigonvector corresponding to the larger eigonvalue as the principal subspace
The general solution is
And is given by
We choose the smallest eigenvalues, adn hence the eigenvectors defining the principal subspace are those corresponding to the largest eigenvalues.
PLSR
notes for 16 Partial Least Squares Regression | All Models Are Wrong: Concepts of Statistical Learning
Initially, I wanted to learn about Partial Least Squares, but I found that it might be too broad or challenging. So just start from PLSR first
PLS method has a big family, and PLSR may be a friendly one
PLSR is another dimension reduction method to regularize a model, like PCR, PLSR seek subspace describe by (or linear combinations of )
Moreover, there is an implicit assumption: and are assumed to be functions of a reduced number of components that can be used to decompose them
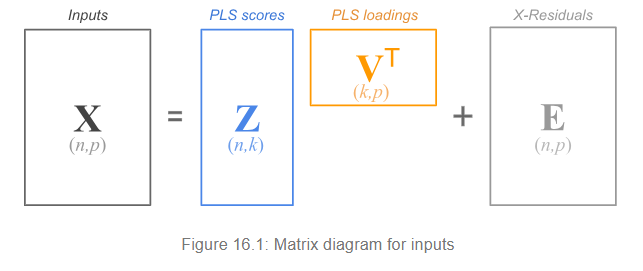
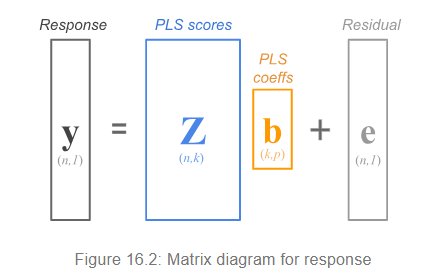
So the model in the -space is
and y becomes
But How to get the components
Assume that both the inputs and the response are mean-centered(and possibly standardized). Compute the covariances between all the inputs variables and the reponse:
In vector-matrix notation
In fact, the notations above are not the same.
The matrix notation larger than the covariance
But we care about the direction only, and their direction will be the same if inputs and response are mean-centered(their mean is 0)
so it doesn’t matter
and we can also rescaled by regressing each predictor onto
and then normalize
We use these weights to compute the first component
since is unit-vector, the fomula can be expressed like
Then we use the component to regress inputs onto it to obtain the first PLS loading
regress response onto it to obtain the first PLS coeffs
And thus we have a first one-rank approximation
Then we can obtain the rasidual matrix (named deflation)
deflate the response
This is the first round, and we can obtain k components by repeating the process k times, iteratively
every time we reduce the rasidual by obtain the approximation of the previous rasidual matrix and the target
the effect of these approximation are synthesized by matrix multiply
个人认为,这么做的目的是通过回归的方式来拟合,得到降维子空间的同时减小产生的误差(每次都是拟合误差),这些拟合的结果最终出现在矩阵中(开头的式子),效果被综合
What PLS is doing is calculating all the different ingredients (e.g. , ) separately, using least squares regressions. Hence the reason for its name partial least squares.
References
PCA
PLSR
- 16 Partial Least Squares Regression | All Models Are Wrong: Concepts of Statistical Learning
- Partial least squares regression - Wikipedia
Difference
Not yet